

互联网发展至今,已离不开数据,使得很多公司格外青睐具备数据分析能力的人。迎着这一浪潮,很多人都跃跃欲试,想要掌握数据分析的技能,让自己在职场上更有主动权。
但万事开头难,摆在很多人面前的困扰是,我到底该怎么学数据分析?
我需要掌握 Excel 吗?
数据分析对统计学和数学要求高吗?
没有编程能力还能学数据分析吗?
Python 语言和 R 语言我该选择哪一个?
相信这是不少人的疑惑,之所以会出现这些问题,是因为很多人混淆了数据分析的概念。
广义上的数据分析包括了统计学、增长黑客、相关性分析等,更偏向产品运营,而我们这里所说的数据分析,则是隶属于编程世界里的数据分析,是算法和技术的天下。
作为一个程序员,相信你更需要的是后者。学习数据分析,你最需要掌握的就是 Python 语言、数据预处理以及算法知识。
Python 语言贯穿于数据分析的整个过程,只有掌握 Python,你才能熟练地通过它做数据预处理,以及使用各种算法包。
掌握 Python 之后,你才会使用 Python 的各种机器学习库、第三方工具等,有了它们,数据预处理才会事半功倍。
算法是数据分析的精髓,只有掌握算法,你才能处理各种数据。
那么具体到这三点,该怎么学数据分析呢?
入门:掌握 Python
如果你刚接触数据分析,面对纷繁复杂的算法和工具不知所措,那么,首先你最需要掌握的就是 Python 语言。听起来是不是很不可思议?事实上,Python 是数据分析领域中当之无愧的王者语言,它封装了很多算法工具包,使用起来非常方便。
在专栏里,我用一篇文章快速帮你理解 Python 语言的基础语法,比如输入输出、循环语句、数据类型等。
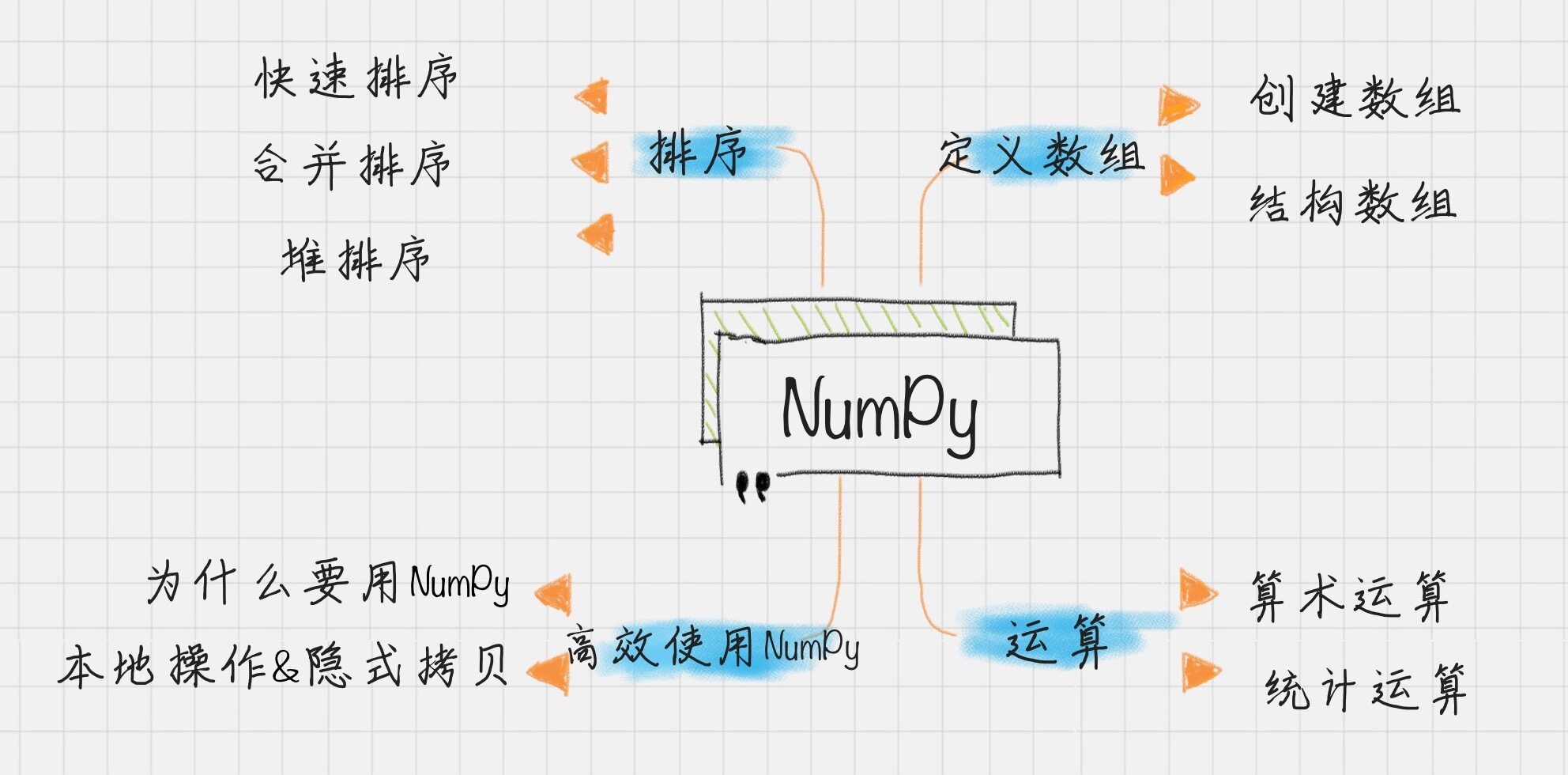
除了 Python 语言之外,你还需要了解 NumPy 和 Pandas 这两个第三方库。NumPy 提供的数据结构是 Python 数据分析的基础,它可以让 Python 的科学计算更加高效。Pandas 则是一个含有更高级数据结构和分析能力的工具包,它的核心数据结构是 Series 和 DataFrame。基于这两种结构,我们可以很方便地处理数据。

新手:使用 Python 工具包进行数据预处理
当你入门 Python 后,接下来就算正式进入数据预处理阶段。“数据分析”涵盖两部分:数据是基础,分析是过程,所以数据的前期准备工作也很重要。
这些工作主要包括:
数据采集
数据清洗
数据集成
数据变换
数据可视化
不要小看这些工作,看似和“分析”不挂钩,其实,这些工作相当于分析前的“备菜过程”,没有“备菜”,何谈“掌勺”?
第一步,采集数据。
你可以用 Python 自动采集数据,也可以使用第三方平台,比如用八爪鱼来采集数据。我用两篇文章分别讲了这两种方法,其中都讲到了 XPath 这个路径语言,它可以通过元素和属性快速帮我们定位位置。
具体的实操方法,可以看下面两篇文章:
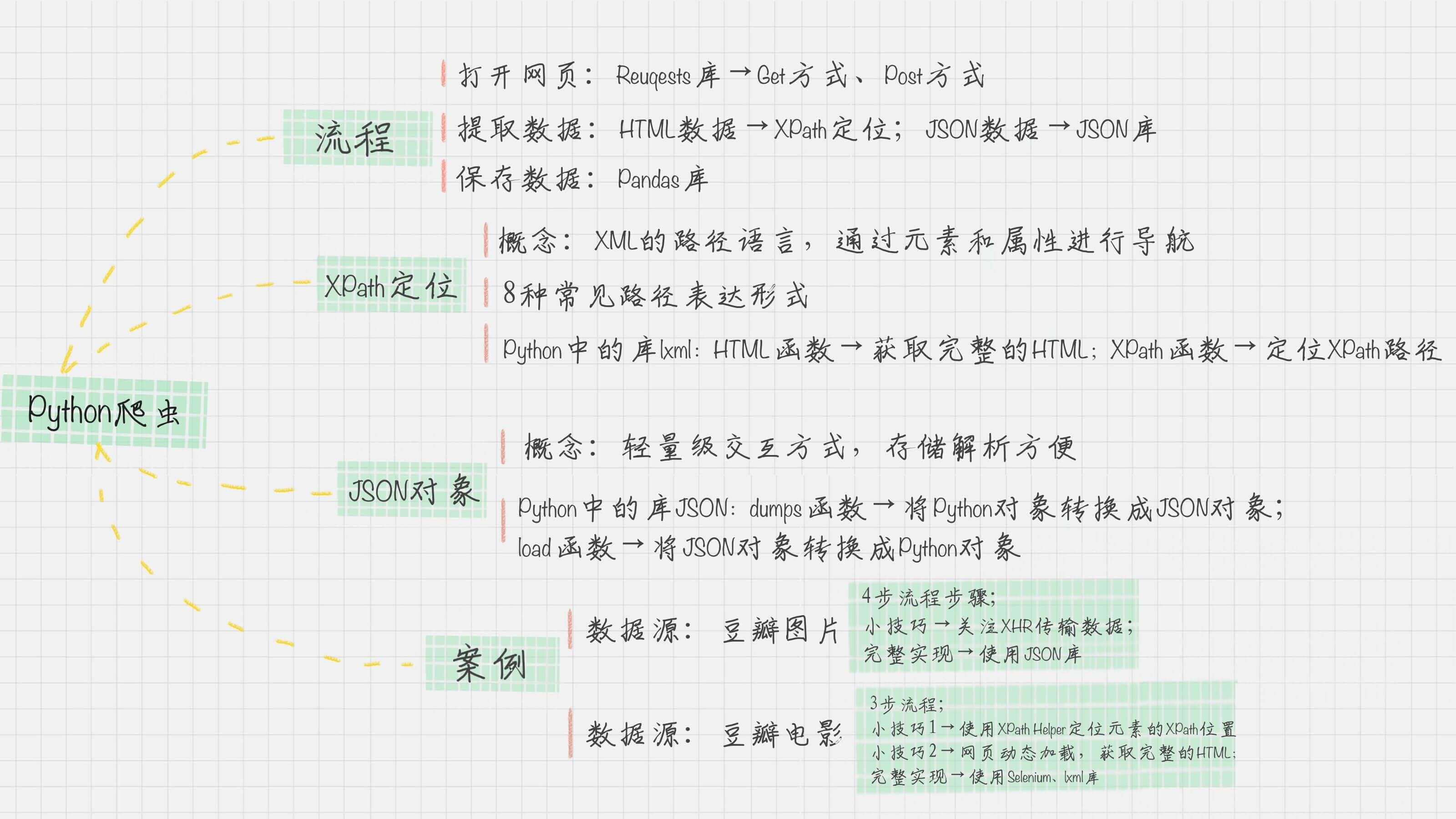
很多时候,我们采集到的数据是杂乱的,可能会遇到各种问题,比如有缺失值、数据单位不统一、有重复值等。这个时候你可以采用“完全合一”的原则清洗数据。
当然,大家最感兴趣的可能还是数据可视化。运用各种酷炫的图片将数据的规律直观地呈现在众人面前,想想是一件特别有成就感的事情,比如天猫双十一的数据大屏等。我们可以用各种工具、编程语言做数据可视化,比如 DataV、Tableau、Python 或者 R 语言。
在专栏中,我主要是用 Python 的 Matplotlib 工具来做数据可视化。Matplotlib 是 Python 的可视化基础库,非常适合入门学习。下面的这几张图就是用 Matplotlib 绘制出来的。
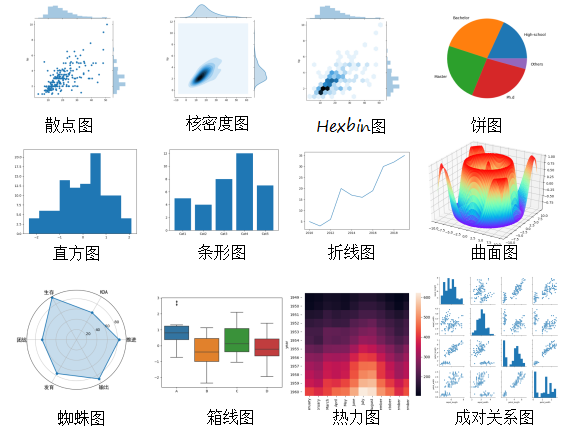
可视化的具体操作方法:
进阶:掌握算法,学会实战
当你掌握了数据分析中基础的操作后,接下来就该正式处理数据了。为了进行数据挖掘任务,数据科学家们提出了各种算法,我在专栏中主要讲解了数据挖掘十大经典算法,根据用途,把它们分为四大类:
分类算法:C4.5、朴素贝叶斯、SVM、KNN、Adaboost 和 CART
聚类算法:K-Means、EM
关联分析:Apriori
连接分析:PageRank
你看到这些算法可能会发愁,看不懂怎么办呢?这个你完全不用担心,我在专栏里用了大篇幅内容来讲解这十大经典算法,每一个算法都有很多的案例去辅助你理解,还提供了一些数据库让你去实操,即学即用。
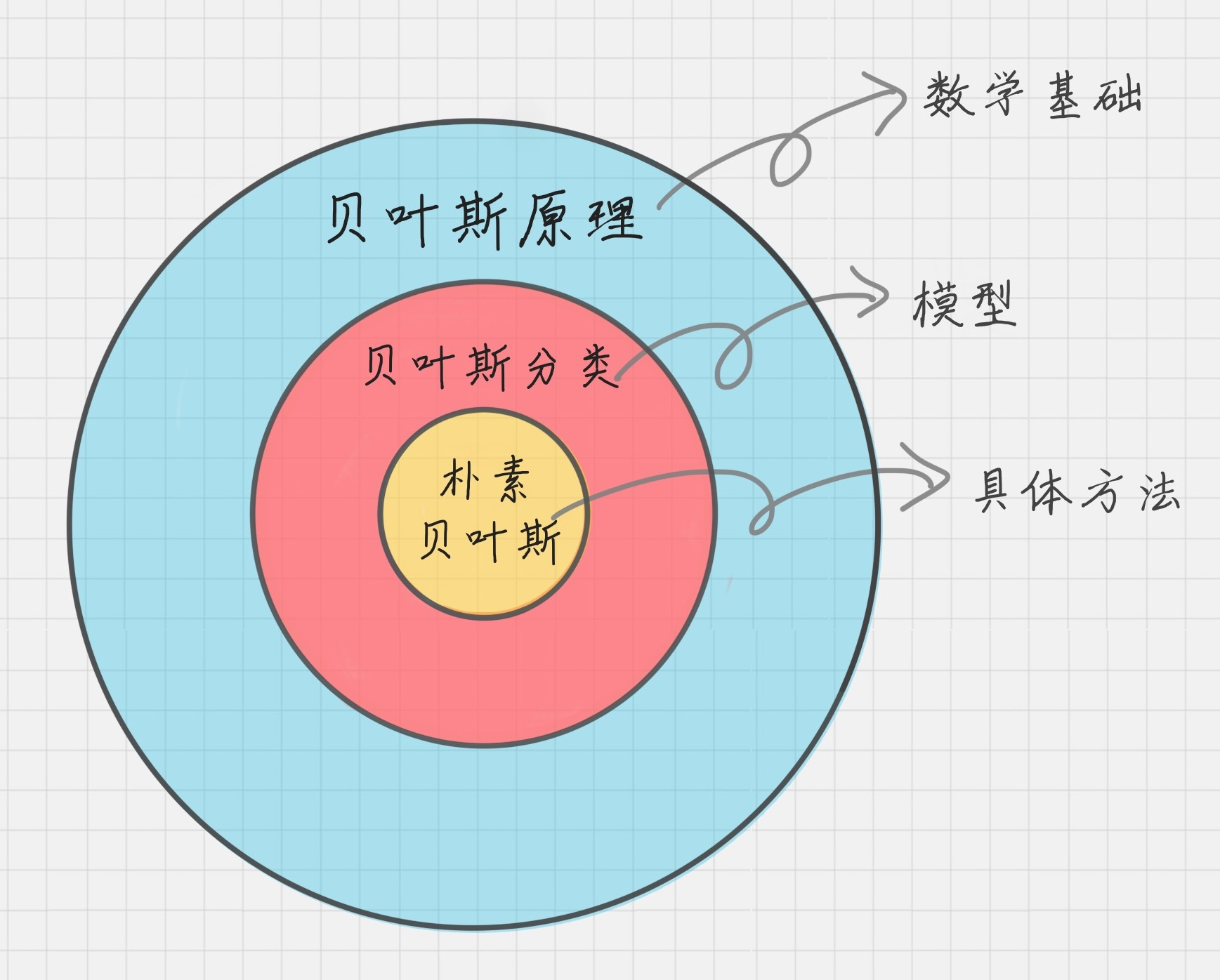
而实际上,你不需要了解这些算法具体的推导过程,只需要了解它们的原理即可。比如在数据挖掘算法中,大名鼎鼎的朴素贝叶斯算法和贝叶斯原理之间是什么关系?通过下面这张图,你可以直观地找到这个问题的答案。
更多详细补充:
为什么我会说不需要了解算法具体的推导过程呢?因为在实际工作中,有很多工具已经帮我们封装好这些算法了,比如 sklearn,你在使用的时候,只要写一行代码,就可以直接引用,只需要调整参数就可以。
当然,虽说 sklearn 封装了数据挖掘所用到的绝大多数算法,但也有一些算法并不能覆盖到,比如图论和网络建模。那么,这个时候我们该怎么办呢?
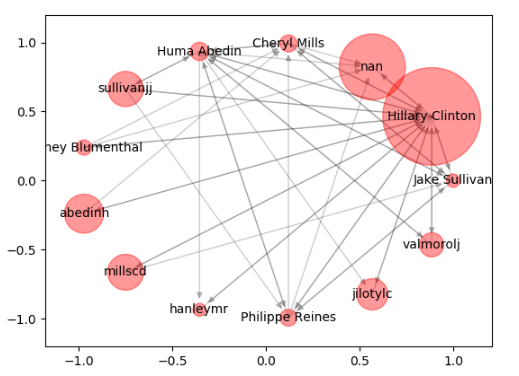
你可以使用 NetworkX,一个用 Python 语言开发的工具,它内置了常用的图论与网络分析算法,可以方便我们进行网络数据分析。比如我们可以直接调用里面的 PageRank 算法,而不用在意具体的计算细节。在专栏中,我用 NetworkX 这一工具分析了希拉里邮件往来人员的关系和彼此之间的权重,帮我们非常直观地呈现出了以下结论图。
当你掌握了多种算法之后,实际工作中还会遇到这类问题:如何选择各种分类器,到底选择哪个分类算法,是 SVM,决策树,还是 KNN?如何优化分类器的参数,以便得到更好的分类准确率?
这两个问题,是数据挖掘核心的问题。当然对于一个新的项目,我们还有其他的问题需要了解,比如掌握数据探索和数据可视化的方式,还需要对数据的完整性和质量做评估。这些内容我在之前的课程中都有讲到过。
这里给到大家一个建议:使用 GridSearchCV 工具对模型参数进行调优。GridSearchCV 是 Python 的参数自动搜索模块,我们只要告诉它参数的范围,它就可以把所有情况都跑一遍,提供最优解。
我在专栏里用“信用卡违约率分析”的案例详细讲解了 GridSearchCV 的使用:
总之,你想要深入数据分析,算法与工具是你必须要攻克的两座大山。当然,我也希望你能认识到,工具只是帮我们实现目的,我们不可以被工具所奴役。数据分析与挖掘最重要的还是思考能力,收集什么数据,用什么工具分析,分析出什么样的结果,用什么方式呈现出来,都需要大家的思考与观察。这也是我在专栏里十分强调的点。
毕竟工具是别人的,但思维和实战经验,才是你自己的。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论