
当项目中在使用到诸如 Elasticsearch 的中间件时,客户端对不同数据模型的 CRUD 操作存在着大量模版式的冗余代码,每次有新的业务数据需要 Elasticsearch 的管理时都会重写类似的 CRUD 逻辑,这些 CRUD 代码除了数据模型不同,通用功能的代码逻辑几乎一样。显然,在这种情况下,我们完全可以抽取出通用功能的代码,将其定义成一个模版。当接入具体的业务数据时,只需要进行模版实例化的代码书写,把因业务不同的数据模型嵌入到模版中,从而避免重复书写功能相同的代码,最终达到提高开发效率,降低开发成本的目的。
在实际的项目开发中,如何解决模板式的冗余代码?
首先,考虑到 Java 语言以及 ElasticSerarch 在项目开发中的普及性,我选择基于 Java 语言使用 Elasticsearch 的技术场景来澄清以及解决模板式的代码冗余问题。
其次,为了使得问题的澄清和解决更具象化,我以简单的用户信息和订单信息为例,来阐述澄清和解决问题的具体过程。
那么,我们先定义一下简单用户信息和订单信息的数据模型:
/** * 简单用户信息数据模型。 */public class UserInfo { private String id; // ID private String nickName; // 昵称 private Integer age; // 年龄 private String introduction; // 简介 private String signature; // 签名}/** * 简单订单信息数据模型。 */@Datapublic class OrderInfo { private String id; private String productId; // 产品 ID private Integer productNum; // 产品数据量 private Integer status; // 订单状态 private String remark; // 备注}什么是模板式的冗余代码?
接下来,我们澄清一下模版式的冗余代码问题。
当用户信息和订单信息接受 Elasticsearch 的管理时,直接使用 Elasticsearch 客户端 API 创建索引的代码如下:
/** * ES 创建用户信息文档。 */public ServiceResponse<Boolean> create(UserInfo userInfo) { // 参数检查逻辑。 String userInfoId = userInfo.getId(); if (StringUtils.isEmpty(userInfoId)) { return ServiceResponse.FAIL_RESPONSE; } // 创建索引请求。 IndexRequest indexRequest = new IndexRequest("user_info_index", "user_info_type", userInfoId); String documentData = JSON.toJSONString(userInfo); indexRequest.source(documentData, XContentType.JSON); indexRequest.opType(DocWriteRequest.OpType.INDEX); // 调用客户端 API。 try { InitESRestClient.getClient().index(indexRequest, RequestOptions.DEFAULT); } catch (Exception e) { log.error("error when save document:{}.", JSON.toJSONString(userInfo), e); return ServiceResponse.FAIL_RESPONSE; } return ServiceResponse.SUCCESS_RESPONSE;}/** * ES 创建订单信息文档。 */public ServiceResponse<Boolean> create(OrderInfo orderInfo) { // 参数检查逻辑。 String orderInfoId = orderInfo.getId(); if (StringUtils.isEmpty(orderInfoId)) { return ServiceResponse.FAIL_RESPONSE; } // 创建索引请求。 IndexRequest indexRequest = new IndexRequest("order_info_index", "order_info_type", orderInfoId); String documentData = JSON.toJSONString(orderInfo); indexRequest.source(documentData, XContentType.JSON); indexRequest.opType(DocWriteRequest.OpType.INDEX); // 调用客户端 API。 try { InitESRestClient.getClient().index(indexRequest, RequestOptions.DEFAULT); } catch (Exception e) { log.error("error when save document:{}.", JSON.toJSONString(orderInfo), e); return ServiceResponse.FAIL_RESPONSE; } return ServiceResponse.SUCCESS_RESPONSE;}为了让大家更清晰地关注到代码中的重点,这里说明一下代码上的约定:
ServiceResponse 是一个通用的业务对象,用来表达业务逻辑执行成功或失败的信息;
InitESRestClient.getClient() 用来获取默认的 Elasticsearch 集群客户端;
其他未特别说明的都是标准的 Java 语言和 Elasticsearch 客户端 API。
从上面的代码我们可以看出,无论对于用户信息的索引创建还是订单信息的索引创建,我们无可避免地要写参数检查、创建索引请求、调用客户端 API 的相同逻辑。这些逻辑的代码看着似乎都是不一样的,但整体的逻辑都是相同的,就像是一个执行流程的模板,只是模板实例化时传递的参数不一样而已。
从代码冗余的角度讲,我们完全没有必要,对用户信息和订单信息索引创建都写一份逻辑相似的代码,即使他们看上去并不是一摸一样。像上面这样,看上去并不是一摸一样的代码,但是存在着一样的处理逻辑,使用着相同形式的代码,我们就叫做模板式的冗余代码。
定义模板
从用户信息与订单信息的索引创建过程中,我们发现模板式的冗余代码主要由两部分构成。
一个是不变的部分,即对任意的数据模型,这些部分的处理都是一样的,主要有以下几点:
对数据中的唯一标识做合法性检查,即通用参数的检查逻辑;
构建 Elasticsearch API 的 IndexRequest,即构建索引创建请求;
获取 Elasticsearch 的集群客户端发送索引创建请求并进行异常处理,即通用的发送请求并进行异常处理的逻辑。
另一个是变化的部分,这些部分都是根据不同的数据模型而变化的,主要有以下几点:
传入参数不同,用户信息传入的是 UserInfo,而订单信息是 OrderInfo;
数据配置不同,用户信息进入的 user_info_index 索引的 user_info_type,而订单信息进入的是 order_info_index 索引的 order_info_type;
集群选择可能不同,这里用户信息和订单信息都采用的默认的集群,但实际项目开发中可能用户信息在集群 1,订单信息在集群 2。
所以,我们想要避免模板式的冗余代码,那么必然要将上述变化的部分和不变的部分定义在一个模板里,这样相似的代码只会存在于模板内。然而,上述不变的部分我们可以直接定义在模板内,而变化的部分我们怎么在模板内抽象表达呢?下面我就基于 Java 语言以 Elasticsearch 索引创建的过程为例具体定义一个包含上述不变和变化部分的模板。
方法定义
首先我们在模板中定义创建索引的方法,在 Java 语言中想要实现上述模板的功能,最好的语言组件自然是 Java 中的抽象类了,同时这里为了在模板中描述方法中变化的参数,即 UserInfo、OrderInfo 等数据模型,我们必然要使用到 Java 中的泛型参数在抽象类对数据模型进行抽象统一。所以我们初步定义的包含创建索引功能的抽象类就是下面这个样子了:
/** * 模板的定义。 * DOC 泛型参数的定义是对模板中变化部分的抽象, * 对接受 Elasticsearch 管理的数据进行统一表示。 */public class AbstractBaseESServiceImpl<DOC> { /** * 在模板中提供创建索引的功能,该功能可对任意数据模型生效。 */ public ServiceResponse<Boolean> create(DOC doc) {}}上述代码基于 Java 中的抽象类和泛型参数对模板做了一个初步的定义,该模板暂时只包含创建索引的功能,但是具体的创建索引的方法并没有实现,为什么呢?因为我们要想实现上述创建索引的参数检查,创建索引请求,发送请求的逻辑,我们必须先知道数据模型中那些通用字段需要做参数检查,该数据要去那个索引和那个类型,该数据要进入那个集群这些信息,显然我们仅仅根据 Doc 类型的 doc 参数是无法获取这些信息的。
元数据初始化
那么如何获取上述所述的信息呢?这时我们就可以利用 Java 语言强大的元语言编程能力,在对象初始化的时候,获取到泛型参数实例化后实际数据模型的元数据。当有了这些准备好的元数据后,就可以在方法运行时,根据实际参数和元数据获取到相关的信息从而完成创建索引的逻辑。所以,接下来我们要做的就是如何准备元数据可以获取到上述那些通用字段需要做参数检查,数据要进入那个索引和那个类型的信息。
在 Java 语言中,元数据信息都是存放在 Class 类型的对象中,所以我们可以在对象初始化的时候先获取到上述 DOC 泛型参数所表示的数据模型的 Class 对象,代码如下:
/** * DOC 数据模型的 Class 对象。 */private Class<DOC> docClass;/** * 初始化元数据。 */public AbstractBaseESServiceImpl() { this.docClass = this.getDocClass();}/** * 获取 DOC 数据模型的元数据。 * 这里主要是获取子类泛型参数实例化后实际数据类型的 Class 对象。 */private Class<DOC> getDocClass() { Type genericSuperclass = this.getClass().getGenericSuperclass(); Type docType = ((ParameterizedType) genericSuperclass).getActualTypeArguments()[0]; if (!(docType instanceof ParameterizedType)) { return (Class<DOC>) docType; } return (Class<DOC>)((ParameterizedType)docType).getRawType();}上述代码都是基于 Java 语言反射机制的实现,具体 API 这里就不细说了。大概思路就是在对象初始化时,使获取到元数据,即在模板中获取到实际数据类型的元数据,为后面获取具体变化的部分信息做准备。变化部分的信息主要包括两方面,一是哪些通用字段需要做参数校验,二是数据进入哪个 Elasticsearch 索引和类型。
通用字段元数据的准备
这里我们先解决获取通用字段元数据信息的问题,从而为通用字段的参数校验做准备。Java 语言中,我们可以通过注解,在各个组件中添加一些标记信息。自然而然地,我们可以自定义注解在实际数据模型定义中标记那些通用字段,根据该标记信息我们可以获取到需要做参数校验地通用字段的元数据信息。
例如上述我们要求任何接受 Elastic 管理的数据都要定义唯一标识,且要求唯一标识是不为空的字符串类型。
如何实现这个需求呢?这时候我们就可发挥 Java 中注解的强大功能了,比如我们自定义一个 DocID 的注解,该注解只能加在 Java 类的字段上,而且必须是不为空的字符串类型。
那么,我们先自定义一个 DocID 的注解,代码如下:
/** * 定义 DOC 数据模型中的唯一标识字段。 * 该注解用于在实际的数据模型中标记 Elasticsearch 文档的唯一标识。 */@Target({ElementType.FIELD})@Retention(RetentionPolicy.RUNTIME)public @interface DocID{}显然,该注解的处理逻辑必然是要在模板对象即上述抽象类对象初始化时存在,也就是说,我们要在上述抽象类初始化时,根据数据模型的元数据获取到标记了该注解的字段的元数据,从而为后面通用参数的校验做准备,这段逻辑具体的代码如下:
/** * 标识字段元数据,用于处理唯一标识相关逻辑,比如参数检查。 */protected final Field idField;/** * 初始化元数据。 */public AbstractBaseESServiceImpl() { this.docClass = this.getDocClass(); this.idField = this.getIDField(); this.idField.setAccessible(true);}/** * 获取文档的 ID 字段元数据。 * 要求用户在使用时,必须通过自定义注解 DocID,告诉我们实际数据模型 * 哪个字段是 ID 字段,从而获取到 ID 字段的具体值,用于通用参数的逻辑检查以及和唯一标识 * 相关的逻辑。 */private Field getIDField() { Field[] declaredFields = this.docClass.getDeclaredFields(); Field idField = null; for (Field declaredField : declaredFields) { DocID docID =declaredField.getAnnotation(DocID.class); if (null == docID) { continue; } idField = declaredField; break; } // 要求数据模型中必须定义 ID 字段。 if (null == idField) { throw new DocIDUndefineException(); } // 要求 ID 字段的类型为字符串。 if (idField.getType() != String.class) { throw new DocIDNotStringException(); } return idField;}上述代码,首先我们通过之前已经准备好的数据模型元数据获取到所有字段的元数据,然后找到标记了 DocID 注解的字段的元数据。这里因为我们要求数据模型必须通过 DocID 定义 ID 字段,所以如果没有定义该字段,那么就抛出 DocIDUndefineException 异常,提示用户通过 DocID 注解在数据模型中定义该字段。
同样的道理,我们要求 ID 字段必须是字符串类型的,如果用户定义的该字段不是字符串类型的,就抛出 DocIDNotStringException 的异常提示用户修正该字段的类型。
最后如果满足 DocID 的语义,我们就正常获取到该字段的元数据信息了。
Elasticsearch 索引和类型信息的准备
接下来,我们解决数据进入哪个 Elasticsearch 索引和类型的数据配置信息获取的问题。仔细思考这个问题,我们会发现,这两个信息的作用和具体的数据模型是有关系的。正如上文所述,用户信息数据要进入的 user_info_index 索引的 user_info_type,而订单信息数据要进入的是 order_info_index 索引的 order_info_type。
所以,很显然,这样的信息,我们只需要提供一种方式可以让用户在模版实例化时将索引和类型的信息与具体的数据模型绑定在一起。顺其自然地,我们在定义模版时,只需要根据绑定信息所采用的方式获取到这些信息的抽象表示,然后实现模版本身该有的逻辑即可。
在 Java 语言中,上述所说的方式,我们依旧可以采用注解的方式来实现。例如,这里我们定义如下的注解,用于在具体的数据模型上标记出该数据模型的具体索引数据在进入 Elasticsearch 中的哪个索引的哪个类型的信息。
/** * 定义实际数据进入 Elasticsearch 中作为文档时的逻辑存储位置。 * 要求,接受 Elasticsearch 管理的实际数据的数据模型必须添加该注解。 */@Target({ElementType.TYPE})@Retention(RetentionPolicy.RUNTIME)public @interface Document { /** * 索引名称,必须值。 * * @return */ String index(); /** * 索引类型名,默认"_doc"。 * ES6 保留了对 type 的支持,兼容了之前版本的多 type,但是 ES6 本身只支持创建一个 * type,默认 type 名称为"_doc"。 * 按照 ES 的发展规划,ES7 会废弃 type,ES8 会删除 type。 * 废除 type 的原因:1. 导致数据稀疏;2. 干扰 lucene 对于文档的压缩编码。 * {@see https://www.elastic.co/guide/en/Elasticsearch/reference/6.6/removal-of-types.html} * * @return */ String type() default "_doc";}对于自定义注解 Document,我们要求用户在定义接受 Elasticsearch 管理的数据模型时,必须在类上添加该注解,通过注解中的 index、type 字段为模版中要使用到的变化的信息,即数据进入哪个 Elasticsearch 索引和类型,进行赋值。那么,我们如何在模版的抽象类中获取到这些信息呢?
同样的道理,在 Java 语言中,我们在类的实例化阶段基于数据模型的反射元数据获取到注解的相关信息,存放在实例域中,在模版方法的实现中使用即可。
/** * 文档注解的 Class 对象。 */protected Class<DOC> documentClass;/** * 指定文档的索引。 */private final String index;/** * 指定文档的类型。 */protected final String type;/** * 初始化元数据。 */public AbstractBaseESServiceImpl() { this.documentClass = this.getDocumentClass(); this.index = this.getDocumentAnnotation().index(); this.type = this.getDocumentAnnotation().type(); this.idField = this.getIDField(); this.idField.setAccessible(true);}/** * 获取文档注解的元数据,即注解的 Class 对象。 * 这里主要是通过获取子类泛型参数实例化后实际数据类型的元数据对象来获取注解的元数据 * 对象。 */private Class<DOC> getDocumentClass() { Type genericSuperclass = this.getClass().getGenericSuperclass(); Type documentType = ((ParameterizedType) genericSuperclass).getActualTypeArguments()[0]; if (!(documentType instanceof ParameterizedType)) { return (Class<DOC>) documentType; } return (Class<DOC>)((ParameterizedType)documentType).getRawType();}/** * 获取有效的的 Document 注解。 * 这里的 Document 注解是我们自己定义的,用于定义不同数据模型的 Elasticsearch 索引和 * 类型。 */private Document getDocumentAnnotation() { Document document = this.documentClass.getAnnotation(Document.class); // 我们要求要使用我们的组件的用户在定义实际数据类型时必须使用我们的注解。 