

图算法提供了理解、建模和预测复杂动态的手段,例如资源或信息流、传染或网络故障传播的途径,以及对群体的影响和弹性。
本博文系列旨在帮助读者更好地利用图分析和图算法,以便能够使用 Neo4j 等图数据库更快地有效创新和开发智能解决方案。
上周我们总结了对中心性(Centrality)算法的研究,还研究了亲密中心性(Closeness Centrality) 算法。
这一周,我们开始研究社区发现(Community Detection)算法,并了解强连通分量(Strongly Connected Components,SCC)算法,该算法根据关系的方向定位节点组,其中每个节点都可以从同一组中的每个其他节点到达。通常应用于深度优先搜索。
关于强连通分量
强连通分量算法在有向图找到连接节点的集合,其中每个节点可以在两个方向上从同一集合的任何其他节点到达。通常在图分析过程中的早期使用,经常用来让我们了解图的结构。
SCC 是最早的图算法之一,Tarjan 在 1972 年描述了第一个线性时间算法。将有向图分解成强连通分量是深度优先搜寻算法的经典应用。
什么时候应该使用强连通分量?
在对强大的跨国公司的分析中,SCC 用于查找每个成员直接拥有和 / 或间接拥有其他成员股份的公司集合。虽然它具备诸如降低交易成本、增加信任等优点,但这种结构削弱了市场竞争。更多详情请参阅[《全球企业控制网络》(The Network of Global Corporate Control):http://u6.gg/rDnrz](http://u6.gg/rDnrz
在多跳无线网络中测量路由性能时,SCC 已被用于计算不同网络配置的连接性。更多详情请参阅《多跳无线网络中存在单向链路时的路由性能》(Routing performance in the presence of unidirectional links in multihop wireless networks):http://u6.gg/rDnun
强连通分量算法通常用作许多图算法的第一步,这些算法仅适用于强连接图。在社交网络中,一群人通常有密切的关系(例如,一个班级或者任何其他公共场所的学生)。这些群体中的许多人通常喜欢一些常见的网站或玩常见的游戏。SCC 算法用来找到这样的组,并向组中尚未喜欢这些网站或游戏的人群推荐这些内容。
强连通分量示例
让我们看看强连通分量算法的实际应用。以下 Cypher 语句创建了一个 Twitter 式样的图,其中包含了用户、用户之间的 FOLLOW 关系。
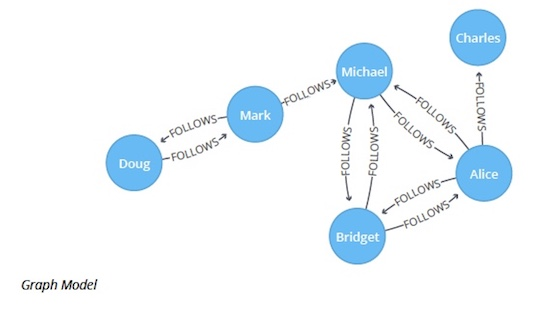
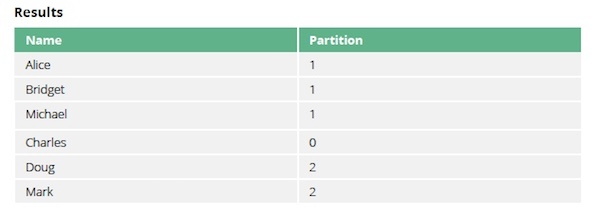
现在我们可以运行强连通分量来查看每个人是否相互链接,执行以下查询:
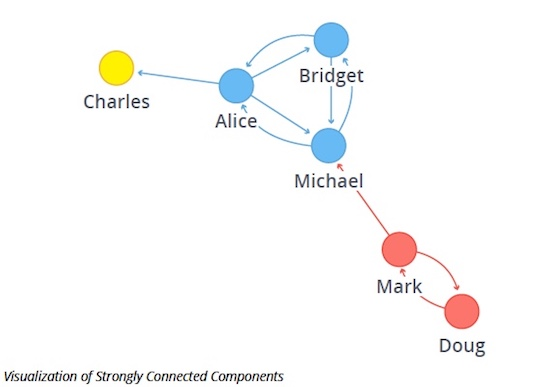
强连通分量的可视化
我们的示例图中有三个强连通分量。
第一个也是最大的分量,有成员 Alice、Bridget 和 Michael,而第二个分量有 Doug 和 Mark。Charies 最终只在自己的分量中,因为从该节点到任何其他节点都之间都没有传出关系。
结论
正如我们所看到的,强连通分量算法通常用于在以识别的集群上独立运行其他算法。作为有向图的预处理步骤,它有助于快速识别断开连接的组。
原文链接:
https://neo4j.com/blog/graph-algorithms-neo4j-strongly-connected-components/


暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论