
本文最初发表于 Cloudflare 网站,经原作者 Marwan Fayed 授权,InfoQ 中文站翻译并分享
IP 寻址技术抑制了大规模运营中面向网络和 Web 服务的创新。对于每个架构变更,开始设计新系统时,我们必须问的第一组问题是:
我们可以使用哪个 IP 地址块?
我们在 IPv4 中有足够的资源吗?若没有,我们从哪里或怎样获得?
我们如何使用 IPv6 地址?这会影响 IPv6 的其他用途吗?
噢,还有,我们需要怎样周密的计划、检查、时间和人力来进行迁移?
不得不停下来担心 IP 地址会耗费时间、金钱和资源。鉴于 40 多年前 IP 的出现具有远见和弹性,这听起来可能令人惊讶。就其设计本身而言,IP 地址应该是任何网络都必须考虑的最后一件事。但是,如果说互联网暴露了什么,那就是那些小的或者看似无关紧要的弱点——在设计时常常看不到或无法看到——总能在足够大的范围内显现出来。
有一件事我们确实知道。“更多的地址”永远不应该是答案。在 IPv4 中,这种想法只会造成地址的稀缺性,从而进一步推高它的市场价格。IPv6 绝对必要,但它只是解决方案的一部分。举例来说,在 IPv6 中,最佳实践表明,仅供个人使用的最小分配是 /56 —— 也就是 2⁷²个或大约 4722000000000000 个地址。这么大的数字我肯定没法推论,你能吗?
在本文中,我们将解释为什么 IP 寻址是 Web 服务的一个问题,它的根源是什么,然后给出了一个创新的解决方案,我们称之为寻址敏捷性,以及我们学到的教训。其中最精彩的部分可能是通过寻址敏捷性启用的新系统和架构。完整的细节可以在我们最新的 ACM SIGCOMM 2021 论文中找到。作为预览,以下是我们所学到的内容的概述。

这是真的!任何一个地址上可以出现的名称的数量没有限制;任何名称的地址可以随着每一个新的查询而改变,无论在何处;而且地址的改变可以出于任何原因进行,比如服务供应、策略或性能评估,或者我们尚未遇到的其他原因……
以下说明了为什么所有这些都是事实,如何实现,以及这些经验对于任何规模的 HTTP 和 TLS 服务都非常重要。我们建立的关键洞察力是:与全球邮政系统一样,在互联网协议(IP)的设计中,地址从来没有、永远不应该、也永远不需要代表名称。我们只是有时把地址当作是这样的。相反,这项工作表明,所有的名称都应该共享所有的地址,任何一组地址,甚至只有一个地址。
“窄腰”是漏斗,也是瓶颈
几十年来的惯例人为地将 IP 地址与名称和资源联系起来。这种情况是可以理解的,因为驱动互联网的架构和软件是从一台计算机有一个名称和(最常见的)一个网络接口卡的环境中发展起来的。因此,互联网的发展使得 IP 地址与名称和软件进程相关联是很自然的。
而终端用户和网络运营商对名称的需求不大,对监听进程的需求也不大,这些 IP 绑定的影响不大。但是,名称和进程约定对于所有的内容托管、分发和内容服务提供商(CSP)都有严格的限制。当名称、接口和套接字被分配后,地址就基本上是静态的,如果有可能改变的话,就需要努力、计划和谨慎。
IP 的“窄腰”使互联网得以实现,但正如 TCP 是传输协议和 HTTP 是应用协议,IP 已经成为创新的瓶颈。下图描述了这一想法,在图中我们看到,原本独立的通信绑定(带有名称)和连接绑定(带有接口和套接字)在它们之间建立了传递关系。
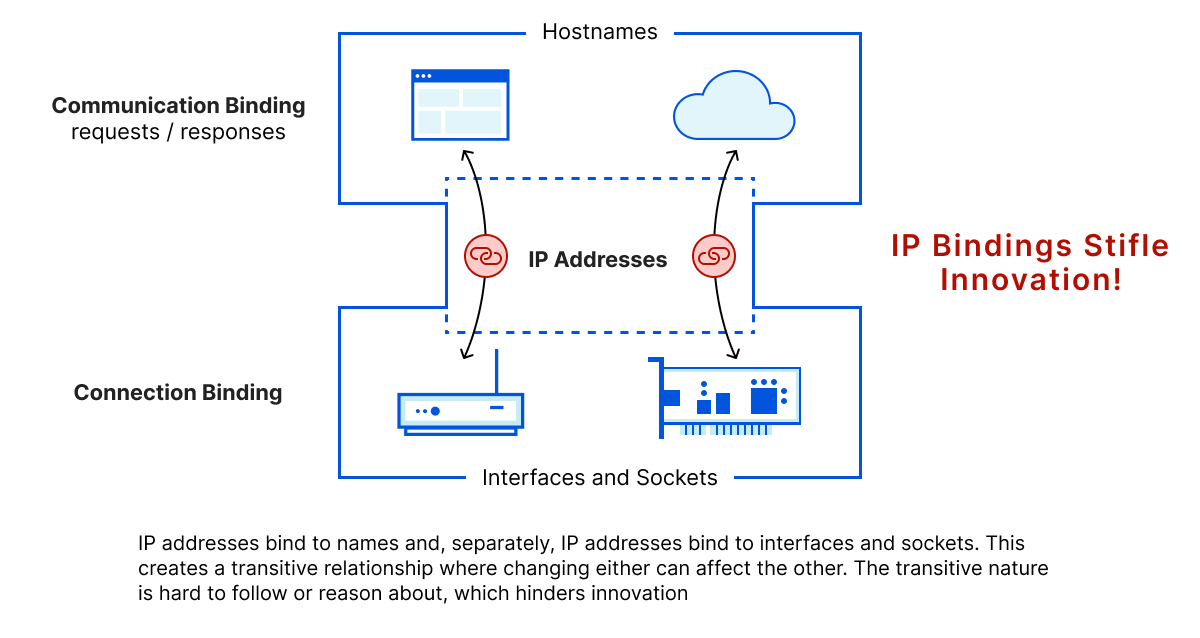