if (null == document) { throw new DocumentAnnotationAbsentException(); } // 注解必须告诉组件该数据模型要进入的索引。 String index = document.index(); if (StringUtils.isBlank(index)) { throw new BlankIndexNameException(); } return document;}getDocumentClass 方法主要通过数据模型的元数据对像获取到 Document 注解的元数据对象。getDocumentAnnotation 方法主要通过注解的元数据获取到具体数据模型上标记的具体的 Document 注解。这里因为我们要求必须添加对 Document 注解的语义定义,且必须指定索引值,所以,当未检测到注解为空时,我们抛出 DocumentAnnotationAbsentException 异常,提醒用户去添加注解。同样的道理,检测到索引 index 字段未定义时,抛出 BlankIndexNameException 异常,提醒用户去定义索引。
同样的道理,我们在抽象类初始化的时候,基于获取到的 Document 注解拿到具体数据模型会进入到哪个索引哪个类型的信息,将该信息放在抽象类的实例域中,为后面模版中具体方法的实现做信息的准备。
有了上述对于数据模型、通用参数、配置信息等元数据的准备,我们在模版定义时具体方法的实现就变得简单多了。
通用参数检查
首先,我们看下抽象类 create 方法中通用参数检查实现,代码如下:
public ServiceResponse<Boolean> create(DOC doc) { // 通用参数检查。 String idValue = this.getIDValue(doc); if (StringUtils.isNonEmpty(idValue)) { return ServiceResponse.createFailResponse(INVALID_DOCUMENT_ID); } }/** * 获取数据模型唯一标识的字段值。 */private String getIDValue(DOC document) { try { return (String) this.idField.get(document); } catch (Exception e) { log.error(GET_DOCUMENT_ID_VALUE_ERROR_MSG, JSON.toJSONString(document), e); } return null;}上述代码,我们只是给出了 create 方法实现中关于通用参数检查的部分,强调一下,这里仅仅以 id 字段为例,一般情况下通用字段根据具体领域模型具体定义,但实现思路上都大同小异。getIdValue 方法的实现中,我们明显可以发现,前期元数据准备的作用在这里体现出来了。通过 id 字段的元数据和具体的数据模型参数的实例引用,我们轻易地拿到了数据模型对象中 id 字段的实际参数值。对于反射的异常处理,我们简单地记录下日志,将异常吸收,同时方法返回 null,具体生产环境的实现大家具体分析,这里不是我们讲解的重点,就不再赘述了。
创建索引请求
我们基于已经准备好的索引和类型信息,在上述模版方法实现的基础上创建索引请求,代码如下:
public ServiceResponse<Boolean> create(DOC doc) { // 通用参数检查。 String idValue = this.getIDValue(doc); if (StringUtils.isNonEmpty(idValue)) { return ServiceResponse.createFailResponse(INVALID_DOCUMENT_ID); } // 创建索引请求。 // 这里数据进入哪个索引, 我们已经在初始化的时候通过注解让用户传进来。 IndexRequest indexRequest = new IndexRequest(this.index, this.type, idValue); String documentData = JSON.toJSONString(doc); indexRequest.source(documentData, XContentType.JSON); indexRequest.opType(DocWriteRequest.OpType.INDEX)}需要强调的一点是,上述创建索引请求时,采用了固定的配置,例如 XContentType.JSON,DocWriteRequest.OpType.INDEX 等,也就是将这些都实现成了不变的部分。其实,这里我们根据 Elasticsearch 客户端 API 的定义可以发现,创建索引请求时还是有很多可以配置的参数,所以具体的实现中,我们依旧可以采用注解的思路将需要指定配置的参数项定义到注解中,提供用户定制请求配置的入口。
发送请求和异常处理
上述通用参数检查、创建索引请求的过程中,相信大家都发现了一点,我们在模版定义的方法实现中使用到了模版的抽象类在初始化时准备好的元数据。这里准备的元数据解决了我们前面提到的变化部分前两个逻辑的抽象定义,但是并没有解决最后一个逻辑的抽象定义,也就是并没有为发送请求和异常处理时获取 Elasticsearch 集群客户端的逻辑准备相关的元数据,为什么呢?
