

在波士顿 InfoQ Dev 峰会上,Justin Sheehy 进行了一场题为 “在 AI 热潮时代成为一名负责任的开发者”的主题演讲。本文是对演讲内容的概述,首先探讨了开发者所持有的权力,以及人工智能的运作机制。
我们都是软件从业者,软件行业的人最大的失误之一是认为我们不需要听取来自行业外的声音,比如语言学家、哲学家、心理学家、人类学家、艺术家和伦理学家的意见。作为开发者,我们有时会忘记自己手中握有的权力。
最优秀的技术行业分析师之一 Steve O’Grady 大概在十年前表达过 这个观点,而这一观点至今依然成立。你的决策很重要。我们需要知道如何做出良好而负责任的决策,特别是在当前 AI 发展趋势下的决策。
近年来,AI 领域取得了巨大的飞跃,其中一些成果确实令人瞩目。然而,围绕 AI 的炒作更是铺天盖地,令人惊叹。因此,将当前时期称为“AI 热潮时代”一点也不夸张。
AI 是如何运作的?
首先,我们需要明确我们所说的人工智能究竟指的是什么。这是一个非常宽泛的术语。请记住,它本质上只是一个计算机程序,不要让自己误以为它有什么神奇之处。
这些程序究竟属于什么类型?我要感谢 Julia Ferraioli 提醒我一个非常基础的分类方法:多年来,构建 AI 一直围绕着两大类技术,一类是逻辑和符号处理,另一类是统计学和将过去观察到的概率分布映射到未来。最近的关注点都集中在基于概率的系统上。我将重点放在大家热议的部分,即大语言模型。
图 1 - AI:符号处理或概率处理?
推动当前自动回归(AR-LLM)语言模型进步的众多因素之一是 Transformer,它不仅提升了模型的输出质量,还增强了模型构建的并行性。即便近期有许多显著的进展,这些语言模型也只是之前模型更高效、更高并行度、更可扩展的迭代版本。正如 OpenAI 技术报告对 GPT-4 的定义:GPT-4 是一个预训练模型,旨在预测文档中的下一个 Token。
如果你意识到 AR-LLM 做的就是这些事情,你就会明白它并不具备规划能力或知道任何东西。它没有关于知识、意义、理解的概念,更不用说意识了,它只是在生成下一个最有可能的单词。
在回应欧盟的诉讼时,OpenAI 在其法律答复中明确指出,其系统所做的唯一的事情就是预测并响应每个提示词的下一个最有可能的单词。
未来可能会有其他类型的 AI 系统被创造出来,但当前的 AR-LLM 系统并不会突然获得其他能力。
AI 炒作时代
需要强调的是,这些 LLM 确实非常强大。但它们如此出色,我为什么称之为 AI 的炒作时代,而不是卓越时代?
人们正在做出一些相当夸张的断言,数十亿美元被押注在 AI 公司身上。我希望帮助大家更理性地评估这些非凡的技术,做出更明智的决策。为此,我们需要不被炒作和无稽之谈所迷惑。
当前炒作的一个重点是许多人声称当前的 LLM(如 ChatGPT、PaLM、Llama、Claude 等)正在向通用人工智能(AGI)迈进,而 AGI 大概就是科幻作品中那些拥有人类智能的 AI。
一篇来自微软研究院的论文试图证明这一点,它声称像 GPT-4 这样的 LLM 展现出了通用智能的迹象,并在论文中专门讨论了“心智理论”。他们进行了一项关于信念、知识和意图的心理学测试,而 GPT 通过了。但事实证明,如果稍微改变一下测试方法,GPT 就会失败。人类在这种情况下通常不会如此表现。
谷歌的 Blaise Agüera y Arcas 和 Peter Norvig 在另一篇文章中甚至提出了更夸张的 AGI 主张。然而证据何在呢?并没有。这篇文章似乎将举证责任推给了那些质疑这一主张的人。
一个常见的观点是:“既然当前的 AR-LLM 比以前的系统看起来更加智能,我们只需要提供更多的数据和更强的计算能力,它们就会持续进步,并最终实现目标。”这种观点误解了 LLM 的真正作用,因为它们的设计初衷是为了生成文本。更多的数据和计算能力可能会使其在这棵树上爬得更高,但永远无法登上月球。
另一种观点认为,由于 LLM 生成的回答与人类的回答相似,因此它们通过了基本的智能测试。这是对图灵测试的误解。艾伦·图灵称这个测试为“模仿游戏”,而模仿人类生成文本与真正的智能是截然不同的。图灵甚至认为,试图回答机器是否智能的问题本身就是荒谬的。