传递性锁很难被打破,因为任何一方的改变都会对另一方产生影响。另外,服务提供商经常用 IP 地址来表示政策和服务级别,而这些政策和服务级别本身就是独立于名称而存在的。归根结底,IP 绑定是另一件需要考虑的事情,并且没有什么好的理由。
咱们换个说法。在考虑新的设计、新的架构或者仅仅是更好的资源分配时,首要的问题绝不应该是“我们使用哪些 IP 地址?”或者“我们有这个 IP 地址吗?”之类的问题及其回答会延缓发展和创新。
我们意识到,IP 绑定不仅仅是人为的,而且根据最初有远见的 RFC 和标准,也是不正确的。实际上,将 IP 地址作为可达性之外的代表的概念与其最初的设计相悖。在最初的 RFC 和相关的草案中,架构师们明确指出:“名称、地址和路由之间是有区别的。名称表明我们所寻找的东西。地址表明它在哪里。路由表明如何到达那里。”在较高层协议中,任何 IP 信息(例如 SNI 或 HTTP 主机)的任何关联都明显违反了分层原则。
毫无疑问,我们的工作中没有一项是孤立存在的。但是,它确实完成了将 IP 地址与其传统用途脱钩的长期演变,这种演变包括站在巨人的肩膀上。
演变中的过去
回首过去 20 年,我们不难发现,寻求寻址敏捷性的方法已经有一段时间了,Cloudflare 在这个领域的投入是巨大的。
当谷歌的 Maglev 在几年前就将等价多径(Equal Cost MultiPath,ECMP)和一致哈希(consistent hashing)技术结合起来,在许多服务器之间传播来自一个“虚拟” IP 地址的流量时,从而打破了 IP 和网卡接口之间几十年来一对一绑定的局面。顺带一提,根据最初的互联网协议 RFC,IP 的这种使用是被禁止的,而且不具有任何虚拟性。
从那时起,GitHub、Facebook 等地方就出现了很多类似的系统,包括我们自己的 Unimog。近来,Cloudflare 设计了一种叫做 bpf_sk_lookup 的可编程套接字架构,使 IP 地址与套接字和进程解耦。
但是那些名称呢?1997 年,HTTP 1.1 将主机字段定义为必须的时候,“虚拟主机”的价值得到了巩固。这是官方第一次承认多个名称可以共存于一个 IP 地址上,并且必须由 TLS 在服务器名称指示字段中复制。这些都是绝对的要求,因为可能的名称的数量比 IP 地址的数量多。
……预示了敏捷的未来
展望未来,莎士比亚明智地问道:“名字代表什么?”假如互联网能够说话,那么它可能会说:“我们用任何其他地址标记的名字都一样可以到达。”
假如莎士比亚反问:“地址代表什么?”然后互联网也会这样回答:“我们用任何其他名字标记的地址也一样可以到达。”
这一点很有说服力地暗示了这些答案的真相:名称和地址之间的映射是任意对任意的。如果这是真的,那么只要一个名称在一个地址可以到达,任何地址都可以用来到达一个名称。
事实上,自 1995 年以来,由于采用了基于 DNS 的负载均衡技术,一个名称的许多地址的版本就已经可用。所以,为什么不为所有的名称提供所有的地址,或者在任何给定的时间为所有的名称提供任何地址呢?或者,正如我们很快就会发现的,一个地址代表所有的名称! 但是,让我们先来谈谈实现寻址敏捷性的方式。
译注:莎士比亚在《罗密欧与朱丽叶》中有一句名言:“名字代表什么?我们所称的玫瑰,换个名字还是一样芳香。”(What's in a name? That which we call a rose / By any other name would smell as sweet.)
实现寻址敏捷性:忽略名称,映射策略
寻址敏捷性的关键是权威的 DNS:但不是存储在某种形式的记录或查询表中的静态名称到 IP 的映射。鉴于从任何客户的角度来看,绑定只出现在“查询时”。对映射的所有实际用途来说,查询的响应是一个请求的生命周期的最后一个可能的时刻,在这个时刻,名称可以被绑定到地址。
这样就可以看到,名称映射并不真正发生在某个记录或区域文件中,而是在响应返回时发生。这一区别很小,但是很重要。现在的 DNS 系统用过一个名称来找一组地址,然后有时使用一些策略来决定返回哪个具体地址。这一想法如下图所示。在查询到达时,查询会显示与该名称相关的地址,然后返回其中的一个或多个地址。一般而言,额外的策略或逻辑过滤器用于缩小地址选择范围,例如服务级别或地理区域覆盖。关键在于,在应用策略之前,地址首先被识别为名称。
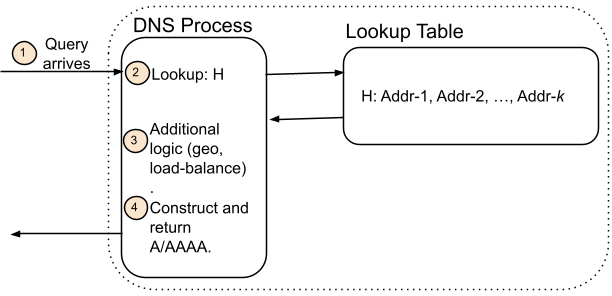
(a)常规权威 DNS
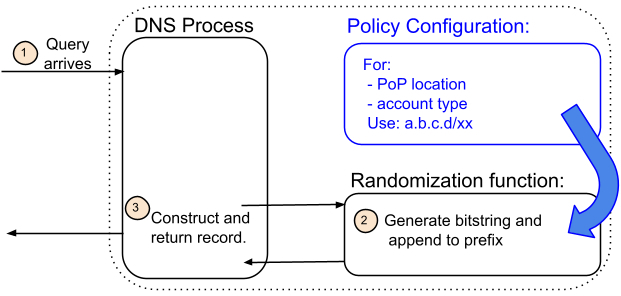
(b)寻址敏捷性
通过颠倒这个关系,寻址敏捷性得以实现。我们的架构不是将 IP 地址预先分配给一个名称,而是从一个可能(或在我们的案例中,不包括)包括一个名称的策略开始。举例来说,一个策略可以由诸如位置和账户类型等属性表示,而忽略名称(我们在部署中就是这样做的)。这些属性决定与该策略相关的地址池。这个池本身可能独立于该策略,也可能有与其他池和策略共享的元素。此外,池中的所有地址都是等效的。也就是说,可以返回任意的地址(甚至可以随机选择)而无需检查 DNS 查询名称。
现在暂停一下,因为每一个查询响应中都会出现两个真正值得注意的影响:
可以在运行时或查询时计算和分配 IP 地址。
IP 到名称映射的生存期是随后的连接生存时间和下游缓存中的 TTL 中较大的一个。
其结果是强大的,意味着绑定本身是短暂的,无需考虑之前的绑定、解析器、客户端或目的即可进行更改。另外,规模也不是问题,我们知道,因为我们把它部署到了边缘。
IPv6,皇帝的新衣
讨论部署之前,先来解决“房间里的大象”问题:IPv6。首先要明确的是,在本文讨论的 IPv4 环境中的一切都适用于 IPv6。就像全球邮政系统一样,地址就是地址,不管是在加拿大、柬埔寨、喀麦隆、智利还是中国,这包括它的相对静态和缺乏弹性。
除了存在等价性之外,还有一个显而易见的问题:仅仅改用 IPv6 就能满足所有寻求寻址敏捷性的理由吗?虽然答案可能是反直觉的,但答案是肯定的、绝对的否定!IPv6 可能会缓解地址枯竭的问题,至少在今天所有人的有生之年是这样。但是由于 IPv6 前缀和地址的丰富特性,很难推理其余名称和资源的绑定。
大量 IPv6 地址的使用还会带来低效风险,因为运营商可以利用位长和大前缀的优势,将意义嵌入到 IP 地址中。这是 IPv6 的一项强大功能,但同时也意味着任何前缀中的许多地址都将会闲置。
明确地说,Cloudflare 显然是 IPv6 的最大倡导者之一,并且有充分的理由,特别是地址的丰富性确保了寿命。即便如此,IPv6 并没有改变地址与名称和资源绑定的方式,而寻址敏捷性则确保了它在生命周期中的灵活性和响应性。
附带说明:敏捷是为每个人准备的
对架构和它的可转移性的最后一点说明——对于任何运营权威 DNS 的服务,寻址敏捷性是可用的,甚至是理想的。其他以内容为导向的服务供应商显然是竞争对手,但小型运营商也是如此。大高校、企业和政府只是一些可以运营自己权威服务的机构的例子。只要返回的 IP 地址上的连接能够被运营商接受,所有的人都有可能因此成为寻址敏捷性的受益者。
基于策略的随机地址——大规模
自 2020 年 6 月以来,我们就一直在努力解决生产流量边缘的敏捷性问题,具体如下:
超过 2000 万个主机名和服务;
所有加拿大的数据中心(人口合理,具有多个时区);
IPv4 的/20(4096 个地址)和 IPv6 的/44;
2021 年 1 月至 2021 年 6 月 IPv4 的/24(256 个地址);
对于每一个查询,都会在前缀中生成一个随机的主机部分。
要知道,当每次点击服务器上的查询都会产生随机的地址时,真正测试敏捷性的方法是极端的。我们决定把这个想法真正付诸实施。2021 年 6 月,在我们的蒙特利尔数据中心,不久之后在多伦多,超过 2000 万个区域都被映射到一个单一的地址。
每一次针对策略所捕获的域名的查询,在一年内都会得到一个随机选择的地址:从一个少至 4096 个地址的集中,然后是 256 个,然后是 1 个。在内部,我们把 1 的地址集称为 Ao1,我们将在后面回到这一点。
衡量成功的标准:“没有什么可看的”
我们的读者可能会悄悄地问自己一些问题:
这对互联网造成了什么“破坏”?
这对 Cloudflare 系统有什么影响?
如果有可能,我将会看到什么?
对上述每个问题的简短回答是没有。不过,有一点非常重要,地址的随机化的确暴露了依赖互联网的系统设计中的弱点。这些弱点总是会出现,是因为设计者赋予 IP 地址的意义超出了可达性。(而且,如果只是偶然,这些弱点中的每一个都是通过使用一个地址,或 "Ao1 "来规避的)。)
要更好地理解“没有”的本质,让我们从列表的底部开始回答上述问题。
如果有可能,我将会看到什么?
下图中的例子说明了答案。对一个区域的查询从我们部署之外的“世界其他地区”的所有数据中心返回相同的地址(这就是 Cloudflare 的全球任播系统)。相比之下,每一个进入部署数据中心的查询将接收一个随机的地址。以下是对两个不同的数据中心的连续 dig 命令,可以看出这一点。

如果你想了解后续请求的流量,是的,那就意味着服务器被配置成接受对地址池所有地址中的 2000 多万个域名中的任何一个的连接请求。
好吧,Cloudflare 的周边系统肯定需要修改吗?
