

在 Elasticsearch 的运维过程中,我们经常会遇到节点不可用、OOM 和垃圾回收时间过长等问题,如果每次都等出问题了才发现,极端情况下会影响业务访问。在日常运维中,我们需要提前预测这些问题,及时处理,防止影响业务。那么问题来了!我们要怎么监测呢?
Elasticsearch
Elasticsearch 本身提供了大量的指标,可以帮助我们进行故障预检,并在遇到诸如节点不可用、JVM OutOfMemoryError 和垃圾回收时间过长等问题时采取必要措施。 通常需要监测的几个关键领域是:
查询和索引(indexing)性能
内存分配和垃圾回收
主机级别的系统和网络指标
集群健康状态和节点可用性
资源饱和度和相关错误
这些指标都是可以通过 Elasticsearch’s RESTful API 获取,也可以使用像 Marvel 这样的专用监控工具或者像 Datadog 这样的通用监控服务来监测。
查询(search)和索引(indexing)是 Elasticsearch 最主要的两种访问请求类型,他们有点类似于传统数据库系统中的读和写请求。
查询性能指标
对于查询(search)请求,Elasticsearch 提供了与查询过程的两个主要阶段(Query 和 Fetch)相对应的指标。
下面的图示展示了一个查询请求的完整过程:
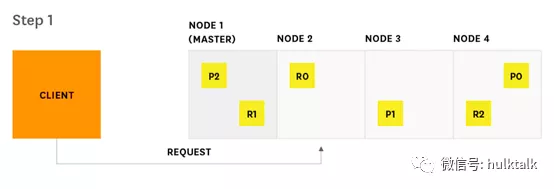
1.客户端发送请求给 Node2(Node2 通常被称为“协调节点”,原则上,Elasticsearch 的任意节点都可以成为协调节点)
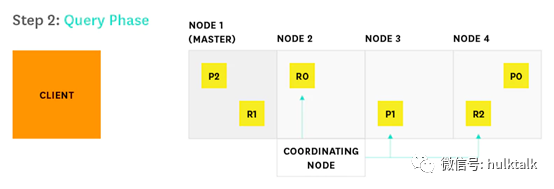
协调节点将请求转发至该索引的每一个分片的任意副本,既可以是主分片也可以是副本分片。
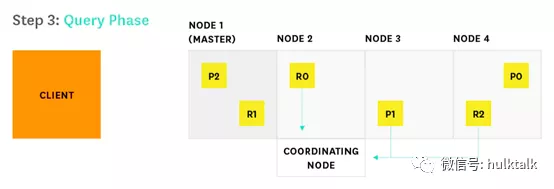
每个接收请求的分片执行检索并将检索结果返回给协调节点,协调节点将接收到的检索结果排序并存储在一个全局优先级队列里。这里返回的并不是整个文档,通常是需要聚合和排序的字段以及全局唯一 ID。
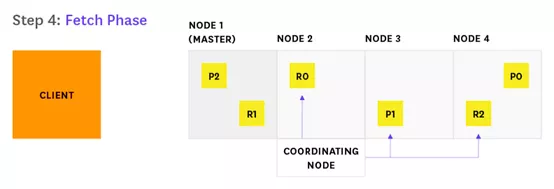
协调节点找出哪些文档需要被获取(Fetch),然后发送一个 Multi GET 请求到相关的分片。
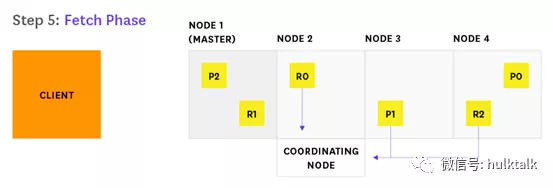
5.每一个接收请求的分片获取对应数据然后返回给协调节点。
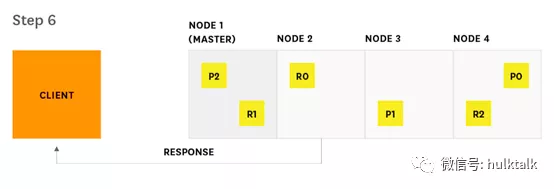
6.协调节点发送数据给客户端。
如果您主要使用 Elasticsearch 进行查询,那么您应该关注查询延迟并在超出阈值时采取措施。监控 Query 和 Fetch 的相关指标可以帮助您跟踪查询在一段时间内的执行情况。例如,您可能需要跟踪查询曲线的峰值以及长期的查询请求增长趋势,以便可以优化配置来获得更好的性能和可靠性。
下图是需要关注的查询性能指标:
查询(Query)负载
监控当前查询并发数可以让您大致了解集群在某个时刻处理的请求数量。对不寻常的峰值峰谷的关注,也许能发现一些潜在的风险。您可能还需要监控查询线程池队列的使用情况,关于这一点我们将在稍后的文章中详细解释。
查询(Query)延迟
