
在大模型推理进入生产阶段后,如何最大化利用 GPU 资源、实现多模型共存、提高部署灵活性,成为了许多企业与开发者关注的重点。最近,vLLM 社区正式合并了 PR#579,原生支持了 CNCF Sandbox & CNAI Project HAMi。这不仅代表 HAMi 的能力被主流推理框架接纳,更意味着 vLLM 用户可以通过搭配 HAMi,开箱即用地进行 GPU 显存与算力切分部署。
本文将以该 PR 为切入点,结合社区 Issue 和邮件交流记录,从部署到验证,完整还原一条 "HAMi × vLLM" 的落地路径,帮助你在 Kubernetes 中快速实现多模型部署与资源复用。
一、1+1>2:vLLM × HAMi 的结合点
vLLM 是一款开源高性能推理引擎,以 PagedAttention 与连续批处理提升吞吐/并发并兼容 OpenAI 接口;vLLM Production Stack 的定位是把 vLLM 在 Kubernetes 上产品化,补齐弹性伸缩、可观测监控、流量路由/灰度与运维发布,使其可运营、可扩展地落地到生产环境。而 HAMi 提供了 GPU 的精细化切分与调度能力,包括:
GPU 算力控制(SM Util)
GPU 显存限制(MB / %)
节点/GPU 调度策略(Binpack / Spread)
拓扑感知调度(NUMA / NVLink)
实现生产级的 LLM 推理优化,是一个需要同时解决“计算”与“调度”的系统性工程。vLLM 专注于计算层,通过革新内存管理,将单张 GPU 的吞吐性能推向极致;HAMi 则专注于调度层与虚拟化,为 Kubernetes 带来了 GPU 资源的精细化切分与管理能力。二者结合,完美覆盖了从资源调度到性能优化这两大关键环节。
二、社区驱动的融合:源自真实需求的 PR #579
vLLM 与 HAMi 的这次集成并非项目方“自上而下”的规划,而是一次由真实用户需求驱动、“自下而上”的社区贡献。
这一切都始于 PR #579,社区贡献者 Andrés Doncel 来自西班牙 toB 电商搜索与商品发现平台提供商 Empathy.co。正如该公司在官方博客中所阐述的,其核心技术目标是“弥合生成式 AI 与事实准确性之间的鸿沟”——通过一种先进的 RAG(检索增强生成)框架,确保 AI 的回答有据可查、杜绝“幻觉”。
这种对事实准确性的极致追求,在技术实现上意味着需要将 Embedding(向量召回)、Reranking(模型精排)、事实校验等多个 AI 模型进行高效、低成本的协同部署。正是源于这一真实且迫切的生产需求,Andrés 贡献了 vLLM 对 HAMi 的支持,并被社区认可、合并,为所有 vLLM 用户带来了这套经过生产验证的降本增效方案。
为了探寻这一贡献背后的动机,我们与 Andrés 进行了交流。他提到:
“Our use case is to serve LLM-powered applications while minimizing the dependency from third party providers. We use HAMi and vLLM on top of Kubernetes... using the memory constraints to allow multiple models to reside in the same GPU.”