我们看一下获取 Elasticsearch 集群客户端的逻辑是什么样的。
首先,Elasticsearch 集群客户端是一个 Java 实例对象,该对象管理着和一个指定 Elastcisearch 集群交互的相关信息,例如集群节点的 IP 地址、端口号、连接池大小以及各种超时时间等。考虑到对象配置的复杂和足够的灵活性以及不是每个数据模型都会对应着一个不同的集群的原因,我们再次采用上述数据模型中定义注解和抽象类实例化时准备元数据的方法实现获取客户端集群的逻辑,就显得不够用了。
那么,我们怎么在模版定义的抽象类中留出用户定制集群客户端的入口呢?
相信大家应该了解设计模式中的模版方法模式,这里我们就采用模版方法的模式实现上述创建索引方法的发送请求和异常处理逻辑。
public ServiceResponse<Boolean> save(DOC doc) { // 通用参数检查。 String idValue = this.getIDValue(doc); if (StringUtils.isNonEmpty(idValue)) { return ServiceResponse.createFailResponse(INVALID_DOCUMENT_ID); } // 创建索引请求。 // 这里数据进入哪个索引, 我们已经在初始化的时候通过注解让用户传进来。 IndexRequest indexRequest = new IndexRequest(this.index, this.type, idValue); String documentData = JSON.toJSONString(doc); indexRequest.source(documentData, XContentType.JSON); indexRequest.opType(DocWriteRequest.OpType.INDEX) try { // 这里我们在真正调用 Elasticsearch 客户端的 API 时,通过模板模式定义客户端 // 的获取方法。这样,用户可以在子类中定制自己的实现。 this.getClient().index(indexRequest, RequestOptions.DEFAULT); } catch (Exception e) { log.error(SAVE_DOCUMENT_ERROR_MSG, JSON.toJSONString(doc), e); return ServiceResponse.FAIL_RESPONSE; } return ServiceResponse.SUCCESS_RESPONSE;}到这里,我们终于完成了模版定义中创建索引方法的实现。代码中的 getClient 方法的实现最终会返回一个 Elasticsearch 集群客户端的实例,由该客户端实例真正执行索引请求的发送,同时做了一个通用的异常处理。具体返回一个怎么样的集群客户端呢?我们来看下面的代码:
/** * 获取 ES 客户端。 * 这里我们提供了一个默认的客户端实现。 */RestHighLevelClient getClient() { if (null != this.client) { return this.client; } // 优先子类实现自己的客户端。 // 模板模式中定义的客户端获取方法。 RestHighLevelClient client = this.doGetClient(); do { if (null == client) { break; } synchronized (this.clientLock) { if (null == this.client) { this.client = client; } } return this.client; } while (false); // 系统默认配置的客户端。 client = InitESRestClient.getClient(); if (null == client) { throw new RestClientNotFoundException(); } synchronized (this.clientLock) { if (null == this.client) { this.client = client; } } return this.client;}/** * 执行获取 ES 客户端,子类可定制实现。 */protected RestHighLevelClient doGetClient() { return null;}代码中包括两个方法,我们先看下 getClient 方法的实现逻辑。因为这里我们需要一个数据模型只会与一个集群绑定,所以我们对 Elasticsearch 集群客户端的获取做了一个单例的处理,当然这不是我们的重点。我们看到方法在获取客户端时会先调用一下 doGetClient 方法获取一个集群客户端,当该方法返回的客户端不为空时,我们按照单例的处理逻辑将当前数据模型的集群客户端保存下来;当该方法返回的客户为空时,我们依旧按照单例的处理逻辑获取到一个默认的集群客户端并保存下来;如果默认客户端也没有获取到,我们就抛出 RestClientNotFoundException 异常要求用户去定义客户端。从 getClient 方法的分析中,我们很轻松地便会发现 doGetClient 方法的巧妙之处,所以接下来我们看下 doGetClient 方法的实现。相信大家立刻会发现 doGetClient 方法实现的怪异之处,首先这是一个定义为 protected 的方法,意味着任何子类都可以覆盖它,同时该方法直接返回了 null,意味着如果子类没有覆盖该方法,或者覆盖了该方法但依旧返回了 null,那么上述的 getClient 方法就会返回一个默认的集群客户端。
这就是模版方法模式的巧妙之处,我们把逻辑比较复杂,可能需要用户定制的逻辑通过模版方法的入口留给用户自己去定制,从而完成模版定义中变化部分信息的抽象定义。
到此为止,我们就完成了模版式冗余代码的抽取过程,最终我们定义了一个只存有一份冗余代码中逻辑的模版。只不过我们的模版目前只是一个简单的模版,仅仅实现了创建索引的方法逻辑。但是从中我们可以发现,要想将模版冗余代码抽取到模版中,我们必须解决冗余代码中变化部分信息的抽象表达问题,在不同的语言中,这种抽象表达的方式会不同。
在 Java 语言中,我们主要通过两种方式来解决上述抽象表达的问题。一个是基于泛型参数,自定义注解以及反射机制来准备元数据的方式,二是通过模版方法模式将变化部分的逻辑留给用户自己去定制。
模板实例化
定义完了模版,我们就完成了模版式冗余代码中通用代码逻辑抽象封装,那么我们在实际应用时如何将具体的业务模型嵌入到模版中呢?也就是说我们如何完成上述模版的实例化呢?