虽然 Elasticsearch 并没有直接提供这个指标,但是我们可以通过定期采样查询请求总数除以所耗费的时长来简单计算平均查询延迟时间。如果超过我们设定的某个阀值,就需要排查潜在的资源瓶颈或者优化查询语句。
获取(Fetch)延迟:
查询(search)过程的第二阶段,即获取阶段,通常比查询(query)阶段花费更少的时间。如果您注意到此度量指标持续增加,则可能表示磁盘速度慢、富文档化(比如文档高亮处理等)或请求的结果太多等问题。
索引性能指标
索引(Indexing)请求类似于传统数据库里面的写操作。如果您的 Elasticsearch 集群是写负载类型的,那么监控和分析索引(indices)更新的性能和效率就变得很重要。在讨论这些指标之前,我们先看一下 Elasticsearch 更新索引的过程。如果索引发生了变化(比如新增了数据、或者现有数据需要更新或者删除),索引的每一个相关分片都要经历如下两个过程来实现更新操作:refresh 和 flush。
Refresh
首先我们要明确的是,新写入的文档在被 refresh 之前,并不能被检索到。新的文档首先会被写入内存的 buffer 里,并等待下一次索引的 refresh 操作。如果没有单独配置,refresh 操作默认是每秒执行一次。每次 refresh 操作会把当前 buffer 里的数据写入一个内存段(segment,只有 segment 里的数据才能被检索到),然后清空对应的 buffer。如下图所示:
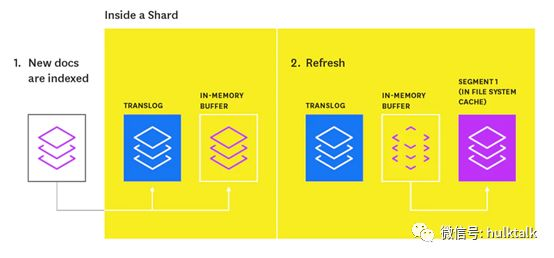
这里关于 segment 的概念,我们稍微展开一点。大家知道,索引的每个分片都是由若干个 segment 组成。每一个 segement 都是一个完整的倒排索引(Inverted Index),用于保存词项(terms)和文档的对应关系,查询的时候会依次检索对应分片的所有 segment。每次索引执行 refresh 的时候,都会生成一个新的 segement,因此 segment 实际上记录了索引的一组变化值。但是由于每个 segement 的存储和扫描都需要占用一定资源(文件描述符、CPU、内存等),因此需要后台进程不断的进行段合并来减少 segement 的数量,从而提升效率降低资源消耗。但是段合并本身也是一个比较消耗性能的操作。
由于 segment 一旦生成就不能更新,因此文档的更新(Update)实际上意味着:
1.通过 refresh 将新的数据写入新的 segment。
2.然后将旧的数据标记为 deleted
这些被标记删除的数据在后续的段合并过程中才会最终被删除。
Flush
在新的文档被添加到索引内存缓冲区的同时,它们也被追加到分片的 translog。translog 是一个持久化的,记录所有更改操作( index, delete, update, or bulk)的 write-ahead 日志,可以防止数据丢失,并且可以用于分片的数据恢复。
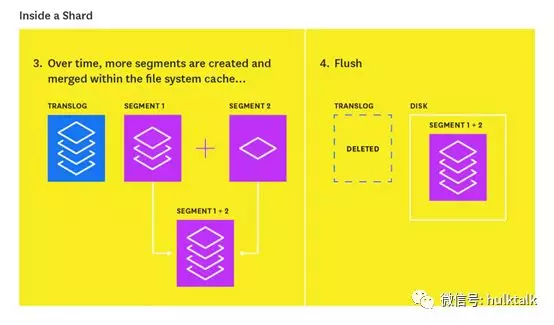
每次 flush 操作,内存缓冲区中的所有文档都被 refreshed(存储在新的 segment 中),所有内存中的 segment 都将落盘,并且清除 translog。
有三种条件可以触发 flush 操作:
1.translog 日志达到限制大小(index.translog.flush_threshold_size,默认为 512MB);
2.如果设置了 index.translog.durability=request,则每次更新操作( index, delete, update, or bulk)之后都执行 flush(这是 Elasticsearch 的默认行为)
3.如果 index.translog.durability= async,则采用异步 sync 机制,每 index.translog.sync_interval 执行一次 flush 操作,默认是 5 秒,但是这种情况可能导致未落盘的数据丢失。
flush 的过程如下图所示:
Elasticsearch 提供了许多指标,您可以使用这些指标评估索引性能并优化更新索引的方式。
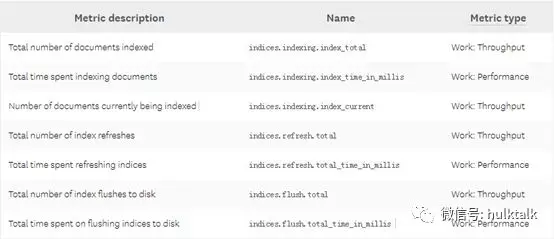
索引(Indexing)延迟:
Elasticsearch 并未直接提供这个指标,但是可以通过计算 index_total 和 index_time_in_millis 来获取平均索引延迟。如果您发现这个指标不断攀升,可能是因为一次性 bulk 了太多的文档。Elasticsearch 推荐的单个 bulk 的文档大小在 5-15MB 之间,如果资源允许,可以从这个值慢慢加大到合适的值。
如果您想要索引大量数据,并且不需要立即查询索引的数据,可以通过临时降低指定索引的 refresh 间隔,来提升索引的效率。如下 API 可以关闭索引的 refresh 操作:
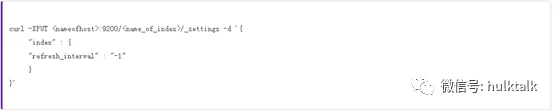
但是请记得索引完数据,最好将这个参数改回默认值 1s。
Flush 延迟:
由于 Elasticsearch 是通过 flush 操作来将数据持久化到磁盘的,因此关注这个指标非常有用,可以在必要的时候采取一些措施。比如如果发现这个指标持续稳定增长,则可能说明磁盘 IO 能力已经不足,如果持续下去最终将导致无法继续索引数据。此时您可以尝试适当调低 index.translog.flush_threshold_size 的值,来减小触发 flush 操作的 translog 大小。与此同时,如果你的集群是一个典型的 write-heavy 系统,您应该利用 iostat 这样的工具持续监控磁盘的 IO,必要的时候可以考虑升级磁盘类型。
内存分配和垃圾回收
在 Elasticsearch 运行过程中,内存是需要密切关注的关键资源之一。
Elasticsearch 和 Lucene 以两种方式利用节点上的所有可用 RAM:JVM 堆和文件系统缓存。 Elasticsearch 运行在 Java 虚拟机(JVM)上,这意味着 JVM 垃圾回收的持续时间和频率将是其他重要的监控领域。
JVM 堆栈:金发女孩效应
Elasticsearch 使用“恰到好处”来强调 JVM 堆栈大小的设置原则,既不能太大,也不能太小。一般来说,Elasticsearch 的经验法则是将少于 50%的可用内存分配给 JVM 堆,并且永远不要超过 32GB。分配给 Elasticsearch 的堆栈内存越少,留给 Lucene 的内存就越多,而 Lucene 在很大程度上依赖于文件系统缓存来快速检索数据。但是也不应该将堆大小设置得过于小,因为您可能会遇到 OutOfMemoryError,或者是因为频繁的垃圾回收过程中的短暂暂停导致的吞吐量降低。可以参阅指南来确定堆栈的大小,这是由 Elasticsearch 的核心工程师之一编写的。
