写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 聚类算法 频道下的 50 篇内容
Olivier Bachem等人在其NIPS 2016(Neural Information Processing Systems,神经信息处理系统大会,机器学习领域的顶级会议之一)的文章“Fast and Probably Good Seedings for k-Means”中提出了AFK-MC²算法,该算法改进了k-Means算法中初始种子点的生成方式,使其聚类速度相较于目前最好的k-Means++方式提高了好几个数量级。

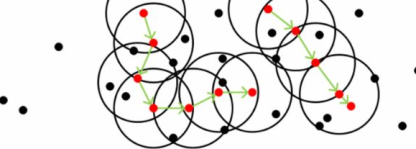
俗话说的:“物以类聚,人以群分”。聚类是一个把数据对象划分成子集的过程,每个子集是一个簇(cluster),使得簇中的对象彼此相似,但与其他簇中的对象不相似。聚类成为自动分类,聚类可以自动的发现这些分组,这是突出的优点。

聚类是数据挖掘中的一个概念,是按照某个特定标准(如距离)把一个数据集分割成为不同的类或者簇,使得同一个类内的数据对象的相似性尽可能大,同时不在同一个类内的数据对象的差异性也尽可能得大。即聚类后的同一类数据尽可能聚集到一起,不同类的数据尽量分

无监督学习和聚类算法是人工智能领域中的重要分支,它们在没有明确标签的情况下,通过分析数据的内在结构和模式,实现信息的自动组织和分类。本文将深入讨论无监督学习的基本概念、聚类算法的原理及应用,以及在数据科学领域中的关键作用。


在本案例中,我们使用人工智能技术的聚类算法去分析超市购物中心客户的一些基本数据,把客户分成不同的群体,供营销团队参考并相应地制定营销策略。

本次分享主要介绍腾讯在热点挖掘方面的工作。基于搜索数据和自媒体文章,通过时序分析方法和内容聚类相结合的方法挖掘热点,并将热点聚类成事件和话题。

北京邮电大学邓伟洪教授团队的研究揭示了当前人脸识别算法中普遍存在跨国家/地区识别偏差问题,并构建了评价偏差程度的人脸数据集RFW。

为了保证系统、服务的可靠性和稳定性,监控系统日渐成为每个公司、企业的一个必不可少的系统。随着服务、机器等数量越来越多,如何分析海量时间序列KPI成为我们在智能运维领域首先需要解决的问题。

无监督图像分类问题是图像分类领域一项极具挑战的研究课题,本文介绍了无监督图像分类算法的发展现状,供参考学习。

说话人分类,即从包含多个说话人声音的音频流中,单独将每个人的音频划分到同一类别下的过程,是语音识别系统的重要部分。通过解决“谁在何时说话”的问题,说话人分类可以应用于许多重要场景,例如理解医疗对话、视频字幕等。

在本教程中,我将使用 K-均值(K-Means)聚类算法在 FIFA 20 将技能相似的球员进行分组。

本文阐述了理解机器学习算法内部工作原理的重要性,以及它在实现和评估方面的不同之处。
过去十年里,从大量原始数据中解析出相关信息的需求急剧增长,以致于聚类(clustering)、协同过滤(collaborative filtering)和分类(categorization)等机器学习技术的需求也是呈稳定增长势态。Apache Mahout 0.3于三月份推出,这个新版本在之前的基础上添加了一些新功能,比之前的版本更为稳定,性能也有相应的提升。

我们可能会忽略一些算法背后的关键概念或思想,而这些概念或思想对于这些算法的理解是必不可少的。
随着国外的facebook、twitter以及国内的人人、新浪微博等SNS及内容分享平台的逐步流行,如何从上亿的海量用户中自动挖掘兴趣圈子成为了一个有趣也非常必要的工作。本文讲述了在SNS平台下,如何对海量数据自动进行兴趣圈子挖掘。
 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质