还有一种观点认为,人类的思维过程与 LLM(如 ChatGPT)的行为类似,都不过是概率性地串联单词。提出这一观点的人很像 LLM,非常擅长制造听起来合理的论调,但背后并没有真正的知识或理解作为支撑。
“随机鹦鹉”一词源自一篇关于 LLM 风险的批判性论文。这是伦理学家合理关注的主题,然而撰写这篇论文的谷歌伦理 AI 学者却因此被解雇。Margaret Mitchell 在文中以 “Shmargaret Shmitchell” 的化名出现,因为她无法使用真实姓名。
AR-LLM 是概率性重复文本的机器,非常像一只学会模仿人类声音的鹦鹉,但又完全不理解这些声音的含义。OpenAI CEO 奥特曼声称人类也是这样,这一说法相当古怪。

问题的核心在于人们没有意识到语言是人类用来交流的工具,其形式旨在传达意义。当我们有想法、信念或知识时,我们会用语言来表达。而 LLM 没有任何想法、信念或知识,它们只是机械地合成文本,而不附加任何意义。
Meta AI 研究负责人、图灵奖得主杨立昆曾写道:“仅通过语言训练的系统永远无法接近人类智能。”
语言本身并不包含所有与人类智能相关或所需的要素。那些仅在形式上进行训练的系统无法发展出对意义的理解。

图 2 - 幻视的一个例子
这张图里没有人类的面孔,但你似乎可以看到一个。这种现象被称为“面孔幻视”(Face Pareidolia)。大多数人类都会这样,甚至会在这些图像中感知到并不存在的情绪。这张脸实际上是你的大脑创造的。同样地,当你阅读一段与人类写作非常相似的文本时,很容易误以为这些文本背后存在某种意图或意义。即使是那些了解这些系统工作原理的人也可能会被愚弄。但你可以克服这一挑战,提醒自己,这些终究只是计算机程序。
幻觉
LLM 的“幻觉”一词实际上是对我们的一种误导。当人类产生幻觉时,说明他们的真相感和意义感知与观察到的现实脱节。而 AR-LLM 并不具备感知真相或意义的能力,也没有所谓的观察到的现实。它们总是在做同样的一件事情——根据统计预测下一个单词。它们没有意图,没有对现实的感知。从某种角度看,它们要么一直处于“幻觉”状态,要么从未有过“幻觉”。即便我们接受“幻觉”这个说法,我们也不应期待随着系统的发展这一现象会消失。生成与外部现实无关的文本是它们的本质,而不是一个 Bug。LLM 从来没有“错”,只有当你期待它们正确回答你的问题时,它们才会被认为是“错”的。它们生成的只是前文最有可能的后续文本,而这和正确回答问题完全是两码事。
受到科幻小说中关于 AGI 的创意的启发,人类误认为 LLM 可以产生任意的行为。这是一个有趣的想法,但与这些系统的实际工作原理并不相符。它们确实是很酷的程序,但它们并不会自主进化。
有报道称谷歌的大语言模型 Gemini 学会了孟加拉语,尽管它从未接受过这门语言的训练。这类故事容易让人信服,但 Margaret Mitchell 仅用一天时间就揭示了真相:训练数据集中实际上包含了孟加拉语。

几个月后,谷歌在 YouTube 上发布了一段展示模型新行为的视频,例如在与用户的口语对话中实时识别图像。但后来证实这只是视频编辑的效果。
人类与 AI
让我们暂时跳出对 LLM 的狭隘讨论,转向一个更广泛的话题——人类与 AI 的关系。一些人可能听说过“机械土耳其人”(Mechanical Turk),一台出色的下象棋的机器。作为 AI 早期的著名例子之一,它曾与本杰明·富兰克林和拿破仑等历史人物对弈,并赢得了大多数比赛。我们已经有足够先进的 AI 能够击败人类棋手,这个历史已经超过了 200 年,但有趣的是,当时的机器内部实际上藏着一名真正的棋手。这是一个绝妙的把戏,也是许多现代 AI 运作方式的一个缩影。
我们经常看到 AI 系统宣称拥有类似人类的智能,例如亚马逊的 AI 自助结账系统“机械土耳其人”。Cruise 的自动驾驶汽车平均每辆车都配有一名以上的远程驾驶员。这些不仅是 AI 系统背后的人力支撑,也是过度炒作的产物。这些例子提醒我们,如果某个东西表现得像人类,而你又无法了解其工作原理,那么在没有确凿证据之前,不要轻易相信它不是由人类操纵的。
即便不存在“幕后操纵者”,AI 系统中也有很多人力元素。例如,ChatGPT 的重要突破之一是基于人类反馈的强化学习(RLHF)。人们审阅了大量初始的提示词答案,构建了最初的训练集,然后通过互动建立奖励模型。这是一个程序加上大量低薪人力劳动的成果。
使用 ChatGPT 或类似模型的背后,是成千上万的工人,他们以每小时几美元的微薄收入从事着软件从业者不会做的工作。这引发了一系列伦理问题。
开发者该怎么做
没有人愿意落后:“我的老板告诉我,我们必须在产品中加入 AI 技术,这样就能在下一次新闻发布会上提到 AI。”
那么,我们应该怎么做?我们是开发者,我们开发软件系统。我们明白,这些系统本质上只是计算机运行的程序。一些人可能正在开发这些 AI 系统,其他人则在使用这些系统构建其他系统,比如 GitHub Copilot,或者在网站上集成聊天机器人。大多数开发者都在使用 LLM 或其封装服务。我们来探讨一下我们有哪些选择。
如何确保我们对它们的使用是审慎的?如果你不能通过电子邮件发送公司的机密信息,如源代码或业务数据,那么在将这些数据发送给其他公司运行的服务之前也应该三思。如果你没有与他们签订合同,他们可能会将信息泄露给第三方。因此,许多企业制定了禁止使用 ChatGPT 或 Copilot 等系统的政策。
LLM 的知识产权问题尚未得到解决,如果你打算将不是自己训练的 LLM 生成的代码、文本、图像或其他内容集成到产品或系统中,可能需要谨慎行事。
这不仅仅是为了规避诉讼风险,也非无端的担忧。我曾参与过初创公司的并购尽职调查,深知如果所有东西的来源都是明确的,整个流程会顺利得多。
请务必不要向这些系统发送你不愿公开的内容,或者在你希望保留隐私的内容中使用它们的输出,除非你使用的是自己训练的模型。如果你自己使用合法内容训练模型,并且模型是自己使用的,就会安全得多。
遵循上述建议中的任何一两条,都会让你处于更加安全的位置。比如,使用 LLM 来校对你的工作可能会非常有用。我自己就经常这么做。或者,你可以像 Simon Willison 那样,用 LLM 给播客或博文生成摘要,然后再进行编辑。你也可以将它们作为辩论伙伴(这个点子来自 Corey Quinn) 来激发写作灵感。在这些场景中,你的深度参与至关重要,因为错误在所难免。
你也可以利用 LLM 会不可避免地犯错这一特点来实现特定的目的,例如,教开发人员调试技巧。LLM 生成的文本和代码都是文本,它们非常擅长生成看起来合理但有缺陷的代码,而这些缺陷并不总是那么显而易见。
我更关注的是那些容错性较高,甚至以错误为常态的应用场景。当开发人员忘忽略了这一点,将 LLM 生成的内容发送给他人时,往往会遇到麻烦。LLM 可能会引用学术研究,但引用可能并不真实,或者提到不存在的法律先例,但文本看起来却足够合理,以至于律师会将其呈递给法官。
在编程方面,这个问题尤为严重。利用 LLM 输出的代码来教授学生调试技巧是可以的,将其作为一个辅助工具为不太熟练的编程新手提供改进建议也是可以的。但让 LLM 编写用于发布的代码则风险较大。软件开发的核心挑战不在于编写代码本身,而在于沟通、理解和判断力。LLM 无法替代这些人类特质,我见过一些聪明人因此而受到误导。
我经常听到有人宣称这些 AR-LLM 能够进行推理和编码,但实际上它们并不具备真正的推理能力。我问了一个我能想到的最简单的问题,这个问题的答案不可能是它们事先知晓的。我问 ChatGPT 在我的姓名 “Justin Sheehy” 中有多少个字母 “e”,它回答说有 3 个。这显然是不对的。
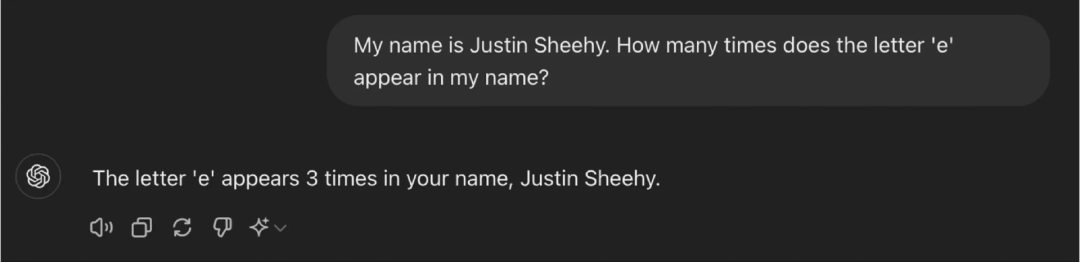
图 3 - ChatGPT 提示词
有人建议再多问几个问题——要求模型展示推理过程,并给出明确的指示——就能获得更好的结果。模型总是显得信心十足,并且会通过展示推理过程来证明它们的答案是多么正确。如果它们真的具备推理或计数能力,这种简单的任务应该是它们的拿手好戏。我尝试用不同的内容问了类似的问题,结果大同小异。
LLM 并不会推理,它们并不是“有时会出错”。它们只是概率性地生成文本,看起来像是推理最可能的“下一步”。有时这些生成的内容恰好是正确的。我们应该根据这一特点合理地地使用它们的输出。