不是的。它直接透明地改变了权威 DNS 的数据管道。每一个路由前缀在 BGP、DDoS、负载均衡器、分布式缓存中,没有一个需要改变的。
但是,有一个迷人的副作用:随机化对于 IP 地址来说,就像一个好的哈希函数对于哈希表一样:它将任意大小的输入均匀地映射到一个固定数量的输出。通过观察随机化前后每个 IP 负载的测量,可以看到这种效果,如下图所示,数据取自一个数据中心 7 天内 1% 的请求样本。
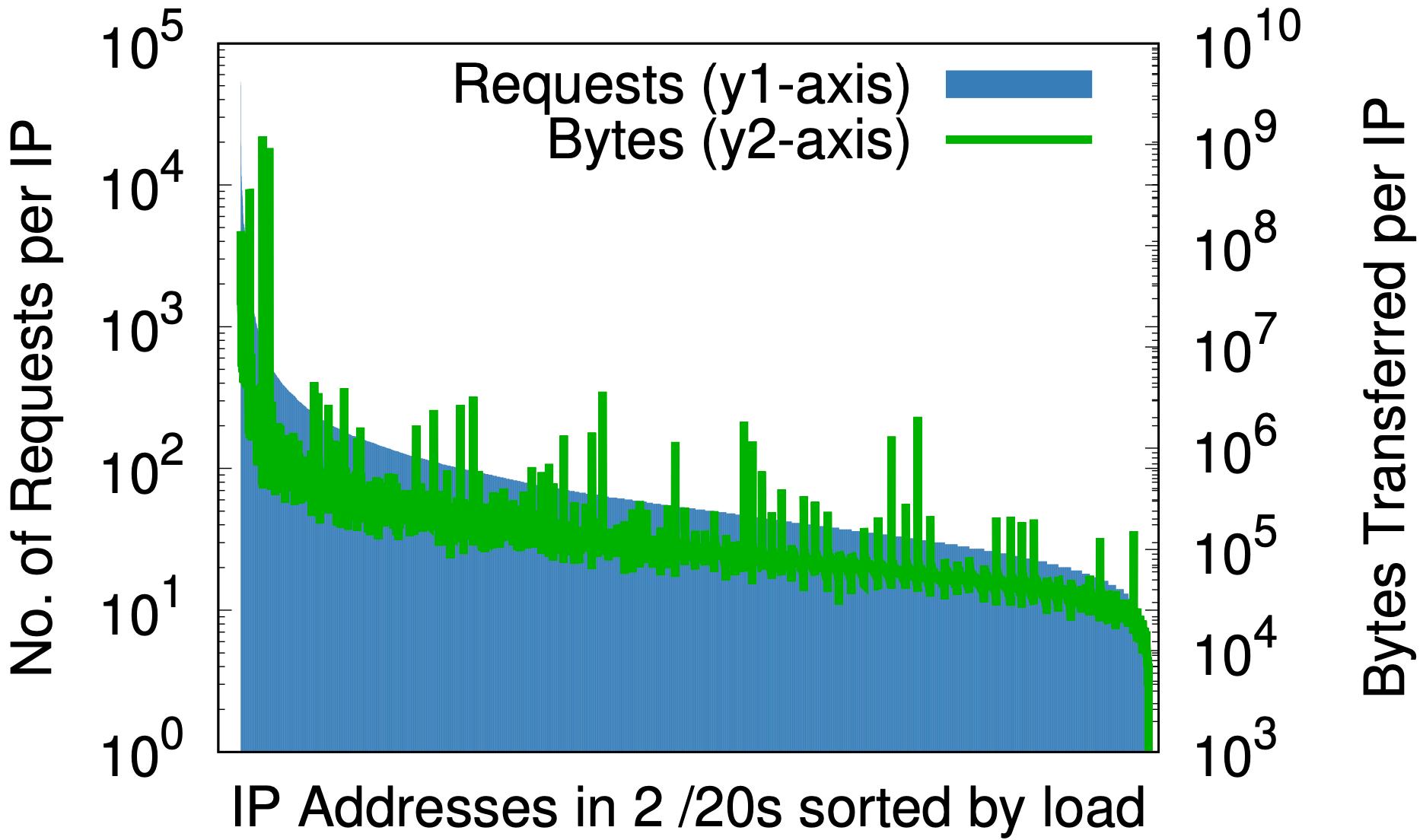
寻址敏捷性之前
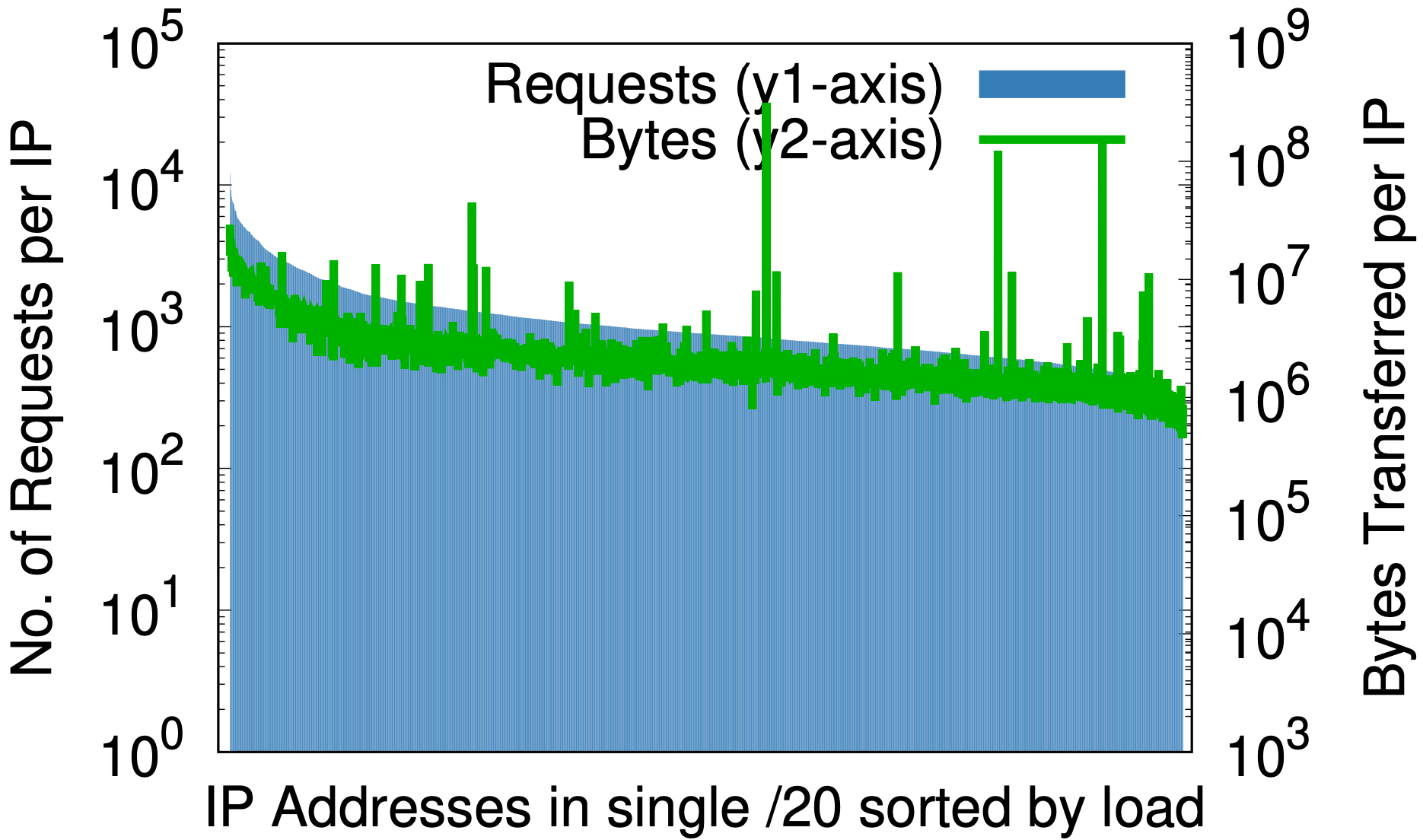
/20 随机化
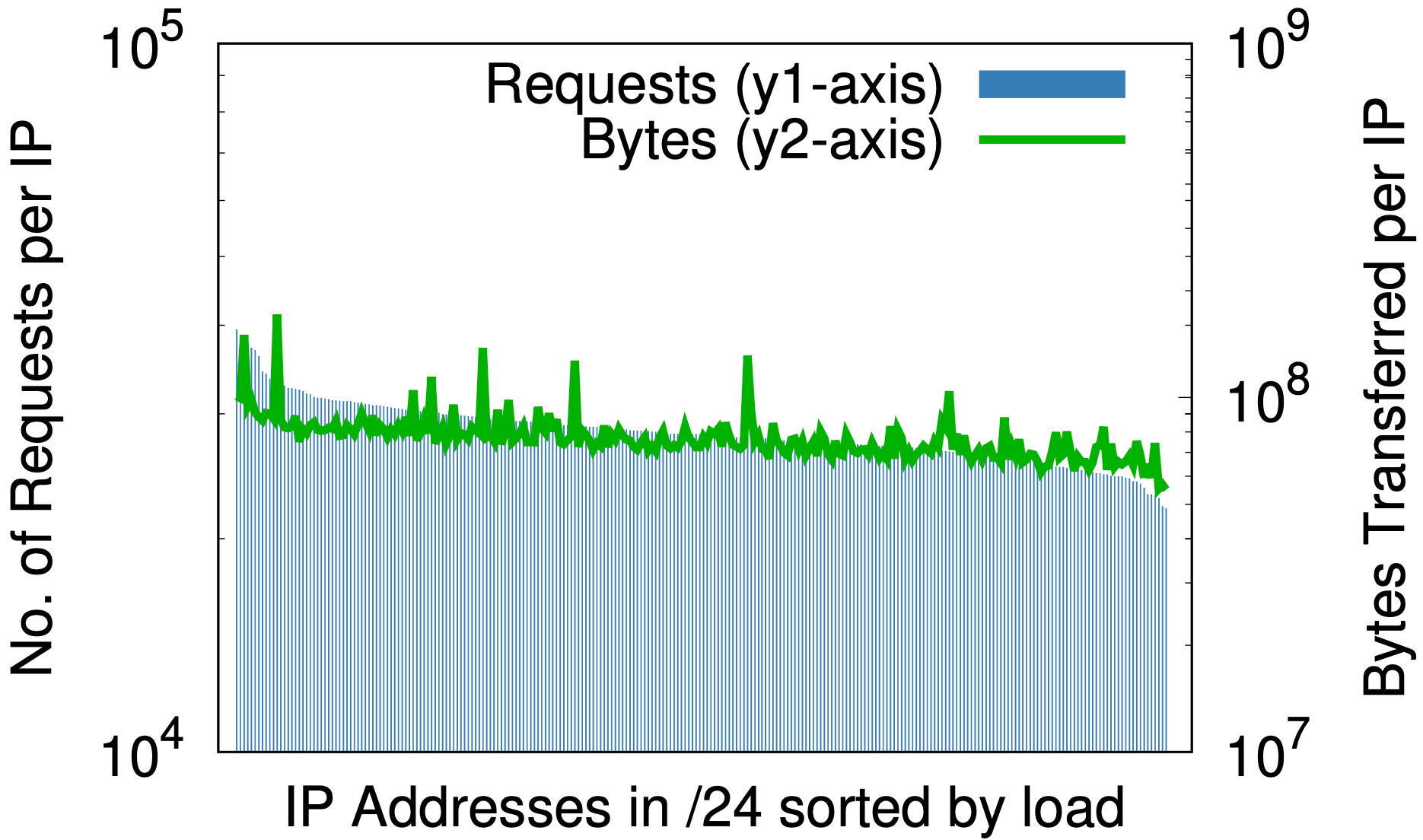
/24 随机化
在随机化之前,对于 Cloudflare 的 IP 空间的一小部分,(a) 每个 IP 的最大和最小请求之间的差异(左边的 y1 轴)是 3 个数量级;同样,每个 IP 的字节数(右边的 y2 轴)几乎是 6 个数量级。在随机化之后,(b)对于以前占据多个 /20 的单一 /20 上的所有域,这些分别减少到 2 和 3 个数量级。在 (c) 中,进一步下降到 /24,将 2000 多万个区随机化到 256 个地址上,从而将负载的差异降低为小的常数因子。
