
Kubernetes 是一款开源的项目,管理 Linux 容器集群,并可将集群作为一个单一的系统来对待。其可跨多主机来管理和运行 Docker 容器、提供容器的定位、服务发现以及复制控制。它由 Google 发起,现在则得到如微软、红帽、IBM 和Docker 等众多厂商的支持。
Google 使用容器技术有着超过十年的历史,每周要启动超过2 亿台容器。通过Kubernetes,Google 分享了他们关于容器的专业经验,即创建大规模运行容器的开放平台。
一旦用户开始使用Docker 容器,那么问题就来了,一、如何大规模并在多个容器主机上启动它们,且能够在主机间取得平衡。二、还需要高度抽象出API 来定义如何逻辑上组织容器、定义容器池、负载均衡以及相似性。该项目就是为了解决这两个问题而生的。
Kubernetes 概念
Kubernetes 的架构被定义为由一个 master 服务器和多个 minons 服务器组成。命令行工具连接到 master 服务器的 API 端点,其可以管理和编排所有的 minons 服务器,Docker 容器接收来自 master 服务器的指令并运行容器。
- 命名空间:基于它们自身的配额和网络的集群分区。
- 节点:每个安装由 Kubelet 服务的 Docker 主机,Kubelet 服务用于接收来自 Master 的指令,且管理运行容器的主机(原来叫做 minions)。
- Pod :定义了一组绑在一起的容器,可以部署在同一节点,例如一个数据库或者是 web 服务器。
- Replication controller :定义了需要运行多少个 Pod 或者容器。跨多个 minons 来调度容器。
- Service :定义了由容器所发布的可被发现的服务/端口,以及外部代理通信。服务会映射端口到外部可访问的端口,而所映射的端口是跨多个节点的 Pod 内运行的容器的端口。
- kubectl:命令行客户端,连接到 master 来管理 Kubernetes。
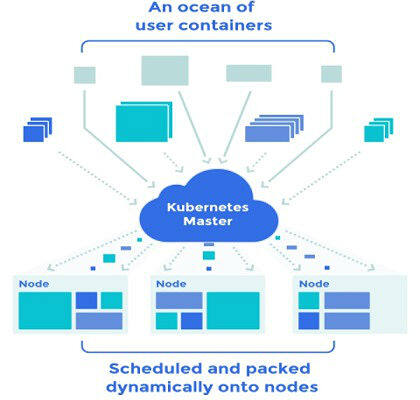
Kubernetes 由状态所定义,而不是进程。当你定义了一个 pod 时,Kubernetes 会尝试确保它会一直运行。如果其中的某个容器挂掉了,Kubernetes 会尝试再启动一个新的容器。如果一个复制控制器定义了 3 份复制,Kubernetes 会尝试一直运行这 3 份,根据需要来启动和停止容器。
本文中所用的例子应用是 Jenkins 持续集成服务,Jenkins 是典型的通过主从服务来建立分布式的工作任务的例子。Jenkins 由 jenkins swarm 插件来配置,运行一个 jenkins 主服务和多个 jenkins 从服务,所有的 Jenkins 服务都以 Docker 容器的方式跨多个主机运行。swarm 从服务在启动时连接到 Jenkins 主服务,然后就可以运行 Jenkins 任务了。例子中使用的配置文件在从Github 上下载到,至于Docker 的镜像,对于Jenkins 主服务来说,从 casnchez/jenkins-swarm 获取,即加入了 swarm 插件的官方 Jenkins 镜像。对于 jenkins 从服务来说,从 csanchez/jenkins-swarm-slave 获取,此仅是在 JVM 容器中运行了 jenkins 从服务而已。
新特性
版本 1.0 的发布带来稳定的 API,以及管理大型集群的功能,包括 DNS、负载均衡、扩展、应用程序级别的健康检测、服务账户、以及使用命名空间来隔离应用。API 和命令行现在可以支持远程执行、跨多个主机的日志收集、以及资源监控。支持了更多的基于网络的卷,它们有 Google 计算引擎的持久磁盘、AWS 伸缩块存储、NFS、 Flocker 、 GlusterFS 。
版本 1.1 在 1.0 的基础上有增加了一些新的特性,包括正常终止 pod、支持 Docker1.8、自动横向扩展、以及在 Kubernetes 集群中使用 Pod 来调度短时间运行的任务(相对长时间运行的任务)的新的任务对象。
创建Kubernetes 集群
Kubernetes 提供了多个操作系统和云/虚拟化提供商下创建集群的脚本,有 Vagrant(用于本地测试)、Google Compute Engine、Azure、Rackspace 等。 Google 容器引擎 (GKE) 提供了 Kubernetes 集群即服务的支持。接下来我们会以本地的 Vagrant 虚拟机和 Google 容器引擎下来创建一个集群,至于选择哪个就看读者本身的喜好了,尽管 GKE 提供了更多的关于网络和持久存储方面的特性。这些例子也同样可以运行在任何其它的供应商平台下,当然需要少许的改动,我们也会在相应的章节有所描述。
Vagrant
本文所实践的例子就是运行在 Vagrant 之上的本地集群,使用 Fedora 作为操作系统,遵照的是官方入门指南,测试的Kubernetes 版本是1.0.6。取代了默认的3 台节点(Docker 主机),而是使用了2 个minion,两台主机就足够可以展示Kubernetes 的能力了,三台就有点浪费。
当你下载了Kubernetes ,然后将至解压后,示例即可在本地的目录下运行。初学者创建集群仅需要一个命令,即./cluster/kube-up.sh。
<span>$ </span>export <span>KUBERNETES_PROVIDER</span>=vagrant <span>$ </span>export <span>KUBERNETES_NUM_MINIONS</span>=<span>2</span> <span>$ </span>./cluster/kube-up.sh
集群创建的快慢取决于机器的性能和内部的带宽。但是其最终完成不能有任何的错误,而且它仅需要运行一次。
和 Kubernetes 交互的命令行工具叫做 kubectl。Kubernetes 的发布软件包中包含了一个便利的工具-cluster/kubectl.sh,但是命令行可以独立安装,而且也可以使用由kubeup.sh 所创建的配置文件~/.kube/config。
确保kubectl 在环境变量PATH 中,因为在接下来的章节中将用到。要检查集群是启动并运行的,使用 kubectl get nodes。
$ kubectl get nodes NAME LABELS STATUS <span>10.245</span><span>.1</span><span>.3</span> kubernetes.<span>io</span>/hostname=<span>10.245</span><span>.1</span><span>.3</span> Ready <span>10.245</span><span>.1</span><span>.4</span> kubernetes.<span>io</span>/hostname=<span>10.245</span><span>.1</span><span>.4</span> Ready
google 容器引擎
按照 Google 云平台站点上的步骤注册 Google 容器引擎,启用容器引擎 API,安装gcloud 工具,然后使用 gcloud init配置 Google 云平台。
一旦你成功登陆后,首先要更新 kubectl 工具,设置一些默认值,然后创建Kubernetes 集群。确保使用你的正确的Google 云项目ID。
$ gcloud components update kubectl $ gcloud config <span>set</span> project prefab<span>-backbone</span><span>-</span><span>109611</span> $ gcloud config <span>set</span> compute/zone us<span>-central1</span><span>-f</span> $ gcloud container clusters create kubernetes<span>-jenkins</span> Creating cluster kubernetes<span>-jenkins</span><span>...</span>done<span>.</span> Created <span>[</span>https: kubeconfig entry generated for kubernetes<span>-jenkins</span><span>.</span> NAME ZONE MASTER_VERSION MASTER_IP MACHINE_TYPE STATUS kubernetes<span>-jenkins</span> us<span>-central1</span><span>-f</span> <span>1.0</span><span>.6</span> <span>107.178</span><span>.220</span><span>.228</span> n1<span>-standard</span><span>-</span><span>1</span> RUNNING
设置刚刚创建的集群的默认值,并为kubectl获取证书。
$ gcloud config <span>set</span> container/cluster kubernetes<span>-jenkins</span> $ gcloud container clusters get<span>-credentials</span> kubernetes<span>-jenkins</span>
运行kubectl获取节点信息,正确的输出应是集群中有三台节点。
$ kubectl get nodes NAME LABELS STATUS gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-</span><span>5</span>gvr kubernetes<span>.</span>io/hostname<span>=</span>gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-</span><span>5</span>gvr Ready gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-chiv</span> kubernetes<span>.</span>io/hostname<span>=</span>gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-chiv</span> Ready gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-mb7s</span> kubernetes<span>.</span>io/hostname<span>=</span>gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-mb7s</span> Ready
集群信息
在集群启动后,我们就可以访问 API 端点或者是kube-ui的界面。
$ kubectl cluster-info Kubernetes master is running <span>at</span> <span>https</span>://<span>107.178</span><span>.220</span><span>.228</span> KubeDNS is running <span>at</span> <span>https</span>://<span>107.178</span><span>.220</span><span>.228</span>/api/v1/proxy/namespaces/kube-<span>system</span>/services/kube-dns KubeUI is running <span>at</span> <span>https</span>://<span>107.178</span><span>.220</span><span>.228</span>/api/v1/proxy/namespaces/kube-<span>system</span>/services/kube-ui Heapster is running <span>at</span> <span>https</span>://<span>107.178</span><span>.220</span><span>.228</span>/api/v1/proxy/namespaces/kube-<span>system</span>/services/monitoring-heapster
代码实例
从 Github 获取示例配置文件:
$ git <span>clone</span> --branch infoq-kubernetes-<span>1.0</span> https:
命名空间
命名空间可以跨多个用户和应用来隔离资源。
$ kubectl <span>get</span> namespaces NAME LABELS STATUS default <<span>none</span>> Active kube-<span>system</span> <<span>none</span>> Active
命名空间可以关联到资源配额,用来限制所使用的cpu、内存、以及一些各种类型(Pod、服务、复制控制器等)的资源。在下面的例子中,使用了默认的命名空间,但是可以自行创建命名空间来隔离资源,也有一些运行的服务通过 kube-system命名空间提供端点给 Kubernetes 系统资源。
$ kubectl get endpoints <span>--</span><span>all</span><span>-namespaces</span> NAMESPACE NAME ENDPOINTS default jenkins <span><</span><span>none</span><span>></span> default kubernetes <span>107.178</span><span>.220</span><span>.228</span>:<span>443</span> kube<span>-system</span> kube<span>-dns</span> <span>10.172</span><span>.2</span><span>.3</span>:<span>53</span>,<span>10.172</span><span>.2</span><span>.3</span>:<span>53</span> kube<span>-system</span> kube<span>-ui</span> <span>10.172</span><span>.0</span><span>.5</span>:<span>8080</span> kube<span>-system</span> monitoring<span>-heapster</span> <span>10.172</span><span>.0</span><span>.6</span>:<span>8082</span>
Pod
在一个 pod 中可以指定多个容器,这些容器均部署在同一 Docker 主机中,在一个 pod 中的容器的优势在于可以共享资源,例如存储卷,而且使用相同的网络命名空间和IP 地址。
在此Jenkins 的实例中,我们有一个pod 来运行Jenkins 主服务,但是这是一个试验性质的, pod 在调度失效、节点失效、缺少资源、或者是节点维护无法存活。假如发生了作为 pod 运行 Jenkins 主服务的节点宕掉了,容器永远不会去重新启动它。基于此原因,我们将会在下面的例子中将 Jenkins 主服务以复制控制器的方式运行,基于一个实例。
复制控制器
复制控制器允许跨多个节点运行多个 pod,正如上面所提到的,Jenkins 主服务会以一个复制控制器来运行到一个存活的节点上。当 Jenkins Slaves 使用复制控制器来确保一直会有 slave 的池来运行 Jenkins 任务。
持久卷
Kubernetes 支持多种后端的存储卷
- emptyDir
- hostPath
- gcePersistentDisk
- awsElasticBlockStore
