

2020 年初,Cloudera Hadoop 大神 Arun 在 Twitter 上宣布 Cloudera Data Platform 正式集成了 Flink 作为其流计算产品,意味着 Cloudera 的全球客户都将能够使用 Flink 进行流数据处理。那么,被认为是 Storm 最佳替代的 Apache Flink,哪些出众的能力受到了大数据独角兽 Cloudera 的青睐?Cloudera 与 Apache Flink 的结合能给企业及开发者带来哪些体验提升?
什么是 Apache Flink?
Flink 诞生于欧洲的一个大数据研究项目 StratoSphere。该项目是柏林工业大学的一个研究性项目。早期,Flink 是做 Batch 计算的,但是在 2014 年,StratoSphere 里面的核心成员孵化出 Flink,同年将 Flink 捐赠 Apache,并在后来成为 Apache 的顶级大数据项目,同时 Flink 计算的主流方向被定位为 Streaming,即用流式计算来做所有大数据的计算。
具体来说,Apache Flink 是一个解决实时数据处理的计算框架,但不是数据仓库的服务,其可对有限数据流和无限数据流进行有状态计算,并可部署在各种集群环境,对各种大小的数据规模进行快速计算。
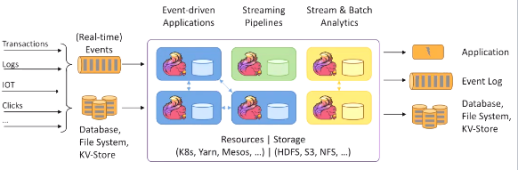
如上图所示 Flink 框架,大致可以分为三块内容,从左到右依次为:数据输入、Flink 数据处理、数据输出。
Flink 支持消息队列的 Events(支持实时的事件)的输入,上游源源不断产生数据放入消息队列,Flink 不断消费、处理消息队列中的数据,处理完成之后数据写入下游系统,这个过程是不断持续的进行。
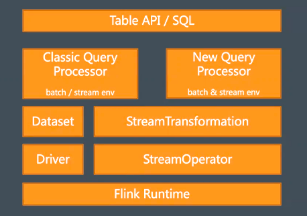
在 API 层面,Flink 具备较好的层级组。但是不论是通过 SQL 的 API 还是 Table 的 API 还是 DataStream 的 API,其最终都会被转换成 Stream Operator 然后放在 flink Runtime 的框架下去执行,即转换成一个各种 Operator 串联在一起的 Flink 应用程序。只是上层的 API 在尝试做 Flink 程序时,会有各种不同的角度,从各方面写出所想要达到效果的应用程序。
新一代分布式流式数据处理框架
Flink 是一套集高吞吐、低延迟、有状态三者于一身的分布式流式数据处理框架。
众所周知,非常成熟的计算框架 Apache Spark 也只能兼顾高吞吐和高性能特性,在 Spark Streaming 流式计算中无法做到低延迟保障;而 Apache Storm 只能支持低延迟和高性能特性,但是无法满足高吞吐的要求。而对于满足高吞吐,低延迟,有状态这三个目标对分布式流式计算框架是非常重要的。
高吞吐
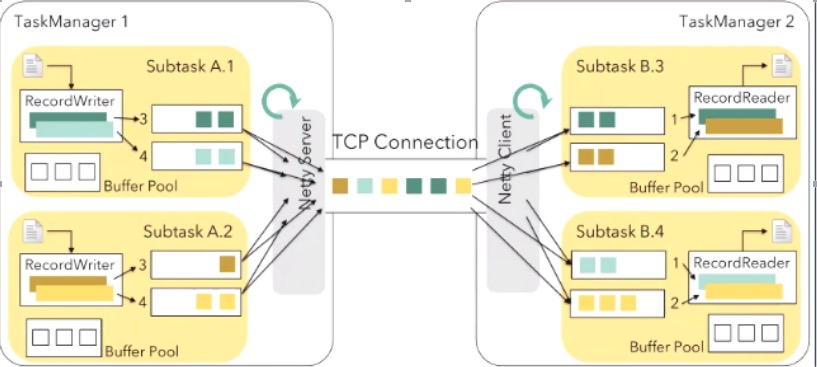
如上图所示,相比于 Storm 或其他的框架,Flink 网络模型还是相对来说比较高效的,每一个 Flink TaskManager 下会有很多个 Subtask。与其他方案设计不同的是,Subtask 会共享一个 TaskManager 的服务,通过一个 TCP Connection 与其它 TaskManager 通信,通信则是由 TaskManager 内设的 Netty 服务器完成。