垃圾回收
Elasticsearch 依靠垃圾回收来释放堆栈内存。如果您想了解更多关于 JVM 垃圾回收的信息,请查看 Java 官方指南。由于垃圾回收本身需要消耗资源(为了释放资源!),您应该留意它的频率和持续时间,看看是否需要调整堆栈大小。将堆栈设置得太大可能导致垃圾回收时间过长,这些过多的暂停是非常危险的,因为它们可能会导致您的群集错误地认为您的节点已经掉线。
下图是需要关注的 JVM 相关指标:
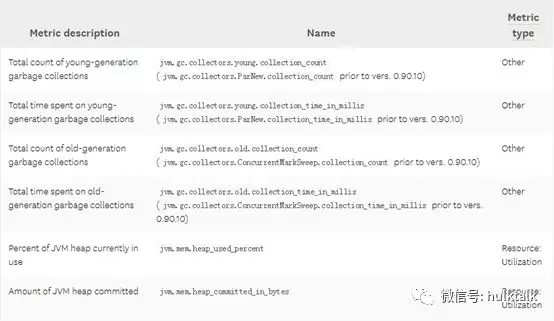
JVM 堆栈使用率
Elasticsearch 默认当 JVM 堆栈使用率达到 75%的时候启动垃圾回收。因此监控节点堆栈使用情况并设置告警阀值来定位哪些节点的堆栈使用率持续维持在 85%变得非常有用,这表明垃圾回收的速度已经赶不上垃圾产生的速度了。要解决这个问题,您可以增加堆栈大小,或者通过添加更多的节点来扩展群集。
和 JVM 堆栈分配了多少内存(committed)相比,监控 JVM 使用了多少内存(used)会更加有用。使用中的堆栈内存的曲线通常会呈锯齿状,在垃圾累积时逐渐上升在垃圾回收时又会下降。 如果这个趋势随着时间的推移开始向上倾斜,这意味着垃圾回收的速度跟不上创建对象的速度,这可能导致垃圾回收时间变慢,最终导致 OutOfMemoryError。
垃圾回收的时长和频率:
为了收集无用的对象信息,JVM 会暂停执行所有任务,通常这种状态被称为“Stop the world”,不管是 young 还是 old 垃圾回收器都会经历这个阶段。由于 Master 节点每隔 30s 检测一下其他节点的存活状态,如果某个节点的垃圾回收时长超过这个时间,就极可能被 Master 认为该节点已经失联。
内存使用
正如上面所述,Elasticsearch 可以很好地使用任何尚未分配给 JVM 堆的 RAM。 和 Kafka 一样,Elasticsearch 被设计为依靠操作系统的文件系统缓存来快速可靠地处理请求。如果某个 segment 最近由 Elasticsearch 写入磁盘,那么它已经在缓存中。 但是,如果一个节点已被关闭并重启,则在第一次查询一个 segment 的时候,必须先从磁盘读取数据。所以这是确保群集保持稳定并且节点不会崩溃的重要原因之一。通常,监视节点上的内存使用情况非常重要,并尽可能为 Elasticsearch 提供更多的 RAM,以便在不溢出的情况下最大化利用文件系统缓存。
总结
本文讲解了三个领域的监测指标:
查询和索引(indexing)性能
内存分配和垃圾回收
主机级别的系统和网络指标
下篇文章,我们将继续讲解剩下的两类指标:
集群健康状态和节点可用性
资源饱和度和相关错误
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/QBjSSYVjHJMLJ6-7yj1bzA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论