- nfs
- iscsi
- glusterfs
- rbd
- gitRepo
- secret
- persistentVolumeClaim
卷在默认情况下均是空的目录,类型为emptydir,其生命周期是以 pod 的生命周期为准的,所以即使是容器宕掉了,持久存储仍在。其它的卷类型是hostpath,此是一种在容器内部直接挂在其所在主机服务器上的存储的一种方式。
secret的卷是用于哪些较敏感的信息,诸如用于 pod 的密码。密文可以保存在 Kubernetes API 中,pod 使用的时候将其挂载为文件,而且会在内存中以 tmpfs 的形式作备份。
持久卷是实现了用户所“要求”的持久化的存储(诸如 gcePersistent或iscsi卷)而且还无须知道特定云环境的细节,在 pod 中使用persistentVolumeClaim就可以挂载。
在一个典型的 Kubernetes 安装中,后端的卷是可用于网络的,所以数据是可以挂载到任何的节点上的,从而 pod 可以调度它们。
在 Vagrant 的试验环境中,我们使用了一个简单的hostDir,这样做的弊端就是 pod 从一个节点移到另外一个节点时,数据不会跟着做迁移。
当使用 Google 容器引擎时,我们需要创建一个 GCE 的磁盘,这会用于主的 Jenkins pod,存放 Jenkins 的数据。
gcloud compute disks <span><span>create</span> --<span>size</span> <span>20</span>GB jenkins-data-disk</span>## Jenkins 主复制控制器
为了创建一个 Jenkins 主 pod,我们运行 kubectl 及其 Jenkins 容器复制控制器的定义,使用的 Docker 镜像是csanchez/jenkins-swarm,端口是 8080 和 50000,映射到容器,这样就可以访问 Jenkins 的 Web 用户界面和从服务的 API 了,以及挂载卷到路径/var/jenkins_home。
livenessProbe的配置属性在自我修复一节有所涉及,当然你也可以在 GitHub 上的例子中找到。
Vagrant 环境的定义(jenkins-master-vagrant.yml)如下所示:
apiVersion: <span>"v1"</span> kind: <span>"ReplicationController"</span> metadata: <span>name</span>: <span>"jenkins"</span> labels: <span>name</span>: <span>"jenkins"</span> spec: replicas: <span>1</span> template: metadata: <span>name</span>: <span>"jenkins"</span> labels: <span>name</span>: <span>"jenkins"</span> spec: containers: - <span>name</span>: <span>"jenkins"</span> image: <span>"csanchez/jenkins-swarm:1.625.1-for-volumes"</span> ports: - containerPort: <span>8080</span> - containerPort: <span>50000</span> volumeMounts: - <span>name</span>: <span>"jenkins-data"</span> mountPath: <span>"/var/jenkins_home"</span> livenessProbe: httpGet: path: / port: <span>8080</span> initialDelaySeconds: <span>60</span> timeoutSeconds: <span>5</span> volumes: - <span>name</span>: <span>"jenkins-data"</span> hostPath: path: <span>"/home/docker/jenkins"</span>
对于 Google 容器引擎中的定义,只需将上述中关于卷的定义jenkins-data替换我我们刚才所创建的 GCE 磁盘即可:
<span>volumes</span>: - name: <span>"jenkins-data"</span> gcePersistentDisk: pdName: jenkins-<span><span>data</span>-disk</span> fsType: ext4
创建复制控制器是使用一样的命令:
$ kubectl create <span>-f</span> jenkins<span>-master</span><span>-gke</span><span>.</span>yml
创建完成后,Jenkins 复制控制器和 Pod 会显示在相应的列表中:
$ kubectl <span>get</span> replicationcontrollers CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS jenkins jenkins csanchez/jenkins-swarm:<span>1.625</span><span>.1</span>-<span>for</span>-volumes <span>name</span>=jenkins <span>1</span> $ kubectl <span>get</span> pods NAME READY STATUS RESTARTS AGE jenkins-gs7h9 <span>0</span>/<span>1</span> Pending <span>0</span> <span>5</span>s
可使用kubectl describe来获得更多的细节,诸如查看调度到了哪个节点,或者是部署期间出现的错误:
$ kubectl describe pods/jenkins<span>-gs7h9</span> Name: jenkins<span>-gs7h9</span> Namespace: default Image(s): csanchez/jenkins<span>-swarm</span>:<span>1.625</span><span>.1</span><span>-for</span><span>-volumes</span> Node: gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-chiv</span>/<span>10.240</span><span>.0</span><span>.3</span> Labels: name<span>=</span>jenkins Status: Running Reason: Message: IP: <span>10.172</span><span>.1</span><span>.32</span> Replication Controllers: jenkins (<span>1</span>/<span>1</span> replicas created) Containers: jenkins: Image: csanchez/jenkins<span>-swarm</span>:<span>1.625</span><span>.1</span><span>-for</span><span>-volumes</span> Limits: cpu: <span>100</span>m State: Running Started: Sun, <span>18</span> Oct <span>2015</span> <span>18</span>:<span>41</span>:<span>52</span> <span>+</span><span>0200</span> Ready: <span>True</span> Restart Count: <span>0</span> Conditions: <span>Type</span> Status Ready <span>True</span> Events: FirstSeen LastSeen Count From SubobjectPath Reason Message Tue, <span>13</span> Oct <span>2015</span> <span>20</span>:<span>36</span>:<span>50</span> <span>+</span><span>0200</span> Tue, <span>13</span> Oct <span>2015</span> <span>20</span>:<span>36</span>:<span>50</span> <span>+</span><span>0200</span> <span>1</span> {scheduler } scheduled Successfully assigned jenkins <span>to</span> gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-</span><span>5</span>gvr Tue, <span>13</span> Oct <span>2015</span> <span>20</span>:<span>36</span>:<span>59</span> <span>+</span><span>0200</span> Tue, <span>13</span> Oct <span>2015</span> <span>20</span>:<span>36</span>:<span>59</span> <span>+</span><span>0200</span> <span>1</span> {kubelet gke<span>-kubernetes</span><span>-jenkins</span><span>-e46fdaa5</span><span>-node</span><span>-</span><span>5</span>gvr} implicitly required container POD pulled Pod container image <span>"gcr.io/google_containers/pause:0.8.0"</span> already present <span>on</span> machine <span>[</span><span>...</span><span>]</span><span> </span>
一段时间后,它会下载 Docker 镜像到节点,我们可以查看它的状态为Running:
$ kubectl <span>get</span> pods NAME READY STATUS RESTARTS AGE jenkins-gs7h9 <span>1</span>/<span>1</span> Running <span>0</span> <span>15</span>s
Jenkins 容器日志可从 Kubernetes API 来访问:
$ kubectl logs jenkins-gs7h9 Running from: /usr/share/jenkins/jenkins.war webroot: EnvVars.masterEnvVars.get(<span>"JENKINS_HOME"</span>) <span>...</span> INFO: Jenkins is fully up and running
服务
Kubernetes 可以定义服务,一种让容器可以彼此发现的方法,代理请求到相应的节点以及做到负载均衡。
每个服务都定义了一些类型字段,这些字段是告诉如何来访问这些服务的。
- ClusterIP: 仅用于集群内部的 IP,默认;
- NodePort:用于集群 IP,但是也会抛出集群中每个节点的服务端口(每个节点的端口都一样);
- LoadBlancer: 一些云服务提供商会提供对外部负载均衡起的支持(目前有 GKE 和 AWS),使用 ClusterIP 和 NodePort,但是可以要求云服务提供商使用何种负载均衡器来转发服务。
默认情况下,服务只有ClusterIP类型,这就意味着只能从集群内部访问到服务。为了能够让外部也可以访问到服务,或是NodePort,或是LodaBlancer,需要打开其中一个。
每个服务都会被分配一个唯一的 IP 地址,且此 IP 的生命周期伴随着服务。如果我们有多个 Pod 匹配到服务的话,则定义服务的负载均衡到流量到这些 Pod。
接下来,我们会创建一个 id 为 jenkins 的服务,指配的 Pod 为标签是name=jenkins,正如在 jenkins-master 复制控制器定义中声明的,以及转发链接到端口 8080、Jenkins Web UI、端口 50000,均是 Jenkins Swarm 插件所需要的。
Vagrant
在 Vagrant 中运行,我们可以使用kubectl来创建一个NodePort类型的服务。
apiVersion: <span>"v1"</span> kind: <span>"Service"</span> metadata: <span>name</span>: <span>"jenkins"</span> spec: type: <span>"NodePort"</span> selector: <span>name</span>: <span>"jenkins"</span> ports: - <span>name</span>: <span>"http"</span> port: <span>8080</span> protocol: <span>"TCP"</span> - <span>name</span>: <span>"slave"</span> port: <span>50000</span> protocol: <span>"TCP"</span> $ kubectl create -f service-vagrant.yml $ kubectl <span>get</span> services/jenkins NAME LABELS SELECTOR IP(S) PORT(S) jenkins <none> <span>name</span>=jenkins <span>10.247</span><span>.0</span><span>.117</span> <span>8080</span>/TCP <span>50000</span>/TCP
服务的描述信息会展示节点的那个端口映射到了容器内的 8080。
$ kubectl describe services/jenkins <span>Name:</span> jenkins <span>Namespace:</span> default <span>Labels:</span> <none> <span>Selector:</span> name=jenkins <span>Type:</span> NodePort <span>IP:</span> <span>10.247</span><span>.0</span><span>.117</span> <span>Port:</span> http <span>8080</span>/TCP <span>NodePort:</span> http <span>32440</span>/TCP <span>Endpoints:</span> <span>10.246</span><span>.2</span><span>.2</span>:<span>8080</span> <span>Port:</span> slave <span>50000</span>/TCP <span>NodePort:</span> slave <span>31241</span>/TCP <span>Endpoints:</span> <span>10.246</span><span>.2</span><span>.2</span>:<span>50000</span> Session Affinity: None No events.
我们可以使用我们的 Vagrant 的任何节点来访问 Jenkins 的 Web UI,在此例中服务的定义NodePort为端口 32440,所以 10.245.1.3:32440 或 10.245.1.4:32440 会转发以连接到正确的容器。
Goodle 容器引擎
在 GKE 中运行的话,我们可以使用公网 IP 来创建类生产环境的负载均衡器。
apiVersion: <span>"v1"</span> kind: <span>"Service"</span> metadata: <span>name</span>: <span>"jenkins"</span> spec: type: <span>"LoadBalancer"</span> selector: <span>name</span>: <span>"jenkins"</span> ports: - <span>name</span>: <span>"http"</span> port: <span>80</span> targetPort: <span>8080</span> protocol: <span>"TCP"</span> - <span>name</span>: <span>"slave"</span> port: <span>50000</span> protocol: <span>"TCP"</span> $ kubectl create -f service-gke.yml $ kubectl <span>get</span> services/jenkins NAME LABELS SELECTOR IP(S) PORT(S) jenkins <none> <span>name</span>=jenkins <span>10.175</span><span>.245</span><span>.100</span> <span>80</span>/TCP <span>50000</span>/TCP
服务的描述信息会展示给我们负载均衡器的 IP(在创建的时候可能会稍花费一点时间),此例中的 IP 是:104.197.19.100
$ kubectl describe services/jenkins <span>Name:</span> jenkins <span>Namespace:</span> default <span>Labels:</span> <none> <span>Selector:</span> name=jenkins <span>Type:</span> LoadBalancer <span>IP:</span> <span>10.175</span><span>.245</span><span>.100</span> LoadBalancer Ingress: <span>104.197</span><span>.19</span><span>.100</span> <span>Port:</span> http <span>80</span>/TCP <span>NodePort:</span> http <span>30080</span>/TCP <span>Endpoints:</span> <span>10.172</span><span>.1</span><span>.5</span>:<span>8080</span> <span>Port:</span> slave <span>50000</span>/TCP <span>NodePort:</span> slave <span>32081</span>/TCP <span>Endpoints:</span> <span>10.172</span><span>.1</span><span>.5</span>:<span>50000</span> Session Affinity: None No events.
我们也可以使用 Google 云 API 来获得关于负载均衡的信息。(在 GCE 的术语中叫做forwarding-rule)
$ gcloud compute forwarding<span>-rules</span> <span>list</span> NAME REGION IP_ADDRESS IP_PROTOCOL TARGET afe40deb373e111e5a00442010af0013 us<span>-central1</span> <span>104.197</span><span>.19</span><span>.100</span> TCP us<span>-central1</span>/targetPools/afe40deb373e111e5a00442010af0013
这是如果我们在浏览器中键入 IP 和端口的话,就可以看到 Jenkins web 界面在运行了。
DNS 和服务发现
服务的另外一个特性就是可为通过 kubernetes 运行的一连串容器设置很多环境变量,从而提供连接到服务容器的能力,类似于 Docker 容器 linked 的做法。这样可以用于从任何的 Jenkins 从服务发现主的 Jenkins 服务。
<span>JENKINS_SERVICE_HOST=<span><span>10.175</span>.<span>245.100</span></span></span> <span>JENKINS_PORT=<span>tcp://<span>10.175</span>.<span>245.100</span>:<span>80</span></span></span> <span>JENKINS_PORT_80_TCP_ADDR=<span><span>10.175</span>.<span>245.100</span></span></span> <span>JENKINS_SERVICE_PORT=<span><span>80</span></span></span> <span>JENKINS_SERVICE_PORT_SLAVE=<span><span>50000</span></span></span> <span>JENKINS_PORT_50000_TCP_PORT=<span><span>50000</span></span></span> <span>JENKINS_PORT_50000_TCP_ADDR=<span><span>10.175</span>.<span>245.100</span></span></span> <span>JENKINS_SERVICE_PORT_HTTP=<span><span>80</span></span></span>
Kubernetes 还支持可选的额外组件 SkyDNS ,SkyDNS 是构建在 etcd 之上的公告和服务发现的一个分布式服务,可以为服务创建A 记录和SRV 纪录。A 记录的形式是 my-svc.my-namespace.svc.cluster.local,SRV 是records _my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster.local。容器均被配置为使用 SkyDNS 来解析服务名称为服务的 IP,/etc/resolv/conf被配置为搜索多个后缀,从而让名称解析更加的容易:
nameserver <span>10.175</span><span>.240</span><span>.10</span> nameserver <span>169.254</span><span>.169</span><span>.254</span> nameserver <span>10.240</span><span>.0</span><span>.1</span> search default<span>.svc</span><span>.cluster</span><span>.local</span> svc<span>.cluster</span><span>.local</span> cluster<span>.local</span> c<span>.prefab</span>-backbone-<span>109611.</span>internal. <span>771200841705.</span>google<span>.internal</span>. google<span>.internal</span>. options ndots:<span>5</span>
举个例子,对于我们刚刚创建的 jenkins 服务来说,下面的名称会被解析:
- ``jenkins, jenkins.default.svc.cluster.local, A record pointing to 10.175.245.100`
_http._tcp.jenkins, _http._tcp.jenkins.default.svc.cluster.local, SRV with value 10 100 80 jenkins.default.svc.cluster.local_slave._tcp.jenkins, _slave._tcp.jenkins.default.svc.cluster.local, SRV with value 10 100 50000 jenkins.default.svc.cluster.local
Jenkins 从服务复制控制器
Jenkins 从服务可以以复制控制器来运行从而确保一直会有从服务来运行 Jenkins 的任务。注意,此步骤可以加深对 Kubernetes 是如何工作的有所帮助,在这个特殊的 Jenkins 实例中,使用了 Jenkinks Kubernnetes 插件是一个更好的方案,此插件可以自动的根据队列中任务的数量来动态的创建从服务,且可隔离任务的执行。
在jenkins-slaves.yml中所定义的:
-–
apiVersion: “v1”
kind: “ReplicationController”
metadata:
name: “jenkins-slave”
labels:
name: “jenkins-slave”
spec:
replicas: 1
template:
metadata:
name: “jenkins-slave”
labels:
name: “jenkins-slave”
spec:
containers:
-
name: “jenkins-slave”
image: “csanchez/jenkins-swarm-slave:2.0-net-tools”
command:
- “/usr/local/bin/jenkins-slave.sh”
- “-master”
- “ http://jenkins :$(JENKINS_SERVICE_PORT_HTTP)”
- “-tunnel”
- “jenkins:$(JENKINS_SERVICE_PORT_SLAVE)”
- “-username”
- “jenkins”
- “-password”
- “jenkins”
- “-executors”
- “1”
livenessProbe:
exec:
command:
- sh
- -c
- “netstat -tan | grep ESTABLISHED”
initialDelaySeconds: 60
timeoutSeconds: 1
在此例中,我们打算让 Jenkis 从服务自动的连接到 Jenkins 主服务,替代了 Jenkins 所依赖的多播发现。为此我们需要指向 swarm 插件到在 Kubernetes 中运行的主机,同时指定 http 端口(使用`-master`)和从服务端口(使用`-tunnel`)。 我们使用了来自 Jenkins 服务的定义的一系列值的组合,由 SkyDNS 所提供的 Jenkins 主机名,以及 Kubernetes 注入的环境变量`JENKINS_SERVICE_PORT_HTTP`和`JENKINS_SERVICE_PORT_SLAVE`,在服务名称之后命名,在服务中定义了每个端口(http 和从服务)。我们还使用了环境变量`JENKINS_SERVICE_HOST`替代了`jenkins`主机名。被覆盖的镜像命令以此方式来配置容器,重复利用现有的镜像对于服务发现有好处。它也可以在 pod 的定义下完成。关于属性`livenessProbe`所覆盖的内容在下面的自我修复章节中会提及。 使用`kubectl`来创建复制:
$ kubectl create -f jenkins-slaves.yml
Pod 的列表会展示出新创建的,具体启动的数量要看在复制控制器中所定义的数量,我们的例子是一个:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-gs7h9 1/1 Running 0 2m
jenkins-slave-svlwi 0/1 Running 0 4s
第一次运行`jenkins-swarm-slave`镜像到节点会从 Docker 的仓库上下载它,然后稍等一会,从服务就会自动连接到 Jenkins 服务。`kubectl logs`可以用于调试任何的启动问题。 复制控制器可以自动的扩展到想要的数量: `<span>$ kubectl scale replicationcontrollers --replicas</span>=<span>2 jenkins-slave</span>`再次列出 pod 就可以看到新增加的复制了:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-gs7h9 1/1 Running 0 4m
jenkins-slave-svlwi 1/1 Running 0 2m
jenkins-slave-z3qp8 0/1 Running 0 4s
 ## 回滚更新 Kubernetes 还支持回滚更新的概念,在某一刻只有一个 pod 可更新。基于新的`jenkins-slaves-v2.yml`配置文件定义了新的复制控制器配置,运行下面的命令,此命令是让 Kubernetes 每 10 秒更新一次 pod。
$ kubectl rolling-update jenkins-slave –update-period=10s -f jenkins-slaves-v2.yml
Creating jenkins-slave-v2
At beginning of loop: jenkins-slave replicas: 1, jenkins-slave-v2 replicas: 1
Updating jenkins-slave replicas: 1, jenkins-slave-v2 replicas: 1
At end of loop: jenkins-slave replicas: 1, jenkins-slave-v2 replicas: 1
At beginning of loop: jenkins-slave replicas: 0, jenkins-slave-v2 replicas: 2
Updating jenkins-slave replicas: 0, jenkins-slave-v2 replicas: 2
At end of loop: jenkins-slave replicas: 0, jenkins-slave-v2 replicas: 2
Update succeeded. Deleting jenkins-slave
jenkins-slave-v2
$ kubectl get replicationcontrollers
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
jenkins jenkins csanchez/jenkins-swarm:1.625.1-for-volumes name=jenkins 1
jenkins-slave-v2 jenkins-slave csanchez/jenkins-swarm-slave:2.0 name=jenkins-slave-v2 2
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-gs7h9 1/1 Running 0 36m
jenkins-slave-v2-7jiyn 1/1 Running 0 52s
jenkins-slave-v2-9gip7 1/1 Running 0 28s
在此例中,真正并没有发生什么,除了复制控制器的名称,但是其它的任何参数都是可以更改的(docker 镜像、环境等等)。
-–
apiVersion: “v1”
kind: “ReplicationController”
metadata:
name: “jenkins-slave-v2”
labels:
name: “jenkins-slave”
spec:
replicas: 2
template:
metadata:
name: “jenkins-slave”
labels:
name: “jenkins-slave-v2”
spec:
containers:
-
name: “jenkins-slave”
image: “csanchez/jenkins-swarm-slave:2.0-net-tools”
command:
- “/usr/local/bin/jenkins-slave.sh”
- “-master”
- “ http://$ (JENKINS_SERVICE_HOST):$(JENKINS_SERVICE_PORT_HTTP)”
- “-tunnel”
- “$(JENKINS_SERVICE_HOST):$(JENKINS_SERVICE_PORT_SLAVE)”
- “-username”
- “jenkins”
- “-password”
- “jenkins”
- “-executors”
- “1”
livenessProbe:
exec:
command:
- sh
- -c
- “netstat -tan | grep ESTABLISHED”
initialDelaySeconds: 60
timeoutSeconds: 1
## 自我修复 使用 Kubernetes 的一个好处就是自动管理和恢复容器。如果说运行 Jenkins 服务的容器宕掉了,无论任何的原因,对于实例来讲就是一个运行的进程崩溃了,Kubernetes 会接到通知,然后在几秒钟之后就会再重新创建一个容器。正如我们再前面所提到的,使用复制控制器可以确保即使是节点宕掉了,所定义的复制数量依然会照旧运行。Kubernetes 会采取必要的手段来确保在集群中新启动的 pod 是在不同的节点上的。 应用程序指定的健康检查可以使用 [livenessProbe](http://kubernetes.io/v1.0/docs/user-guide/liveness/) 来创建,允许作 HTTP 检查以及在 pod 中的每一个容器中执行命令。如果失败的话,容器就会被重启。 举例说明,要监控 Jenkins 是能够服务于 HTTP 请求的,将下列代码添加到 Jenkins 主容器的定义中:
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
我们也可以监控我们的从服务是真的连接到了主服务上了。之所以有必要是因为如果 Jenkins 主服务重启到话,会丢失原来所连接到从服务的,而从服务会持续的尝试连接到原来的主服务,但是会失败,那么我们就需要检查从服务连接到主服务的情况。
livenessProbe:
exec:
command:
- sh
- -c
- “netstat -tan | grep ESTABLISHED”
initialDelaySeconds: 60
timeoutSeconds: 1
### Vagrant 我们将 Jenkins 主服务的 pod 终止,Kubernetes 会在创建一个。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-7yuij 1/1 Running 0 8m
jenkins-slave-7dtw1 0/1 Running 0 6s
jenkins-slave-o3kt2 0/1 Running 0 6s
$ kubectl delete pods/jenkins-7yuij
pods/jenkins-7yuij
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-jqz7z 1/1 Running 0 32s
jenkins-slave-7dtw1 1/1 Running 0 2m
jenkins-slave-o3kt2 1/1 Running 1 2m
Jenkins Web 用户界面仍然可以由原来的一些地址访问的到。Kubernetes 服务会掌管转发连接到新的 pod。运行 Jenkins 数据目录在卷中,我们保证了即使是容器宕掉仍然能够保持数据,所以我们没有丢失 Jenkins 任何的任务或已经创建的数据。而且因为 Kubernetes 代理了每个节点的服务,从服务会自动的重新连接到主服务,还毋需关心它运行在哪里!而且即使是如果从服务的容器宕掉的情况亦发生了,系统会自动创建一个新的容器,而且归功于服务发现的能力,可让其自动的加入的从服务池。 ### GKE 一旦发生了节点宕掉这种事情,Kubernetes 会自动的重新调度 pod 到不同的地点。我们使用的是手动的将运行 Jenkins 主服务的节点关闭。
$ kubectl describe pods/jenkins-gs7h9 | grep Node
Node: gke-kubernetes-jenkins-e46fdaa5-node-chiv/10.240.0.3
$ gcloud compute instances list
gcloud compute instances listNAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
gke-kubernetes-jenkins-e46fdaa5-node-5gvr us-central1-f n1-standard-1 10.240.0.4 104.154.35.119 RUNNING
gke-kubernetes-jenkins-e46fdaa5-node-chiv us-central1-f n1-standard-1 10.240.0.3 104.154.82.184 RUNNING
gke-kubernetes-jenkins-e46fdaa5-node-mb7s us-central1-f n1-standard-1 10.240.0.2 146.148.81.44 RUNNING
$ gcloud compute instances delete gke-kubernetes-jenkins-e46fdaa5-node-chiv
The following instances will be deleted. Attached disks configured to
be auto-deleted will be deleted unless they are attached to any other
instances. Deleting a disk is irreversible and any data on the disk
will be lost.
- [gke-kubernetes-jenkins-e46fdaa5-node-chiv] in [us-central1-f]
Do you want to continue (Y/n)? Y
Deleted [https:
$ gcloud compute instances list
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
gke-kubernetes-jenkins-e46fdaa5-node-5gvr us-central1-f n1-standard-1 10.240.0.4 104.154.35.119 RUNNING
gke-kubernetes-jenkins-e46fdaa5-node-mb7s us-central1-f n1-standard-1 10.240.0.2 146.148.81.44 RUNNING
过一会,Kubernetes 知道了运行 pod 的那个节点宕掉了,它就会在另外一台节点创建一个新的叫做`jenkins-44r3y`的 pod。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-44r3y 1/1 Running 0 21s
jenkins-slave-v2-2z71c 1/1 Running 0 21s
jenkins-slave-v2-7jiyn 1/1 Running 0 5m
$ kubectl describe pods/jenkins-44r3y | grep Node
Node: gke-kubernetes-jenkins-e46fdaa5-node-5gvr/10.240.0.4
接着打开浏览器,使用原来的 IP 来访问,看到的仍然是一样的 Jenkins 主服务的用户界面,因为它会自动的转发到运行 Jenkins 主服务的节点。你所创建的任何 jenkins 任务都会保留,因为数据存放在 Google 持久磁盘中,而持久磁盘 Kubernetes 会自动的挂载到新的容器实例。 注意,稍后一段时间,GKE 会意识到其中一个节点宕掉了,就会再启动一个实例,保持我们集群的规模。
$ gcloud compute instances list
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
gke-kubernetes-jenkins-e46fdaa5-node-5gvr us-central1-f n1-standard-1 10.240.0.4 104.154.35.119 RUNNING
gke-kubernetes-jenkins-e46fdaa5-node-chiv us-central1-f n1-standard-1 10.240.0.3 104.154.82.184 RUNNING
gke-kubernetes-jenkins-e46fdaa5-node-mb7s us-central1-f n1-standard-1 10.240.0.2 146.148.81.44 RUNNING
## 删除 `kubectl`提供了删除复制控制器、pod、和服务定义的命令。 要停止复制控制器,设置复制数为 0,这样就会让所有相关联的 pod 终止。
$ kubectl stop rc/jenkins-slave-v2
$ kubectl stop rc/jenkins
删除服务:
$ kubectl delete services/jenkins
## 总结 Kubernetes 可以跨多个服务器来管理 Docker 的部署,简化了长期运行的执行任务,以及分布式的 Docker 容器。通过抽象基础设施概念和基于状态而不是进程工作原理,它提供了集群的简单定义,包括了很多可用性方面的企业级特性,诸如自我修复能力、集中的日志、服务发现、动态 DNS、网络隔离、以及资源配额。简而言之,Kubernetes 让管理 Docker 集群更加点容易。 ## 关于作者 **Carlos Sanchez** 在自动化,软件开发质量,QA 以及运维等方面有超过 10 年的经验,范围涉及从构建工具、持续集成到部署自动化,DevOps 最佳实践,再到持续交付。他曾经为财富 500 强的公司实施过解决方案,在多家美国的创业公司工作过,最近的任职的公司叫做 MaestroDev,这也是他一手创建的公司。Carlos 曾经在世界各地的各种技术会议上作演讲,包括 JavaOne, EclipseCON, ApacheCON, JavaZone,Fosdem 以及 PuppetConf。非常积极的参与开源,他是 Apache 软件基金会的成员,同时也是其它一些开源团体的成员,为很多个开源项目做个贡献,这里举几个例子,有 Apache Maven,Fog 以及 Puppet。 ** 查看英文原文:**[Scaling Docker with Kubernetes V1](http://www.infoq.com/articles/scaling-docker-kubernetes-v1)

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...












评论