我们还是用前面提到的简单用户信息和订单信息的数据模型来说明。请注意这里说的不是 Java 对象的实例化,而是我们通用概念下的模版实例化。
用户信息的模板实例化
当我们定义了用户信息的数据模型时,按照以上定义模版的实现,我们需要在数据模型的唯一标识字段中添加 DocID 注解来标记该字段是唯一标识,要求该字段的值是非空字符串类型。同时我们需要在数据模型类上添加 Document 注解来表示该数据模型要接受 Elasticsearch 的管理,其数据要进入"user_info_index"索引的"user_info_type"类型。代码如下:
/** * Elasticsearch 用户信息数据模型。 */@Document(index = "user_info_index", type = "user_info_type")public class UserInfo { @DocumentID private String id; // ID private String nickName; // 昵称 private Integer age; // 年龄 private String introduction; // 简介 private String signature; // 签名}有了用户信息数据模型的定义,我们如何享受到上述模版定义中创建索引的方法呢?而不用自己手动再实现一遍用户信息创建索引的方法逻辑。显而易见,我们定义一个用户信息的 Elasticsearch 服务,集成上述模版定义的抽象类,同时完成泛型参数的实例化即可,具体的代码如下:
public class UserInfoESService extends AbstractBaseESServiceImpl<UserInfo> {}显然这里用户信息在接受 Elasticsearch 管理时,数据是进入到项目中默认的 Elasticsearch 集群的,因为我们并没有覆盖模版类中的 doGetClient 方法的实现。
订单信息的模板实例化
同理,订单信息数据模型的定义如下:
/** * Elasticsearch 订单信息数据模型。 */@Document(index = "order_info_index", type = "order_info_type")public class OrderInfo { private String id; private String productId; // 产品 ID private Integer productNum; // 产品数据量 private Integer status; // 订单状态 private String remark; // 备注}订单信息 Elasticsearch 相关服务的实现我们依旧可以继承上述模版定义的抽象类。
但是这里我们假设订单信息的数据会进入项目中的另一集群,那么自然而然地,对于订单信息 Elasticsearch 相关服务的实现就需要我们自己去定制集群访问的客户端了,代码如下:
public class OrderInfoESService extends AbstractBaseESServiceImpl<OrderInfo> { @Override protected RestHighLevelClient doGetClient() { return InitESRestClientAnother.getClient(); }}代码中 InitESRestClientAnother 即完成了另一个客户端获取的逻辑,大家只需要明白这里是另一个集群客户端即可。我们关注的重点是有了入口可以定制我们的业务数据要进入哪个集群,而不用写过多的冗余代码。
扩展模版
在定义模版和模版实例化的过程中,我们始终围绕着创建索引的方法来说明如何解决模版式的冗余代码。但其实在真实的项目中,还存在着增删改查等其他的通用功能,这些通用的功能我们都可以在定义模版的时候实现它们。
而要实现上述更多的通用功能所采用的思路无非和我们讲述创建索引的方法大同小异,都是抽取出通用功能不变的部分和变化的部分。对于不变的部分我们直接使用,对于变化的部分我们采用语言提供的相关元数据机制或良好的设计模式进行抽象表达,然后在实现具体的业务逻辑时进行模版实例化即可。
这里,为了让大家更深刻地体会上述解决模版式冗余代码的思路,我们用 Java 语言中的接口来定义一下模版中通用的增删改查的功能,然后提供一个相对完整的抽象类进行模版功能的实现。
考虑到文章内容长度有限,我这里暂且先给出模版功能的接口定义,如果大家感兴趣的话,也可以采用上述的思路自己动手实现一下下面模版功能的接口:
/** * Elasticsearch 的基础服务接口定义。 */public interface IBaseESService<DOC> { /** * 保存文档,文档基于 ID 不存在,则创建,已存在,则覆盖。 */ ServiceResponse<Boolean> create(DOC doc); /** * 获取指定 ID 的文档。 */ ServiceResponse<DOC> get(String id); /** * 分页查询 ID 列表。 */ ServiceResponse<Page<String>> queryIDs(PageRequest pageRequest, BoolQueryBuilder queryBuilder, List<SortBuilder> sorts); /** * 删除指定 ID 的文档。 */ ServiceResponse<Boolean> delete(String id); /** * 更新文档,仅更新文档中存在的字段,文档的 ID 字段必须存在。 */ ServiceResponse<Boolean> update(DOC doc);}总结
到此为止,我们采用 Java 语言,借助 Elasticsearch 在项目使用中的创建索引场景,完整讲述了如何快速解决模版式的冗余代码问题。下面我做一下简单的总结:
在解决模版式的冗余代码问题时,我的思路是抽取出冗余代码中不变的部分和变化的部分定义一个模版。对于不变的部分,直接在模版中使用,对于变化的部分,一般都会用到语言的元编程功能以及一些良好的设计模式,提供对数据和操作的统一抽象和扩展。
在 Java 中提供的元编程功能主要是围绕着以反射为核心,注解,泛型,字节码注入等技术而提供的。
采用模版方法模式为定义模版中变化的集群客户端留出了定制的扩展点。
另外,我简单画一下解决问题前后代码结构的对比图,方便大家清晰地理解文章中的思路。
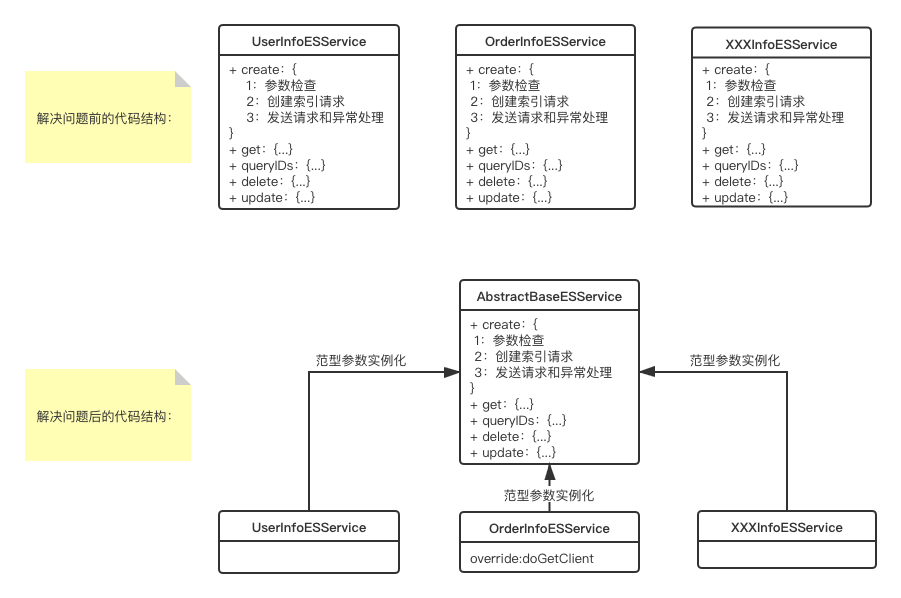
作者介绍:
李立坤,搜狐高级研发工程师,从 0 到 1 参与了搜狐内部玄武内容监控平台的架构设计与研发工作。参与过教育产品、电商系统、分销系统、团购系统、分布式任务调度系统的架构与研发。




