
Facebook 的人工智能研究团队公布了他们最新的神经网络机器翻译(NMT)研究成果。同时进行三个机器翻译任务,他们的算法比其他任何一个系统的得分都要高,而且比Google 的NMT 系统快上9 倍。
Facebook 使用了卷积神经网络,该技术在计算机视觉领域得到广泛应用。它以一种结构化的顺序来处理句子,捕捉句子成分之间复杂的关系。Facebook 对计算机进行训练,让它们能够识别出句子(由两个、三个、四个或更多的单词组成)各个部分的含义。通过使用神经网络来处理句子,计算机可以理解句子各个部分的含义。然后使用另一种神经网络将这些意思转译成另外一门语言。
卷积的主要优势在于,你可以同时将其应用在句子的多个成分上。传统的NMT 技术逐字地读取句子,然后记下句子在当前位置的意思。计算机的速度限制了串行化读取的速度,结果就是Facebook 的算法可以比串行化读取技术最多快上9 倍。
他们还引入一种新的技术,叫作“multi-hop”。这种技术并不是整句地读取然后整句地翻译,而是进行逐字翻译。multi-hop 是一种新技术,比“专注”(attention)机制更智能、更复杂。专注机制是解决多义词问题的关键。一个单词在不同的上下文里具有不同的含义。在翻译一个单词的时候,专注机制根据原文的相关部分为单词选择最合适的释义,从而解决多义词问题。
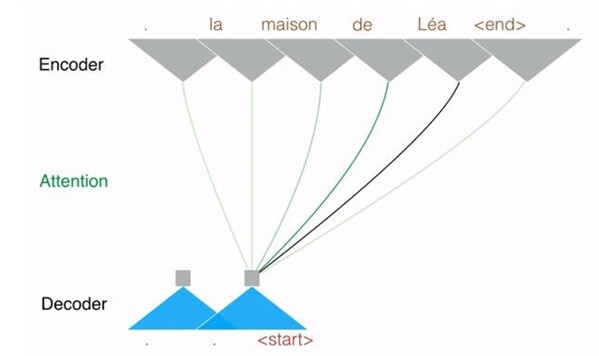
Facebook 打算将他们的新技术应用在其他文字处理任务上,比如使用神经网络来回答问题。新技术可以让他们同时专注于对话的每一个部分。他们在博客上完整地介绍了他们的新技术,还有一份可以自由访问的论文。如果有人想尝试他们的算法,可以从 GitHub 下载代码。
在进行英语到法语、英语到德语和英语到罗马尼亚语的翻译时,新算法比其他任何一个算法都要快。它打败了 Google 的神经网络机器翻译技术。 Google Translate SDK 提供了 Google 的翻译算法,可以支持 20 种语言互译组合。如果有人想知道 NMT 和传统技术之间的区别,可以试着使用 Microsoft Translator 来翻译他们喜欢的内容。
查看英文原文: Facebook Publishes New Neural Machine Translation Algorithm

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论