如果我们的角色不只是用户,而是开发者,需要将 AI 集成到我们的系统中,此时该怎么办?此时更应该谨慎对待模型的训练内容。我们可以选择自己训练模型,或者使用基于整个互联网数据训练的大模型的 API。互联网上有丰富的知识,但也充斥着我们不希望在软件中传播的内容。作为负责任的开发者,我们不应该让系统传播互联网上最糟糕的部分。人们往往认为计算机算法给出的答案是客观的,但作为开发者,我们深知“垃圾进,垃圾出”的道理。如果输入的是整个互联网的内容,那么输出的结果可想而知。
这并非假设。开发人员现在就在做出这些选择,他们将预训练语言模型嵌入到系统中,用于做出重要的决策,而这些决策的结果对种族、性别和宗教的影响是可以预见的。我们该如何做出改进?我们可以从测试着手。我们有针对其他软件的测试工具,也可以使用 IBM 开源的 AI Fairness 360 Toolkit 来测试模型是否存在偏见。这还远远不够,但至少是一个好的开始。
另一种不负责任的现象在各种展会的供应商展台上随处可见——那些自称“由 AI 驱动”的产品。这种现象并非无害。
包装 AI 的行为通过炒作 AI 来谋取利益,可能会导致其他系统无法获得所需的资源,这是一种机会成本盗窃,阻碍了其他重要工作的进行。更糟的是,这可能会让人们对算法产生过度的信心,从而错误地做出生死攸关的决策。我们该怎么做?我们可以与 CEO 和产品经理讨论软件系统所能提供的价值。与其在产品中堆砌几个炒作的流行词,不如探讨一下加入 AI 组件是否能带来真正的价值。
AI 时代的责任
无论是集成 LLM 还是构建自己的模型,作为负责任的开发者,我们都需要承担起相应的责任。你的公司对发布的内容负有不可推卸的责任。
什么是责任?由于 LLM 无法被强制不产生幻想,因此你必须准备好对它生成的输出负责。那个让你的公司减员的 AI 聊天机器人可能会导致公司亏损:它们可能会对外提供折扣产品或同意意外退款。确保公司了解系统的功能是你的责任。我们该如何做?我们不应该撒谎或过度承诺,不应该加剧炒作。
如果你无法在合法和安全的框架内完成某项操作,那就不要做。几乎所有人都普遍同意这一观点,但在具体的案例中,我听到了反对意见:“如果我们遵守法律,就无法提供这项服务”;“如果我们花时间确保训练数据中没有儿童色情内容,就无法生成这个图像”;“我们必须侵犯数十万人的权利才能训练出一个庞大的 AR-LLM”。
当然,我不希望阻碍 AI 未来的发展,但为了产品或公司取得成功并不能成为不负责任的借口。不要将你的产品置于他人的安全或权利之上。如果你必须以牺牲他人安全为代价才能发布某个产品,那么就不要发布。AI 研究会继续,并蓬勃发展,但我们也有责任用安全的方式达到这一目标。
对齐
让我们来探讨一下对齐问题,也就是实现 AGI 或通用智能,并确保 AI 与人类的价值观保持一致。这些都是出于善意的构想,但目前仍然停留在科幻范畴。如何实现 AGI?如果真有可能,我们还需要取得多个重大突破。将道德框架融入 AI 或其他技术的开发中是非常重要的。
Anthropic 发表了一篇关于 AI 对齐问题和 AGI 的论文。尽管我不完全认同他们对通用 AI 的发展路径,但他们提出的框架既引人深思又具有实用价值。其核心观点是:如果 AI 能够做到有用、诚实且无害(3H),那么它就实现了与人类的价值观对齐。这样的 AI 只会做对人类有益的事情,只传递准确的信息,并避免造成任何伤害。
你完全可以忽略框架中 “AI” 的部分,直接将其应用于你自己。如果你能够遵循与 AI 对齐框架相一致的行为准则,那么你就已经具备了成为一个负责任的开发者的素质。确保你所创造的东西是有益的,能够解决实际问题。确保你对你所创造的东西保持诚实,不要夸大其词或助长炒作。确保尽可能减少你所构建的东西或构建过程对他人造成伤害。你需要帮助他人,对他人诚实,并减少对他人的伤害。在做出决策时,要将这些人的利益放在心上。
你的责任重大,因为作为开发者,你拥有巨大的影响力,你将有机会参与塑造未来。让我们共同努力,为人类打造一个更加美好的未来。
原文链接:
https://www.infoq.com/articles/responsible-developer-ai-hype/

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论