对于任何考虑按 IP 地址提供资源的内容服务提供商来说,这一点非常重要。先验预测用户产生的负载是很困难的。上面的图表表明,最好的方法就是将所有的地址都赋予名称。
这肯定在更广泛的互联网上“破坏”了一些东西?
在这里,答案也是否定的!好吧,也许更确切地说,“不,随机化不会破坏任何东西……但是它能暴露系统及其设计中的弱点。”
受地址随机化影响的任何系统似乎都有一个坚决条件。
任何可能受到地址随机化影响的系统似乎都有一个先决条件:赋予 IP 地址的意义不仅在于可达性。寻址敏捷性使 IP 地址和互联网的核心架构的语义得以保持甚至恢复,但是它会破坏对其意义作出假设的软件系统。
先来看几个例子,说明为什么这些问题并不重要,然后再介绍一种绕过弱点(通过使用一个单一的 IP 地址)的解决敏捷性小变化的方法:
HTTP 连接聚合(connection coalescing)允许客户端重新使用现有的连接来请求来自不同来源的资源。像 Firefox 这样的客户端,在 URI 授权与连接相匹配时,允许聚合使用的客户端不会受到影响。但是,要求 URI 主机解析到与给定连接相同的 IP 地址的客户端将会失败。
非 TLS 或基于 HTTP 的服务可能会受到影响。一个例子是 ssh,它在其 know_hosts 中保留了一个主机名到 IP 的映射。这种关联虽然可以理解,但是已经过时了,考虑到目前很多 DNS 记录都会返回一个以上的 IP 地址,这种关联已经被打破。
非 SNI TLS 证书需要一个专用 IP 地址。供应商被迫收取一定的费用,因为每个地址只能支持一个没有 SNI 的证书。独立于 IP 的更大的问题是在没有 SNI 的情况下使用 TLS。我们已经开始试图了解非 SNI,并希望结束这一不幸的遗产。
依靠目的地 IP 的 DDoS 保护最初可能会受到阻碍。我们认为,由于两个原因,寻址敏捷性是有益的。首先,IP 随机化将攻击负载分布在所有使用的地址上,有效地充当了第三层的负载均衡器。第二,DoS 缓解措施通常是通过改变 IP 地址而起作用的,该功能是寻址敏捷性所固有的。
人人为我,我为人人
我们从数以万计的地址绑定的 2000 多万个区域开始,从 /20 中的 4096 个地址和 /24 中的 256 个地址成功为它们提供了服务。这一趋势自然会引出以下问题:
如果随机化在 n 个地址上有效,那么为什么不在 1 个地址上进行随机化呢?
确实,为什么不呢?回想一下上面关于 IP 随机化的评论,认为它等同于哈希表中的完美哈希函数。设计良好的基于哈希的结构的特点是,对于任何大小的结构,即使是大小为 1 的结构,它们都保留了自己的属性。这种减少将是对构建寻址敏捷性的基础的真正测试。
因此,我们进行了测试。从一个 /20 地址集,到一个 /24,然后,从 2021 年 6 月起,到一个 /32 的地址集,等于是一个 /128(Ao1)。这不仅仅是行之有效。这确实起作用了。Ao1 解决了可能因随机化而暴露出来的问题。举例来说,非 TLS 或非 HTTP 服务具有可靠的 IP 地址(或者至少是非随机的,而且名称还没有发生策略变化)。另外,HTTP 连接聚合就像免费的一样,是的,我们看到在使用 Ao1 的地方,聚合水平在提高。
但 IPv6 中的地址为何如此之多?
反对与单一 IPv6 地址绑定的一个论点是,没有必要,因为地址不可能用尽。我们认为,这是 cidr 之前的立场,往好里说是良性的,往坏里说是不负责任的。如上所述,IPv6 地址的数量使得对其进行推理非常困难。与其问为什么要使用单一的 IPv6 地址,不如问“为什么不呢?”
是否存在上游影响?是的,还有机会!
Ao1 从 IP 随机化中揭示了一套完全不同的含义,可以说,它通过放大看似微不足道的行动可能带来的影响,为我们提供了一扇了解互联网路由和可达性未来的窗口。
为什么?宇宙中可能的可变长度名称的数量永远超过固定长度的地址的数量。这意味着,根据鸽巢原理(pigeonhole principle),单个 IP 地址必须由多个名称共享,并且是来自不相关方的不同内容。
由 Ao1 放大的可能的上游效应值得提出,并将在下文中加以说明。不过,到目前为止,我们并没有在评估中看到这些情况,在上游网络的沟通中也是如此。
上游路由错误是即时和全面的。假如所有流量都到达一个地址(或前缀),那么上游的路由错误将对一切产生同样的影响。(这就是 Cloudflare 在非相邻地址范围内返回两个地址的原因)。)但是,请注意,威胁阻断也是如此。
上游 DoS 保护措施可能被触发。可以想象,集中在一个地址上的请求和流量可能会被上游视为 DoS 攻击,从而触发可能存在的上游保护措施。
无论哪种情况,这些操作都会减轻,因为寻址敏捷性能足够快速地大规模更改地址。还可以预防,但需要公开沟通和讨论。
最后一个上游效应仍然存在:
在 IPv4 NAT 中,端口耗尽有可能会被加速,IPv6 可以解决这一问题!从客户端来看,一个地址所允许的并发连接数量取决于传输协议的端口字段的大小,例如,在 TCP 中约为 65K。
例如,在 Linux 上的 TCP 中,直到最近,这还是一个问题。(见此提交 和 ip(7) man page 中的 SO_BIND_ADDRESS_NO_PORT)。 在 UDP 中,这个问题仍然存在。在 QUIC 中,连接标识符可以防止端口耗尽,但它们必须被使用。不过到目前为止,我们还没有看到任何证据表明这是个问题。
即便如此——也是最好的部分——就我们所知,这是唯一一个使用一个地址的风险,而且迁移到 IPv6 就可以立即得到解决。(所以,ISP 和网络管理员们,快去实施 IPv6 吧!)
我们才刚刚开始!
我们就这样结束了,就像我们开始的那样。由于对任何单一 IP 地址上的名字数量没有限制,能够以任何理由按查询改变地址,你能建立什么?

实际上,我们才刚刚开始!由于寻址敏捷性所带来的灵活性和面向未来的特点,我们可以想象、设计和构建新的系统和架构。我们计划为任播系统、测量平台等进行 BGP 路由泄漏检测和缓解。
关于以上内容的更多技术性细节,可以在论文和简短的谈话中找到。即使有了这些新的可能性,挑战依然存在。存在很多开放的问题,其中包括但不限于:
哪些策略可以合理表达或实施?
是否有一种抽象的语法或文法来表达它们?
对于错误的或冲突的策略,我们能否使用正式的方法和验证吗?
作者介绍:
Marwan Fayed,Cloudflare 研究主管。
原文链接:




