
在本文中,我将分享我通过 SQL 和函数表示任务对 Llama 2 和 GPT 3.5 进行微调的比较实验。总体结果如下:
GPT 3.5 在两个数据集上与 LoRA 微调的 CodeLlama 34B 相比,性能要好一些;
GPT 3.5 的训练成本高出 4 到 6 倍(部署成本甚至更高)。
SQL 任务的代码和数据在这里(https://github.com/samlhuillier/spider-sql-finetune),函数表示任务的代码和数据在这里(https://github.com/samlhuillier/viggo-finetune)。
为什么要做这个比较?对 GPT 3.5 进行微调的成本是很高的。我想通过这个实验看看手动微调模型是否可以在成本很低的情况下让性能接近 GPT 3.5。有趣的是,它们确实可以!
结果
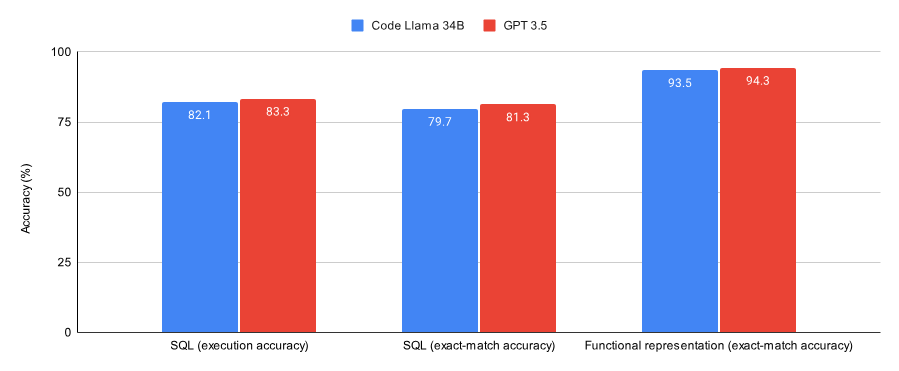
CodeLlama 34B 和 GPT 3.5 执行 SQL 任务和函数表示任务的性能。
GPT 3.5 在这两项任务上表现出稍好的准确性。在使用模型生成 SQL 查询时,我还使用执行准确性作为比较它们在虚拟数据库上执行查询输出的指标(精确匹配准确性是指字符级别的比较)。
训练成本
注:我使用的是 vast.ai 提供的 A40 GPU,每小时费用为 0.475 美元。
实验设置
我使用了 Spider 数据集和 Viggo 函数表示数据集的子集,这些都是很好的用于微调的数据集:
它们会教会模型给出期望的输出形式,而不是事实。SQL 和函数表示任务都期望结构化的输出。
预训练的模型不能很好地完成这两项任务。
对于 GPT 3.5 的微调,OpenAI 只允许配置 epoch 的数量。他们建议选择 epoch 的数量。因此,为公平起见,我只对 Llama 进行最少的超参数微调,允许 OpenAI 选择 epoch 的数量,并训练 Llama 在评估数据集上收敛。
Llama 的架构
我做出的两个关键决定是使用 Code Llama 34B 和 Lora 微调(而不是全参数):
OpenAI 很可能会做一些适配器/非全参数微调。
Anyscale 的一篇文章(https://www.anyscale.com/blog/fine-tuning-llms-lora-or-full-parameter-an-in-depth-analysis-with-llama-2)指出,对于 SQL 和函数表示等任务,LoRA 几乎可以与全参数微调媲美。
我使用的 LoRA 适配配置是这样的:
config = LoraConfig( r=8, lora_alpha=16, target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", ], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM", )我尝试在所有线性层使用适配配置(正如Qlora论文所建议的那样),发现几乎没有性能提升。类似地,将 r 增加到 16 只会消耗更多的计算量,而几乎没有提供性能上的好处。
数据集
SQL 提示词示例:
You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.You must output the SQL query that answers the question.### Input:Which Class has a Frequency MHz larger than 91.5, and a City of license of hyannis, nebraska?### Context:CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)### Response:我没有使用完整的 Spider 数据集,它的数据库 Schema 是这样的:
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]相反,我选择使用 sql-create-context(https://huggingface.co/datasets/b-mc2/sql-create-context)数据集和 Spider 数据集的交集。因此,提供给模型的上下文是一个 SQL 创建命令(我这么做实际上完全是为了节省节点数):
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)函数表示提示词示例:
Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values.This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute'].The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']### Target sentence:I remember you saying you found Little Big Adventure to be average. Are you not usually that into single-player games on PlayStation?### Meaning representation:输出是这样的:
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])评估
两个模型收敛得都很快:
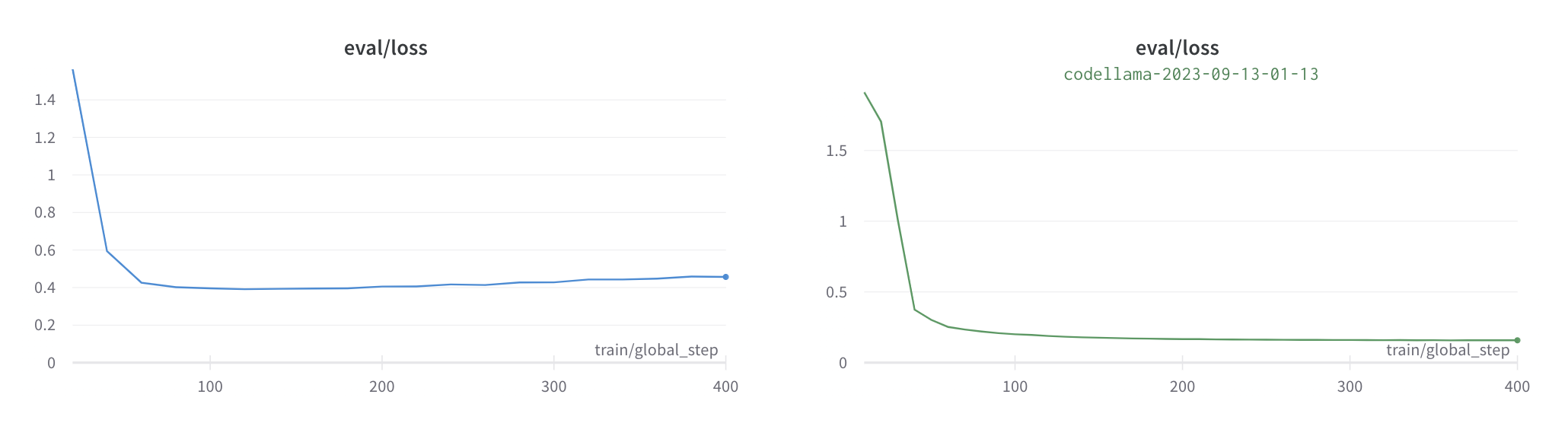
图中显示了在训练过程中模型在评估集上的损失。
对于 SQL 任务,我还使用 Spider 评估工具(https://github.com/taoyds/test-suite-sql-eval)计算 SQL 查询的执行准确性。评估工具会构建一个虚拟数据库,并将实际的输出与 GPT3.5 和 Llama 2 的查询输出进行比较。
结论
总的来说,通过这个经验,我觉得对 GPT 3.5 进行微调是为了初始验证或构建 MVP,而除此之外,像 Llama 2 这样的模型可能是你最好的选择。
为什么要对 GPT 3.5 进行微调?
你想要证实微调是解决给定任务/数据集的正确方法;
你想要全托管的体验。
为什么要对像 Llama 2 进行微调?
你想省钱!
你希望最大限度地榨取数据集的性能;
你希望在训练和部署基础设施方面具有充分的灵活性;
你想保留私有数据。
原文链接:




