

就在不久前,我输出过一篇名为「我与 SDK 之间的爱恨悲欢」的文章,描述了我在 SDK 设计上的福与祸,这篇文章内容相对比较故事化,对某个技术细节或设计思路,文中更是只字未提。
就在本月,在分布式系统的 SDK 上发生了不少事情,虽然不至于造成事故,却暴露出我们在分布式系统的 SDK 发布策略制定上的一些不足。
曾经相对粗暴的 SDK 发布策略
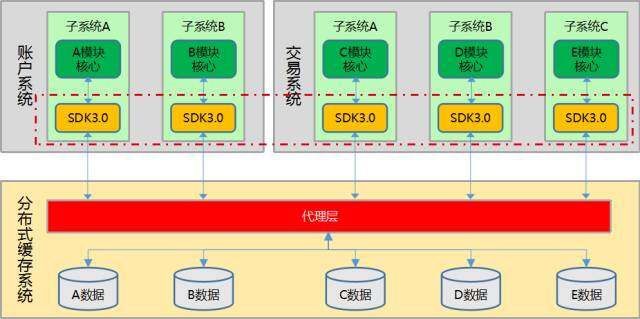
(分布式缓存系统简略交互图 - 强制统一 SDK 版本)
以分布式缓存系统为例,我们最初制定的 SDK 发布策略曾要求所有使用分布式缓存系统的应用系统必须跟随 SDK 的发布节奏进行同步升级,可在执行的过程中我们才发现,这是根本行不通的。
为什么应用系统不愿意跟随 SDK 的发布节奏进行同步升级?
记得当年大智慧的行情客户端所采用的迭代节奏为每月发布,其主要目的是为了更好地为投资者提供股市的分析与预测。但有意思的是,其中有近 1/3 的用户坚持使用最初的怀旧版,无论你给什么优惠就是死活不升,理由很简单 “我就看看行情,那些乱七八糟的新鲜物跟我无关,分析与预测我自己会判断”。
同理,对于应用系统来说,主要职责是「满足业务需求,保障产线服务」,除非某 BUG 已威胁到应用系统服务的稳定,或者负载均衡算法影响到应用系统服务的性能,要不然凭什么要求我陪着你闹腾?
选择应该是自由的,而不是强制的,但在做任何一种选择前,都应评定他的合理性。
当前相对合理的 SDK 发布策略
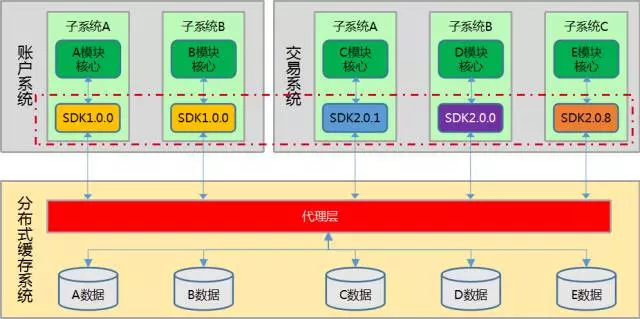
(分布式缓存系统简略交互图 - 支持不同 SDK 版本)
保留当前历史版本前十个为基准,如遭遇修复,将同步进行修复的发布策略
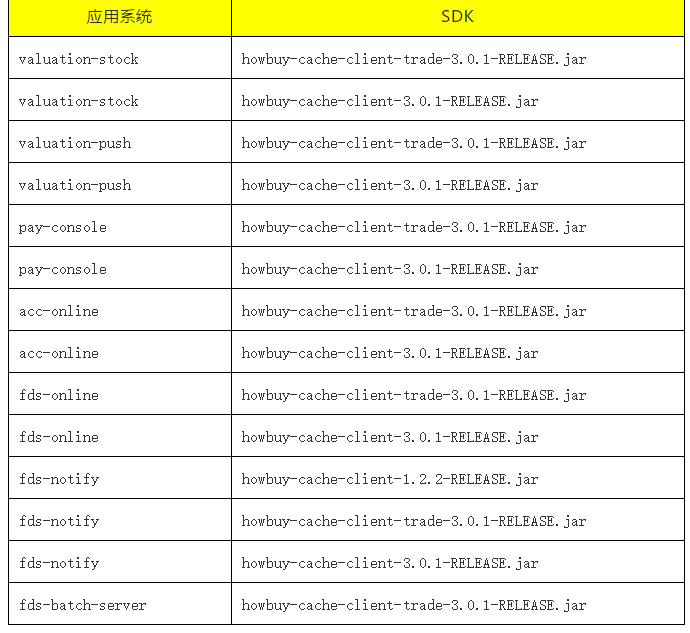
(各系统使用分布式缓存 SDK 的版本清单 - 部分)
我们还做了其他的辅助调整
世间万物就是如此的有趣,就像歌词中唱的那样 “有一半脸笑,就有一半脸哭”,SDK 发布策略是相对合理了,可随之而来却又带来了新的问题。
问题 1:当有基线 BUG 需修复时,研发与测试的成本、风险都比从前高出 N 倍;
问题 2:版本那么多,又是分布式部署,能搞得明白有多少台机器上用到 SDK?谁访问了服务?
问题 3:版本号那么多,每次 Maven 打包时都需要修改打包脚本吗?
针对以上的问题,服务端也需做出对应的功能升级:
1.在 SDK 中设置状态端口,当需要收集部署版本信息时,可以由 WebConsole 通过状态端口,得到当前 SDK 版本号、状态、IP 等信息;
2.当 SDK 访问 Proxy 层时,带入 SDK 层相关信息,用于分析使用;
3.为避免收集信息过程中对性能产生影响,在统一配置中心设置了开关机制,可将各种开发通过 ZK 发布至各 SDK 进行接收使用;
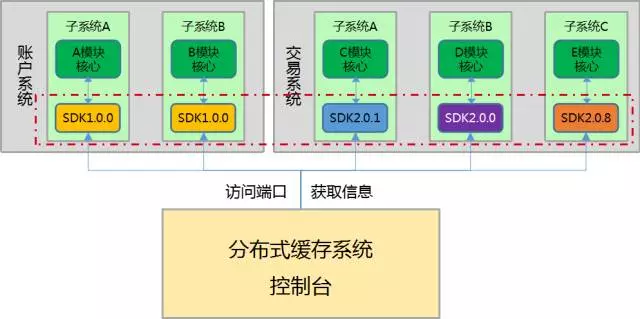
(分布式缓存系统控制台 - 主动获取 SDK 部署信息)
本文转载自头哥侃码公众号。
原文链接:https://mp.weixin.qq.com/s/fpKGVOczD46kyndsnqfaSA

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论