“我们的使用场景是服务基于大模型的应用,同时尽量减少对第三方提供商的依赖。我们在 Kubernetes 上使用 HAMi 和 vLLM,并通过内存限制允许多个模型共享同一张 GPU。”
这印证了社区用户真实使用 HAMi + vLLM 组合的场景需求。
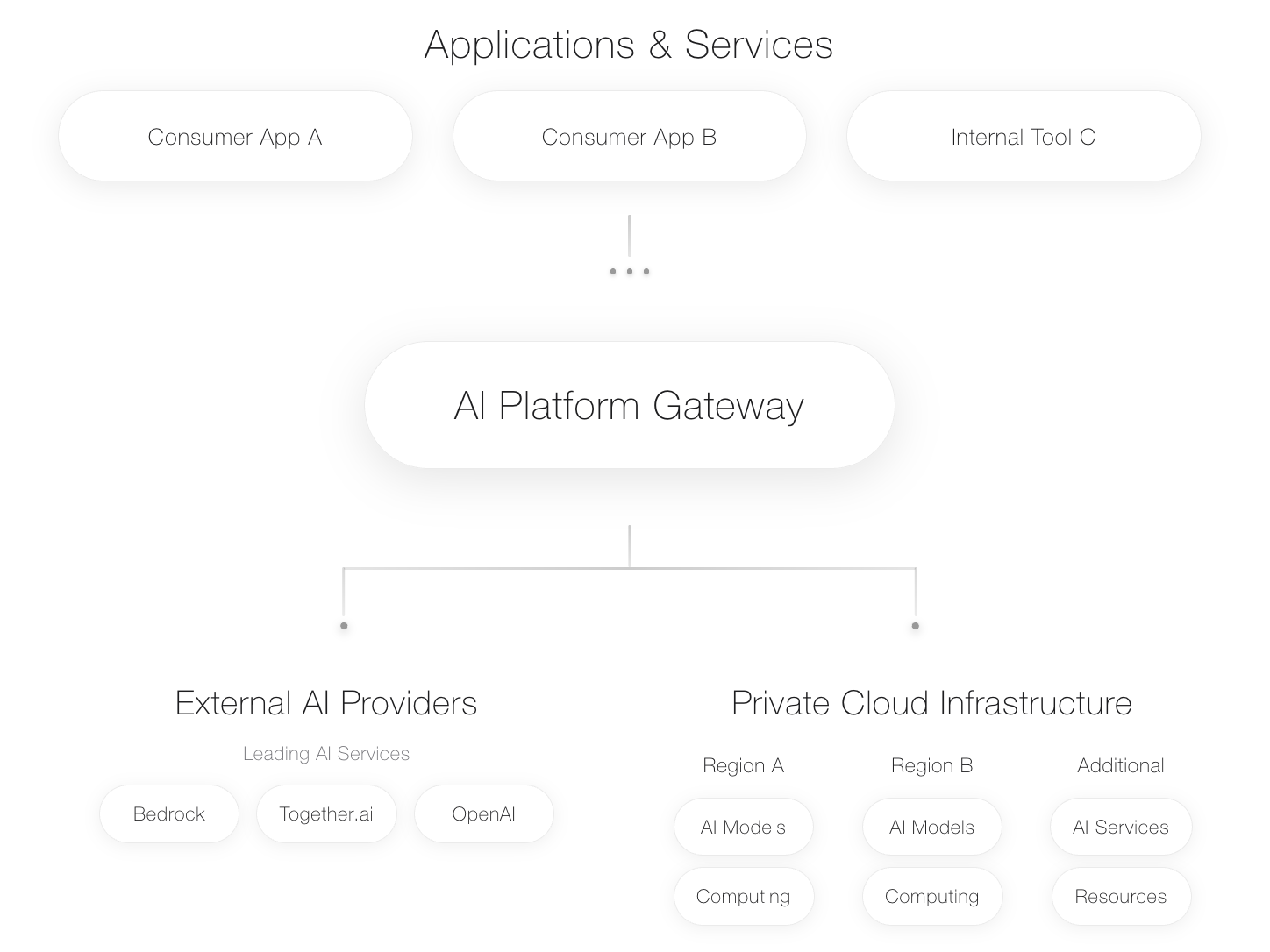
价值的迅速印证:Issue #649
该 PR 合并后不久,vLLM 社区用户在 Issue #649(https://github.com/vllm-project/production-stack/issues/649)中询问:“是否支持单卡部署多个模型?”
社区用户 @Nimbus318 回复指出:
“Hi, the Production-Stack community recently added native support for HAMi (a CNCF Sandbox project: Project-HAMi/HAMi) GPU slicing parameters, which fits exactly the GPU partitioning scenario you mentioned.
You can already find these parameters in the latest Helm values:
production-stack/helm/values.yaml Lines 41 to 43 in 8367d43
41 # - limitGPUMem: (Optional, string) Requires HAMi. The limit of GPU memory, e.g., 3000. Each unit equals
42 # - limitGPUMemPercentage: (Optional, string) Requires HAMi. The limit of GPU memory of GPU, e.g.,"80"
43 # - limitGPUCores: (Optional, string) Requires HAMi. The limit of GPU cores, e.g., "10". Each unit equals
To use them, you'll first need to install HAMi in your cluster. The setup is simple:
· Stop the default NVIDIA device plugin (for GPU Operator: --set devicePlugin.enabled=false).
· Then follow the HAMi installation guide to deploy it via helm install ...
After that, you can configure GPU slicing directly in your Production-Stack Helm values.”
@Nimbus318 回复指出:
“Production Stack 已原生支持 HAMi 参数,只需安装 HAMi 并配置切分参数即可。”
Issue 发起者 @ExplorerRay 认可并关闭 Issue:“Thanks for your help. I think HAMi fits my needs.”
从一个真实需求的 PR 贡献,到一个社区问题的完美解决,这形成了一个教科书式的开源社区正向循环。
三、完整实战:从安装部署到测试监控
3.1 准备工作:安装 HAMi 并接管 GPU 调度与分配
# 1. 若使用 NVIDIA GPU Operator,通过 Helm 禁用其默认 devicePluginhelm upgrade --install gpu-operator nvidia/gpu-operator \ -n gpu-operator \ --set devicePlugin.enabled=false \ --set dcgmExporter.serviceMonitor.enabled=true \ --version=v25.3.1# 2. 为需启用 GPU 共享的节点打标签kubectl label nodes <your-gpu-node-name> gpu=on# 3. 安装 HAMihelm repo add hami-charts https://project-hami.github.io/HAMi/helm install hami hami-charts/hami -n kube-system执行完毕后,HAMi 正式接管集群的 GPU 调度与分配,基础环境准备就绪。
3.2 核心步骤:通过 Production Stack 部署多模型
由于原生支持功能已合并到主干分支但未包含在正式发版中,需从 vLLM Production Stack 的 GitHub 仓库最新 Helm Chart 安装:
拉取最新源码并创建自定义配置文件
进入
production-stack项目的helm目录,创建values-hami-demo.yaml文件:
git clone https://github.com/vllm-project/production-stack.gitcd production-stack/helmtouch values-hami-demo.yaml将以下内容写入 values-hami-demo.yaml(部署蓝图:单张 L4 卡通过 binpack 策略部署 14GB 显存的 Embedding 模型与 8GB 显存的 Reranker 模型):
servingEngineSpec: modelSpec: # BAAI/bge-m3 Embedding Model - name: "bge-m3-embed" repository: "vllm/vllm-openai" tag: "latest" modelURL: "BAAI/bge-m3" replicaCount: 1 requestCPU: 2 requestMemory: "6Gi" requestGPU: 1 limitGPU: 1 requestGPUMem: "14000" limitGPUMem: "14000" podAnnotations: nvidia.com/use-gputype: "L4" hami.io/gpu-scheduler-policy: "binpack" pvcStorage: "10Gi" vllmConfig: dtype: "auto" maxModelLen: 8192 maxNumSeqs: 32 gpuMemoryUtilization: 0.85 extraArgs: ["--task", "embed"] # BAAI/bge-reranker-v2-m3 Reranker Model - name: "bge-reranker-v2-m3" repository: "vllm/vllm-openai" tag: "latest" modelURL: "BAAI/bge-reranker-v2-m3" replicaCount: 1 requestCPU: 2 requestMemory: "4Gi" requestGPU: 1 limitGPU: 1 requestGPUMem: "8000" limitGPUMem: "8000" podAnnotations: nvidia.com/use-gputype: "L4" hami.io/gpu-scheduler-policy: "binpack" pvcStorage: "5Gi" vllmConfig: dtype: "auto" maxModelLen: 512 maxNumSeqs: 8 gpuMemoryUtilization: 0.85 extraArgs: ["--task", "score"]从本地源码执行部署(末尾
.代表使用当前目录 Chart):
helm upgrade --install vllm -f values-hami-demo.yaml .
3.3 资源验证与功能测试
1. 资源分配验证:检查 GPU 共享状态
进入两个模型容器内部,执行 nvidia-smi 与 nvidia-smi -L 命令,验证 GPU 共享与显存分配是否符合配置:
Embedding 模型容器(
vllm-bge-m3-embed-deployment-vllm-54fb85bf7c-gwjrn):
root@vllm-bge-m3-embed-vllm-stack:/vllm-workspace# nvidia-smiMon Sep 1 03:40:08 2025+-----------------------------------------------------------------------------+| NVIDIA-SMI 570.148.08 Driver Version: 570.148.08 CUDA Version: 12.8 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. || | | MIG M. ||===============================+======================+======================|| 0 NVIDIA L4 On | 00000000:00:04.0 Off | 0 || N/A 63C P0 37W / 72W | 1389MiB / 14000MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=============================================================================|| 0 N/A N/A 112 C vllm::EngineCore 1490MiB |+-----------------------------------------------------------------------------+root@vllm-bge-m3-embed-vllm-stack:/vllm-workspace# nvidia-smi -LGPU 0: NVIDIA L4 (UUID: GPU-ed8ae6fb-ac66-2346-e6a5-d440223e29a2)Reranker 模型容器(
vllm-bge-reranker-v2-m3-deployment-vllm-7dcb7965d9-xwvr7):
root@vllm-bge-reranker-v2-m3-vllm-stack:/vllm-workspace# nvidia-smiMon Sep 1 03:38:24 2025+-----------------------------------------------------------------------------+| NVIDIA-SMI 570.148.08 Driver Version: 570.148.08 CUDA Version: 12.8 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. || | | MIG M. ||===============================+======================+======================|| 0 NVIDIA L4 On | 00000000:00:04.0 Off | 0 || N/A 63C P0 37W / 72W | 1373MiB / 8000MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=============================================================================|| 0 N/A N/A 112 C vllm::EngineCore 1450MiB |+-----------------------------------------------------------------------------+root@vllm-bge-reranker-v2-m3-vllm-stack:/vllm-workspace# nvidia-smi -LGPU 0: NVIDIA L4 (UUID: GPU-ed8ae6fb-ac66-2346-e6a5-d440223e29a2)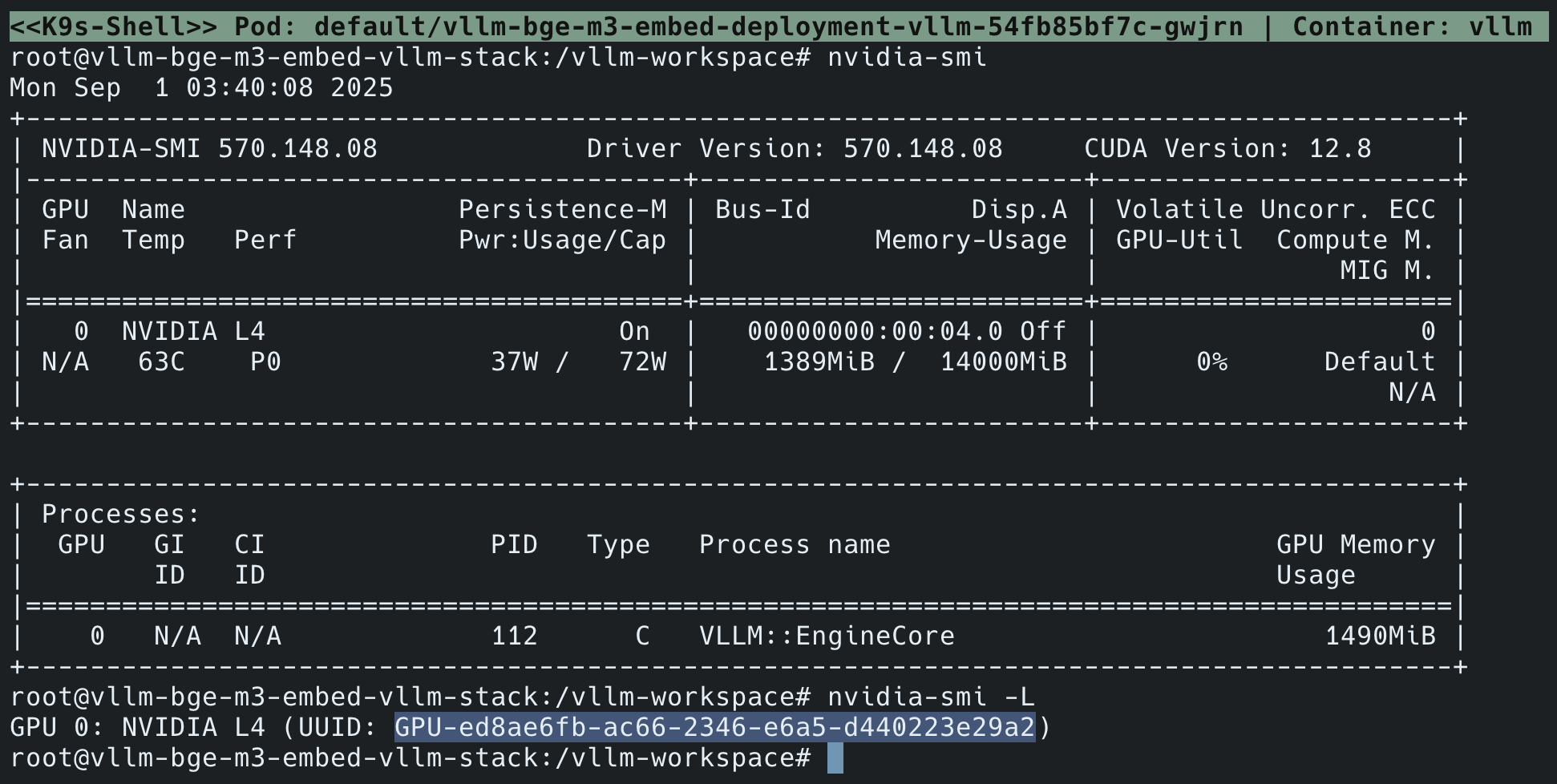
2. 协同功能测试:模拟真实 RAG 调用链路
通过 rag_bench.py 脚本模拟 RAG 调用链路,验证多模型并发协同能力:
脚本源码(rag_bench.py):
import os, time, random, asyncio, aiohttpimport numpy as npBASE_URL = os.getenv("BASE_URL", "http://localhost:30080/v1")EMBED_MODEL = os.getenv("EMBED_MODEL", "BAAI/bge-m3")RERANK_MODEL = os.getenv("RERANK_MODEL", "BAAI/bge-reranker-v2-m3")DOC_MULT = int(os.getenv("DOC_MULT", "600")) # 语料倍数,控制候选集规模Q_CONCURRENCY = int(os.getenv("Q_CONCURRENCY","16"))Q_TOTAL = int(os.getenv("Q_TOTAL","400")) # 总查询数K_RECALL = int(os.getenv("K_RECALL","40"))K_RERANK = int(os.getenv("K_RERANK","8"))DOCS_SEED = [ "边缘计算是在靠近数据源头侧进行分布式处理的计算范式。", "云计算通过集中式数据中心提供按需算力与存储资源。", "向量检索将文本映射为稠密向量并按相似度召回候选。", "RAG 通过外部检索到的证据提高生成答案的可靠性。", "BM25 是基于倒排索引的稀疏检索算法,适合关键词匹配。"]def pct(arr, p): return float(np.percentile(arr, p)) if arr else 0.0async def detect_rerank_path(session): # 优先 /v1/rerank,不行则回退 /v1/score for path in ("/rerank", "/score"): try: payload = {"model": RERANK_MODEL, "query": "ping", "documents": ["a","b"], "top_n": 1} async with session.post(f"{BASE_URL}{path}", json=payload, timeout=5) as r: if r.status == 200: return path except Exception: pass raise RuntimeError("Neither /v1/rerank nor /v1/score is available.")async def embed_batch(session, texts, batch=64): vecs = [] for i in range(0, len(texts), batch): payload = {"model": EMBED_MODEL, "input": texts[i:i+batch], "encoding_format": "float"} async with session.post(f"{BASE_URL}/embeddings", json=payload, timeout=60) as r: j = await r.json() vecs.extend([d["embedding"] for d in j["data"]]) return np.array(vecs, dtype=np.float32)async def query_once(session, rerank_path, q, doc_texts, doc_vecs): t0 = time.time() # embed query payload = {"model": EMBED_MODEL, "input": [q], "encoding_format": "float"} async with session.post(f"{BASE_URL}/embeddings", json=payload, timeout=15) as r: ej = await r.json() qv = np.array(ej["data"][0]["embedding"], dtype=np.float32) t1 = time.time() # ANN(内存余弦相似度;生产里换向量库) qn = qv / (np.linalg.norm(qv) + 1e-8) dn = doc_vecs / (np.linalg.norm(doc_vecs, axis=1, keepdims=True) + 1e-8) sims = dn @ qn top_idx = np.argpartition(sims, -K_RECALL)[-K_RECALL:] cand_idx = top_idx[np.argsort(-sims[top_idx])] docs = [doc_texts[i] for i in cand_idx[:K_RECALL]] # rerank payload = {"model": RERANK_MODEL, "query": q, "documents": docs, "top_n": K_RERANK} async with session.post(f"{BASE_URL}{rerank_path}", json=payload, timeout=15) as r: rj = await r.json() t2 = time.time() return (t1 - t0, t2 - t1, t2 - t0), rj.get("results", [])async def main(): queries = [f"什么是{w}?" for w in ["边缘计算","向量检索","RAG","BM25","混合检索"]] * (Q_TOTAL // 5) random.shuffle(queries) async with aiohttp.ClientSession() as session: # 端点探测 rerank_path = await detect_rerank_path(session) print(f"[info] rerank endpoint = {BASE_URL}{rerank_path}") # 构造“候选库”并嵌入(离线建库) docs = DOCS_SEED * DOC_MULT print(f"[info] building doc embeddings: {len(docs)} docs ...") doc_vecs = await embed_batch(session, docs, batch=64) lat_e, lat_r, lat_t = [], [], [] sem = asyncio.Semaphore(Q_CONCURRENCY) t_start = time.time() async def worker(q): async with sem: (e, r, t), _ = await query_once(session, rerank_path, q, docs, doc_vecs) lat_e.append(e); lat_r.append(r); lat_t.append(t) await asyncio.gather(*[worker(q) for q in queries]) dur = time.time() - t_start n = len(queries) to_ms = lambda x: round(x*1000, 1) print(f"\nRequests={n} Duration={dur:.1f}s QPS={n/dur:.1f}") print(f"Embed p50/p95: {to_ms(pct(lat_e,50))} / {to_ms(pct(lat_e,95))} ms") print(f"Rerank p50/p95: {to_ms(pct(lat_r,50))} / {to_ms(pct(lat_r,95))} ms") print(f"Total p50/p95: {to_ms(pct(lat_t,50))} / {to_ms(pct(lat_t,95))} ms")if __name__ == "__main__": asyncio.run(main())执行测试步骤:
# 将 vLLM 路由服务端口转发到本地kubectl port-forward svc/vllm-router-service 30080:80 &# 运行功能测试脚本(模拟 2000 次查询)Q_TOTAL=2000 python3 rag_bench.py注:该脚本为功能测试,存在三处与生产环境的简化:
检索方式非生产级:向量检索在内存中完成,仅为模拟,不代表专用向量数据库性能;
缺乏容错性:无重试或错误处理逻辑,不具备生产级健壮性;
只验证通路:仅确认 API 正常返回,不评估结果相关性,非性能基准测试。但脚本无错误运行,可证明共享部署方案功能可用、服务畅通。
3.4 测试结果与监控看板
1. 测试结果输出
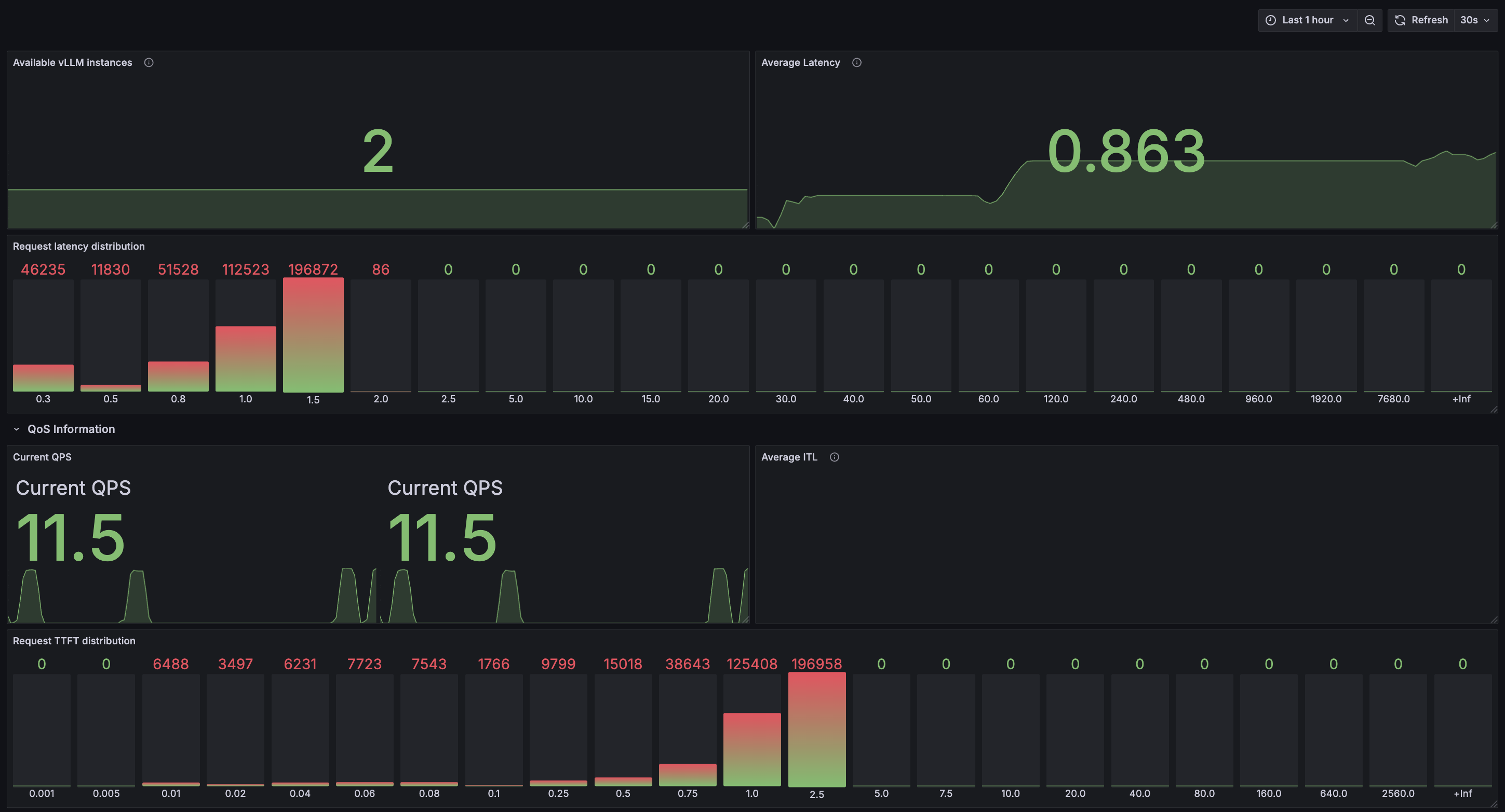
> Q_TOTAL=2000 python3 rag_bench.py[info] rerank endpoint = http://localhost:30080/v1/rerank[info] building doc embeddings: 3000 docs ...Requests=2000 Duration=176.9s QPS=11.3Embed p50/p95: 160.6 / 427.6 msRerank p50/p95: 1225.6 / 1401.4 msTotal p50/p95: 1395.5 / 1647.9 ms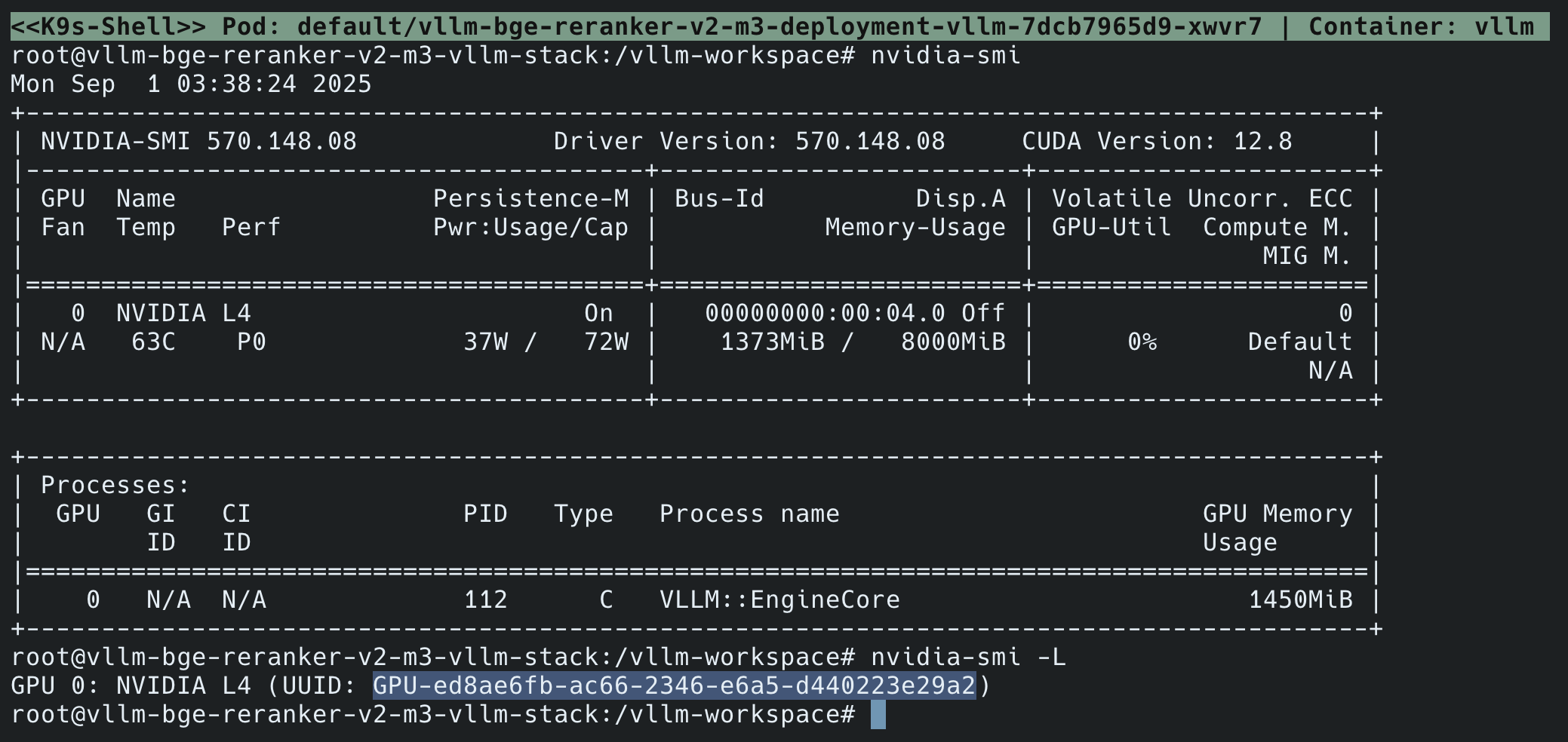
2. 监控看板
vLLM 服务监控:含 Available vLLM instances、Average Latency、Request latency distribution 等指标(参考链接:https://github.com/vllm-project/production-stack/tree/main/observability)
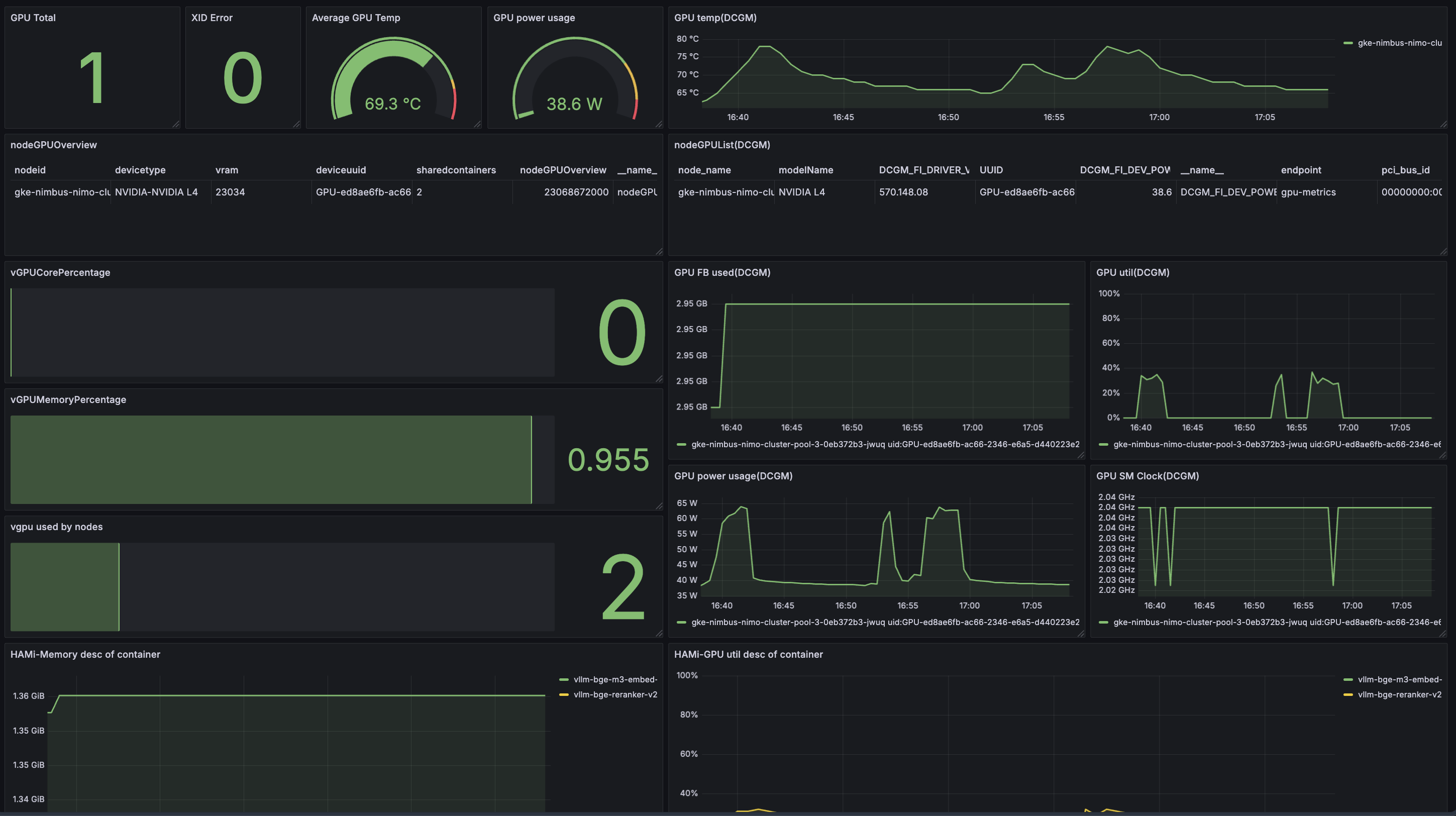
GPU 资源监控:含 GPU 温度(平均 69.3°C)、功耗(平均 38.6W)、显存/算力使用率等(DCGM 监控)
HAMi 专属监控:含容器级 GPU 显存/算力分配详情(参考链接:https://github.com/Project-HAMi/HAMi/blob/master/docs/dashboard_cn.md)
总结与展望
这次 PR #579 的合入标志着:HAMi 已成为 vLLM Production Stack 官方集成并认可的 GPU 共享方案。二者的结合,为大模型推理生产环境提供了“计算优化+资源调度”的完整解决方案,帮助企业在有限 GPU 资源下部署更多模型、降低成本。
我们期待未来更多模型推理部署工程化方案能原生对接 HAMi,推动 GPU 资源利用效率进一步提升,让大模型推理在生产环境中更灵活、更高效。
HAMi,全称是 Heterogeneous AI Computing Virtualization Middleware(异构算力虚拟化中间件),是一套为管理 k8s 集群中异构 AI 计算设备设计的“一站式”架构,能提供异构 AI 设备共享能力与任务间资源隔离。HAMi 致力于提升 k8s 集群异构计算设备利用率,为不同类型异构设备提供统一复用接口,当前是 CNCF Sandbox 项目,已被纳入 CNCF CNAI 类别技术全景图。
社区相关链接:
官网:https://project-hami.io
Github:https://github.com/Project-HAMi
Reddit:https://www.reddit.com/r/HAMi_Community/




