

本文最初发表于 Towards Data Science 博客,经原作者 Ismael Arayjo 授权,InfoQ 中文站翻译并分享。
这篇文章教你如何使用 Lazy Predict 运行超过 40 个机器学习模型进行回归项目。
假设你需要执行一项回归机器学习项目。你已经分析了你的数据,进行了一些数据清洗,创建了一些虚拟变量,现在,是时候运行机器学习回归模型了。你想到的十大模型有哪些?大多数人可能都不知道有“十大回归模型”。如果你不知道,也不必担心,因为在本文的最后,你不仅可以运行 10 个机器学习回归模型,而且能运行 40 多个机器学习回归模型。
几周前,我在博客上发表了一篇名为《如何用几行代码运行 30 个机器学习模型》(How to Run 30 Machine Learning Models with a Few Lines of Code)的文章,反响非常好。实际上,这是我到目前为止最流行的博文。在那篇博文中,我创建了一个分类项目来尝试 Lazy Predict。现在,我要在一个回归项目测试 Lazy Predict。因此,我将使用典型的西雅图房价数据集,在 Kaggle 上就能找到。
Lazy Predict 是什么?
不需要很多代码,Lazy Predict 就能帮助构建几十个模型,并帮助了解哪些模型在不经过任何参数调整的情况下工作得更好。说明其工作原理的最好方法就是使用一个小项目,现在就开始吧。
回归项目使用 Lazy Predict
首先,要安装 Lazy Predict,你可以pip install lazypredict回归项目到你的终端。简单得很。接下来,让我们导入一些用于本项目的库。你可以在这里找到完整的 Notebook。
你可以看到我导入了pyforest而非 Pandas 和 Numpy。在 Notebook 中,PyForest 可以非常快速地导入所有重要的库。我写了一篇关于它的博文,你可以在这里找到。接下来,让我们来导入数据集。
看看这个数据集是什么样子。

下面我们来检查一下数据类型。
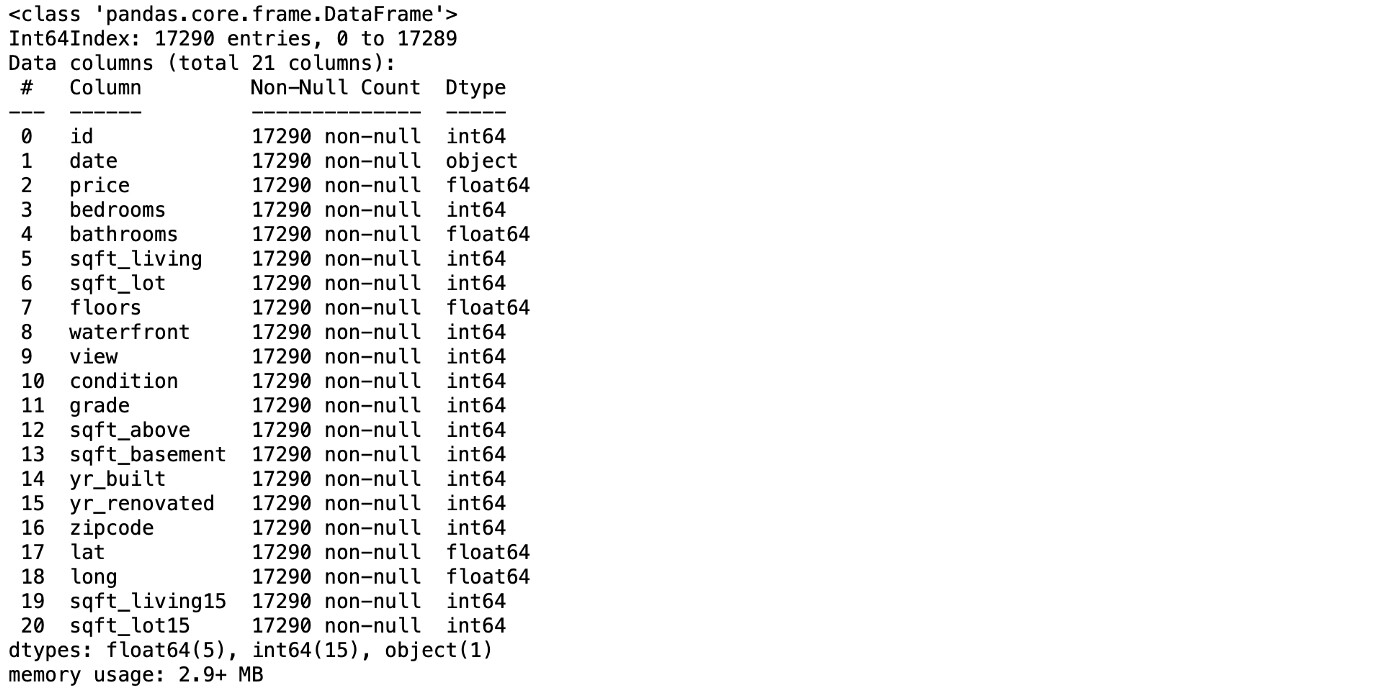
下面是吸引我注意力的几件事情。第一件是id列与这个小项目没有任何关联。但是,如果你想更深入地研究这个项目,你应该检查是否存在重复项。另外,date列是一个对象类型。应将其改为 DateTime 类型。这些列中的zipcode,lat和long可能与价格几乎或者根本没有关联。然而,因为本项目的目标是演示lazy predict,所以我会保留它们。
接下来,在运行第一个模型之前,让我们检查一些统计数据,以找出需要修改的地方。
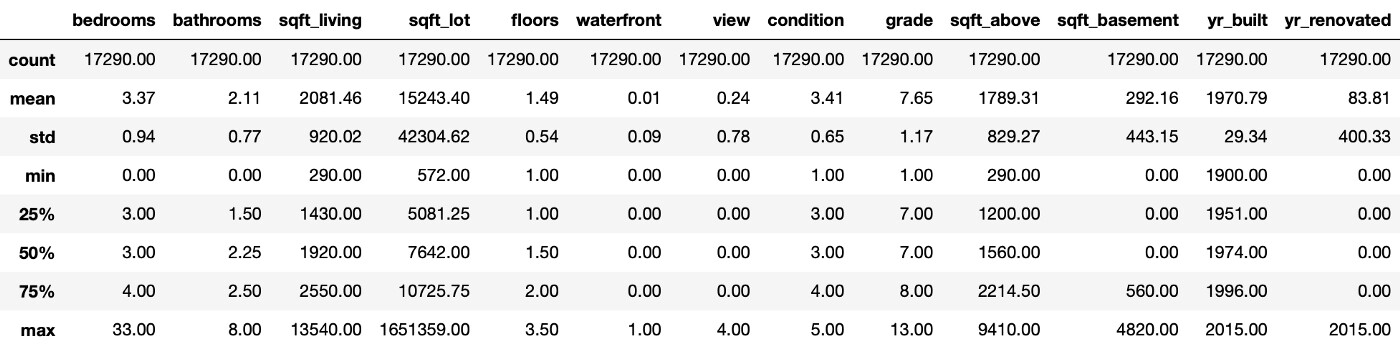
是的,我看到了一些有趣的事情。首先,有一所房子有 33 间卧室,那不可能是真的。所以我在网上查了一下,结果发现我用它的id找到了这套房子,它实际上有 3 间卧室。你可以在这里找到这套房子。此外,有些房子看上去没有卫生间。我会包括至少 1 个卫生间,这样我们就可以完成数据清理了。
拆分训练集和测试集
我们现在可以拆分训练集和测试集了。但是在此之前,让我们确保代码不会出现nan或infinite的值。
现在将数据集分为 X 和 Y 两个变量。我会给训练集分配 75% 的数据集,给测试集 25%。
是时候找点乐子了!下面的代码将运行 40 多个模型,并显示每个模型的 R-Squared 和 RMSE。做好准备,开始!
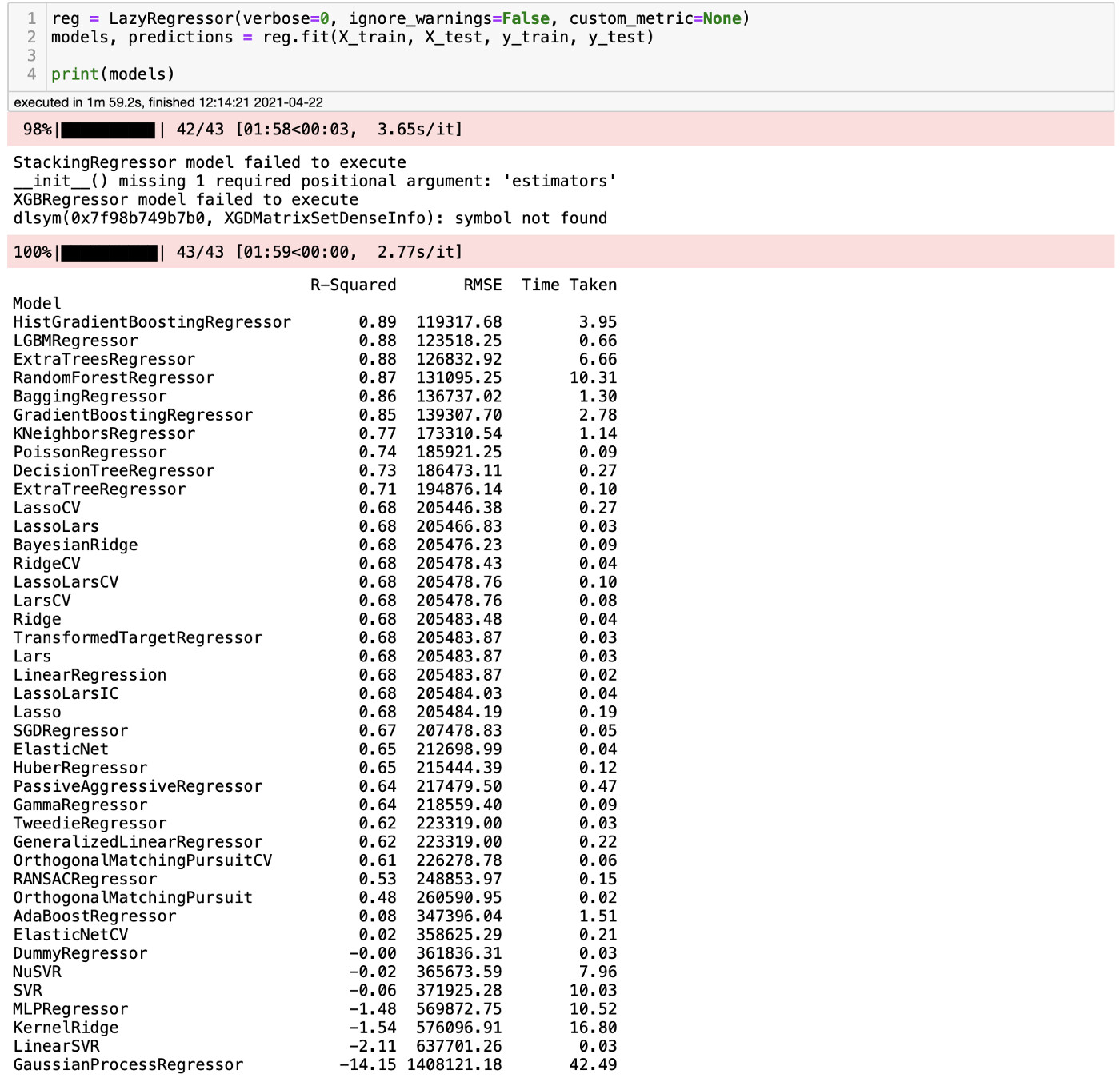
哇!对于花费在上面的工作来说,这些结果非常好。对普通模型而言,这些都是非常好的 R-Squared 和 RMSE。就像我们看到的,我们运行了 41 个普通模型,并且得到了我们需要的指标,你可以看到每个模型所花费的时间。一点也不差。那么,你如何确定这些结果是否正确呢?通过运行一个模型,我们可以查看结果,看它是否和我们得到的结果相近。我们要不要测试一下基于直方图的梯度提升回归树?如果你从未听说过这种算法,不要担心,因为我也从没听说过它。你可以在这里找到一篇关于它的文章。
复核结果
首先,让我们用 scikit-learn 导入这个模型。
此外,我们还创建了一个函数来检查模型的度量。
最后,我们来运行这个模型并查看结果。
瞧!我们用 Lazy Predict 得到的结果和这个结果非常接近。看来这确实很管用。
最后想法
Lazy Predict 是一个神奇的库,易于使用,并且非常快速,只需要很少的代码就可以运行普通模型。你可以使用 2 到 3 行的代码来手动设置,而不需要手工设置多个普通模型。切记,不要把结果作为最终的模型,应该始终对结果进行复核,以确保库工作正常。就像我在其他博文中提到的那样,数据科学是一个复杂的领域,Lazy Predict 并不能取代那些优化模型的专业人员的专业知识。请让我知道它是如何为你工作的。
作者介绍:
Ismael Araujo,在纽约工作,数据科学家、机器学习工程师。
原文链接:
https://towardsdatascience.com/how-to-run-40-regression-models-with-a-few-lines-of-code-5a24186de7d

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论