

在ArchSummit深圳2019大会上,蔡東邦 (DB Tsai)讲师做了《把嵌套列表作为 Apache Spark SQL 的首选》主题演讲,主要内容如下。
演讲简介:
Making Nested Columns as First Citizen in Apache Spark SQL
Apple Siri is the world’s largest virtual assistant service powering every iPhone, iPad, Mac, Apple TV, Apple Watch, and HomePod. We use large amounts of data to provide our users the best possible personalized experience. Our raw event data is cleaned and pre-joined into an unified data for our data consumers to use. To keep the rich hierarchical structure of the data, our data schemas are very deep nested structures. In this talk, we will discuss how Spark handles nested structures in Spark 2.4, and we’ll show the fundamental design issues in reading nested fields which is not being well considered when Spark SQL was designed. This results in Spark SQL reading unnecessary data in many operations. Given that Siri’s data is super nested and humongous, this soon becomes a bottleneck in our pipelines.
Then we will talk about the various approaches we have taken to tackle this problem. By making nested columns as first citizen in Spark SQL, we can achieve dramatic performance gain. In some of our production queries, the speed-up can be 20x in wall clock time and 8x less data being read. All of our work will be open source, and some has already been merged into upstream.
参考译文:
Apple Siri 是世界上最大的虚拟助理服务,为每部 iPhone,iPad,Mac,Apple TV,Apple Watch 和 HomePod 提供服务支持。我们使用大量数据来为用户提供最佳的个性化体验。所有的原始事件数据被清理并预先加入到统一数据中,供我们的数据使用者使用。为了保持数据的丰富层次结构,我们的数据模式采用了非常深的嵌套结构。
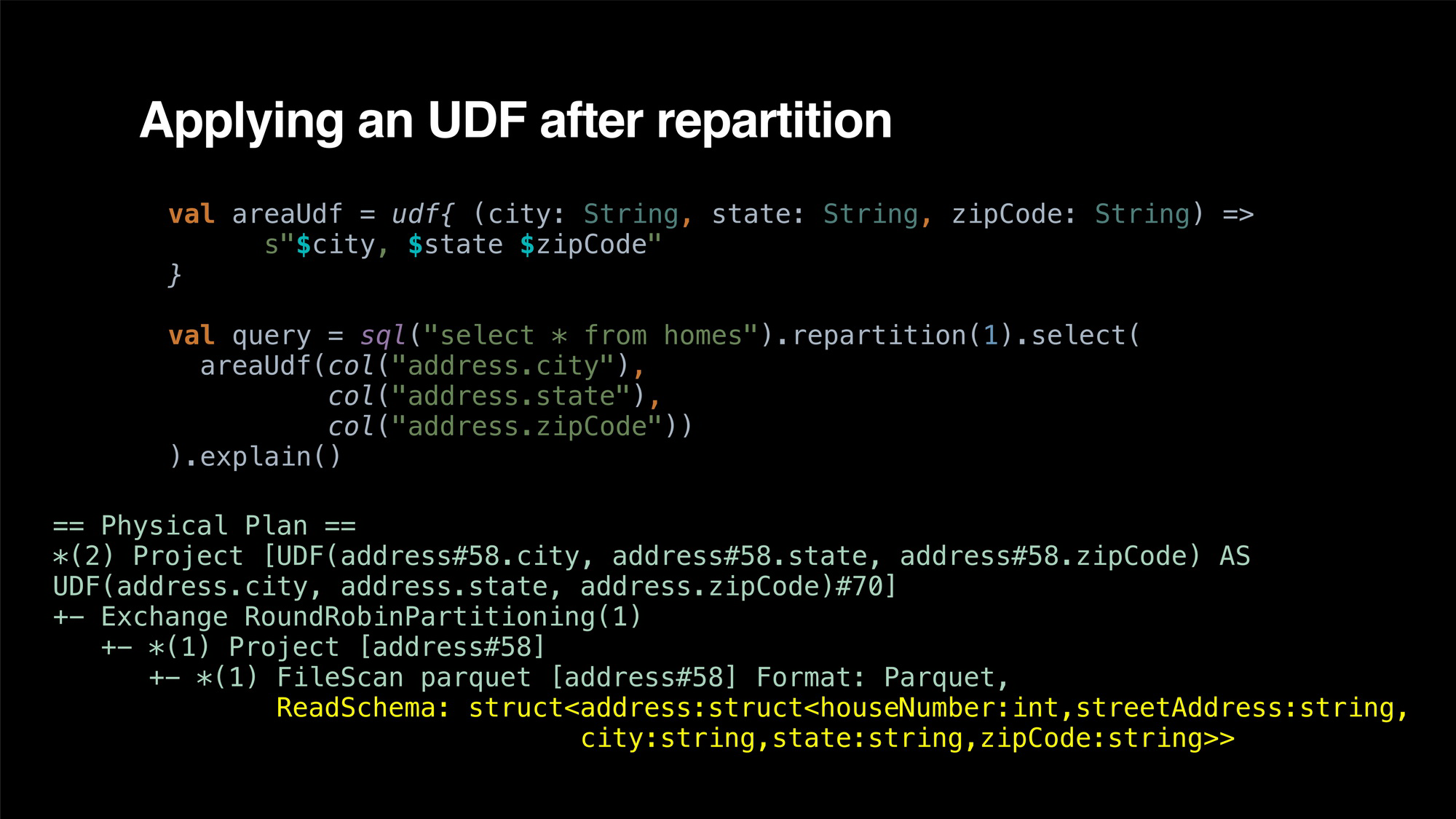
在本次演讲中,我将讨论 Spark 如何处理 Spark 2.4 中的嵌套结构,还会展示读取嵌套字段时的基本设计问题,这些问题在设计 Spark SQL 时并未得到充分考虑。这就导致了 Spark SQL 在许多操作中读取不必要的数据。鉴于 Siri 超级嵌套的数据非常庞大,它很快就成了瓶颈所在。
之后,我会介绍为解决这个问题所采取的各种方法。将嵌套列作为 Spark SQL 中的第一个公民,在性能上获得显着的提升。在我们的一些生产查询中,加速 20 倍,读取的数据减少 8 倍。我们所有的工作都将开源,有些已经合并到了核心区域。
讲师介绍:
蔡東邦 (DB Tsai)
Apple Staff Software Engineer & Apache Spark PMC
DB Tsai is an Apache Spark PMC / Committer and an open source and staff software engineer at Apple Siri. He implemented several algorithms including linear models with Elastici-Net (L1/L2) regularization using LBFGS/OWL-QN optimizers in Apache Spark. Prior to joining Apple, DB worked on Personalized Recommendation ML Algorithms at Netflix. DB was a Ph.D. candidate in Applied Physics at Stanford University. He holds a Master’s degree in Electrical Engineering from Stanford.
译文参考:
蔡東邦老师是 Apache Spark PMC / Committer,同时也是 Apple Siri 的主任工程师。他将多个算法应用到了 Apache Spark 当中,包括使用了 LBFGS / OWL-QN 优化器 的 Elastici-Net(L1 / L2)正则化的线性模型。在加入 Apple Siri 之前,蔡老师在 Netflix 从事个性化推荐机器学习算法的研究工作。目前是斯坦福大学应用物理专业的博士候选人,也获得了斯坦福大学电气工程硕士学位。









完整演讲 PPT 下载链接:
https://archsummit.infoq.cn/2019/shenzhen/schedule

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论