需要注意的是,默认的情况下事件的数据并不是完成了一条就发送一条,而是从每一个 Subtask 的 Buffer Pool 中获取一个缓冲块,由 RecordWriter 写到缓冲块中,等到这个缓冲块写满了,再通知 Netty 发送队列到其他的 TaskManager。这样既可以很好保证了每一个 TCP 包被尽可能的利用,又减少了不必要网络包的数量。
低延时
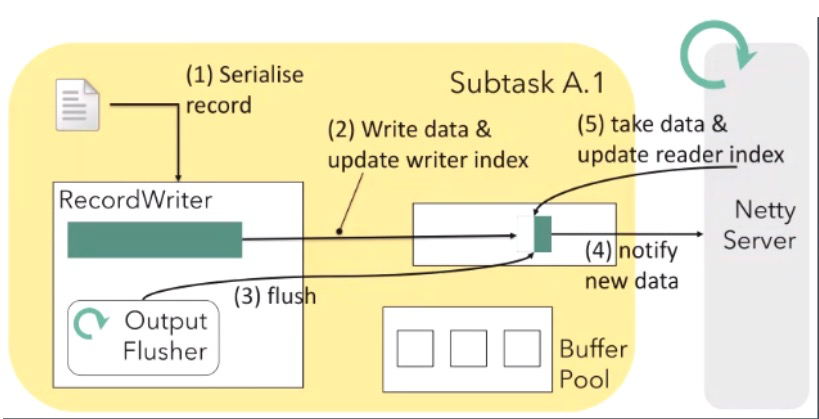
从技术本身的底层特性上说,Flink 引入了 Buffer Pool 和 Buffer 块的概念。在大流量时,由于 Buffer 区很快就会被写满,紧接着会通知 Netty 尽可能地发送,因此不会看到太多的延迟。但在低流量时,可能几秒钟才会有一条数据,这就意味着 Buffer pool 有很长时间没有被强制写满,因此为了保证下游系统尽可能尽快得到上游的消息,就需要有一个强制的刷新或往下游推送的触发器机制。
Flink 本身则具备这样的一个机制,它可以尽可能地保证 Buffer 还没有写满时,就可提前去通知 Netty 服务器,尽快把当前 Buffer 块里面的数据发送下去,并可以通过 BufferTimeout 的参数设置,控制 Flink 在低流量时的系统最大延迟。
Buffertimeout 包含-1、0、x ms 的配法。比较特殊的是-1 和 0,当把参数设为-1 时,Flink 的用户会忽略 Flusher 的通知,往下的发送必须要由 RecordWriter 完成,也就是默认了这个缓冲写满了往下发。这样的情况下虽然每一次通信的效率是高效的,但是在低流量时若接受就会出现大量的不可预测的系统延迟。
当把参数设为 0 时,意味着 Flink 每写一条数据就会通知 Netty 尽可能的发送,即系统达到了技术理论上的最低延迟。因此,当你对延迟特别敏感流量又不是很高时,可以考虑将 Buffertimeout 设为 0。
正常情况下会将 Buffertimeout 设为某个正值,也就是多少个毫秒。这时 Flink 每间隔一段时间通知 Netty,Netty 不管这个数据有没有写完或者有没有写满,都尽可能发送。
这样通过这两个参数,也就是缓冲区大小及多长时间强制发送,就可以在延迟和吞吐之间形成一种维度的控制,并可以在低延迟或者是高吞吐这两个方向上做一些控制,既能保证高吞吐,又能保证低延迟。
有状态
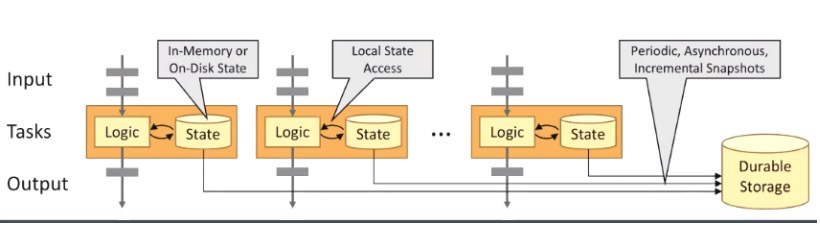
由于 Flink 是一个实时计算的框架,因此 Flink 的状态实际上是最核心的技术资产,涉及到了频繁的写入与读取,并需要用很快的存储方案存储该状态。Flink 提供了三种状态的存储模式,分别是内存模式、文件模式和 Rocks DB 的模式。
内存模式:使用这种方式,Flink 会将状态维护在 Java 堆上。众所周知,内存的访问读写速度最快;其缺点也显而易见,单台机器的内存空间有限,不适合存储大数据量的状态信息。一般在本地开发调试时或者状态非常小的应用场景下使用内存这种方式。
文件模式:当选择使用文件系统作为后端时,正在计算的数据会被暂存在 TaskManager 的内存中。Checkpoint 时,此后端会将状态快照写入配置的文件系统中,同时会在 JobManager 的内存中或者在 Zookeeper 中(高可用情况)存储极少的元数据。文件系统后端适用于处理大状态,长窗口,或大键值状态的任务。
RocksDB:RocksDB 是一种嵌入式键值数据库。使用 RocksDB 作为后端时,Flink 会将实时处理中的数据使用 RocksDB 存储在本地磁盘上。Checkpoint 时,整个 RocksDB 数据库会被存储到配置的文件系统中,同时 Flink 会将极少的元数据存储在 JobManager 的内存中,或者在 Zookeeper 中(高可用情况)。RocksDB 支持增量 Checkpoint,即只对修改的数据做备份,因此非常适合超大状态的场景。
三大场景,实时处理不在话下
Flink 的应用场景一般看到三大类,分别是流式的 ETL,实时的数据分析以及事件驱动型应用的改造。
流式 ETL
传统的 ETL 的任务一般是定时出发完成读取数据,把结果写到某一个数据库或者文件系统中,通过周期性地调用 ETL 脚本完成批处理的作业。但是当有流式 ETL 的能力时,就不再需要定时出发的方式完成 ETL 的任务,而是在数据到达之后马上开始 ETL 的处理。遇到意外的情况也可通过画面机制从上一个出发点恢复再继续执行任务。
实时的数据分析
Apache Flink 同时支持流式及批量分析应用。
Flink 为持续流式分析和批量分析都提供了良好的支持。具体而言,它内置了一个符合 ANSI 标准的 SQL 接口,将批、流查询的语义统一起来。无论是在记录事件的静态数据集上还是实时事件流上,相同 SQL 查询都会得到一致的结果。
但是有一点不可避免的是,由于实时分析系统面对的是非闭合的区间,或者是半开放的数据处理区间,因此如果要用实时的数据分析系统,就不可能保证产品结果 100%能运行,开发者只能通过一些手段来降低这种情况出现的概率,而不能完全避免像这样的情况。
事件驱动型应用
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
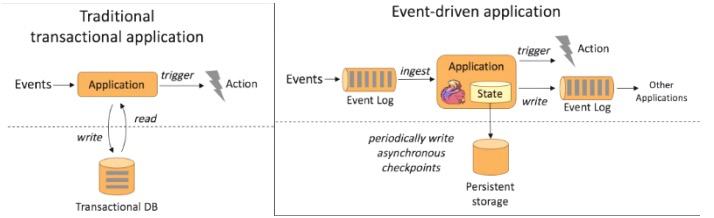
如上图所示,左边传统的事务处理应用,右边是事件驱动的处理应用。
传统的事务处理应用的点击流 Events 可以通过 Application 写入 Transaction DB(数据库),同时也可以通过 Application 从 Transaction DB 将数据读出,并进行处理,当处理结果达到一个预警值就会触发一个 Action 动作。
而事件驱动的应用处理采集的数据 Events 可以不断的放入消息队列,Flink 应用会不断 ingest(消费)消息队列中的数据,Flink 应用内部维护着一段时间的数据(state),隔一段时间会将数据持久化存储(Persistent sstorage),防止 Flink 应用死掉。Flink 应用每接受一条数据,就会处理一条数据,处理之后就会触发(trigger)一个动作(Action),同时也可以将处理结果写入外部消息队列中,其他 Flink 应用再消费。并且可以通过 checkpoint 机制保证一致性,避免意外情况。
CSA 基于 Flink ,实现 IoT 级数据流和复杂事件的实时状态处理
将 Flink 添加到 Cloudera DataFlow(CDF) 的意义十分重大,Cloudera 提供了流处理引擎的几种选择:Storm,Spark Structured Streaming 和 Kafka Stream,其中,Storm 在市场和开源社区中逐渐失宠,用户正在寻找更好的选择,而 Apache Flink 天然支持流计算(而不是批处理)可以大规模处理大量数据流,具有原生支持的容错/恢复能力,以及先进的 Window 语义,这使其成为更广泛的流处理引擎的默认选择。
由 Apache Flink 支持的 Cloudera Streaming Analytics(简称“CSA”) 是 CDF 平台内的一项新产品,可提供 IoT 级数据流和复杂事件的实时状态处理。作为 CDF 的关键支柱之一,流处理和分析对于处理来自各种数据源的数百万个数据点和复杂事件非常重要。多年来已经支持了多个流引擎,Flink 的加入,使 CDF 成为了一个可以大规模处理大量流数据的平台。
Cloudera Streaming Analytics 涵盖了 Apache Flink 的核心流功能:
在 YARN 上支持 Flink 1.9.1
支持在 Cloudera 托管集群上安装 Flink
支持完全安全(启用 TLS 和 Kerberos)的 Flink 集群
从 Kafka 或 HDFS 读取数据源
使用 Java DataStream 和 ProcessFunction API 的 pipeline 定义
恰好一次的语义
基于事件时间的语义
数据接收器写入 Kafka,HDFS 和 HBase
与 Cloudera Schema Registry 集成以进行模式管理以及流事件的序列化/反序列化
如何使用 Cloudera CSA?
Cloudera CSA 的下载与使用 Cloudera Manager 安装服务没有太大的区别,在签署订阅协议后会获得下载链接,可以直接刷到 Parcels 包。Parcels 装好之后就可以装 Flink 了,装好之后可以看到 History Server 和 Gateway 的服务。打开 History Server 的 Web UI 就显示出 Flink 业务运行的监控面板,代表了 CSA 安装完毕。
接下来就是采用一些标准的开发包,开始第一个 Flink 工程。首先获取运行环境,加载或者读取数据,再编写 Transformations,添加数据输出目标系统,最后执行这个应用。
不止于此,Apache Flink 与 CSA 正在探索更多的可能性
目前 Flink 已经成为一个主流的流计算引擎,社区下一步很重要的工作是对 Flink 做一个大的整合,面向流和批去做一个统一的数据处理模型。在 1.9 的版本上用一个技术预览版 Flink 的 SQL Planner 来替代老的 SQL Planner,支持原生 SQL 关键字,这对 SQL 的标准性以及 SQL 语法解析的正确性和高效性都是有一个更好的保障。
同时,作为开源技术的或者叫 Apache 社区的参与者,Cloudera 也会对 Apache Flink 这个技术做出更多贡献,其中会关注在安全层面上的集成,然后还有 Atlas 组件的集成,同时也会在接口层面会做一个新的 HBASE Connector。
此外,当前的 CSA 虽然支持 Kerberos 的语义环境,但是没有类似于像点击就完成的这种自动化的 Kerberos 配置,以及包括通过一些可视化的这种框架或者是统一的安全管理框架,比如说 Ranger,去管理任务的权限。因此,未来的 CSA 也会在面向企业管理的方向做一些新的更好的管理,包括 A/B 测试的一个 Flink 程序的管理,以及任务和任务 JAR 的管理等等。
同时,Cloudera 将投入更多力量到开源 Flink 的发展和社区的建设当中,希望和广大业界同仁一起助力 Flink 社区的发展。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论