

本文需要读者对诸如 LSTM 和 GRU(包括 seq2seq 编码器-解码器架构)之类的递归神经网络有一定的基础。
众所周知,通用 NLP 的一大障碍是不同的任务(例如文本分类,序列标记和文本生成)需要不同的序列结构。 解决这个问题的一种方法是将这些不同的任务看作是问答形式的问题。比如,文本分类问题可以视为询问模型某段文本表达的情绪是什么,答案可以是“积极”,“消极”或“中立”之一。
论文《有问必答:用于自然语言处理的动态记忆网络》(Ask Me Anything: Dynamic Memory Networks for Natural Language Processing)介绍了一种用于问答形式问题的新型模块化结构。
对于复杂的问答式问题而言,LSTM 和 GRU 的记忆组件可能成为瓶颈。仅一次前馈就想将记忆组件中的所有相关信息积聚起来是非常困难的,因此,该论文背后的关键思想是允许模型根据需要任意访问数据。
尽管乍看起来,这一架构非常复杂,但是它可以分解为许多简单的组件。
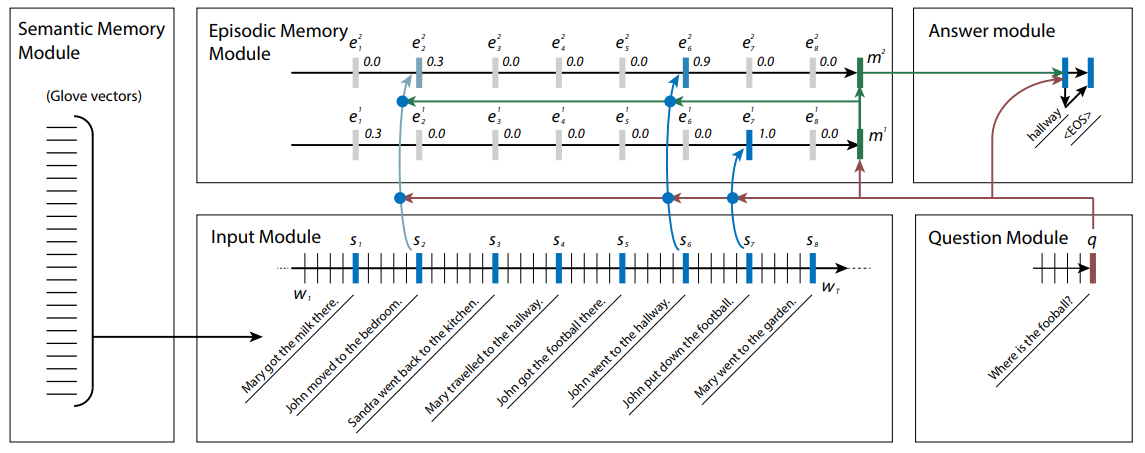
模 型
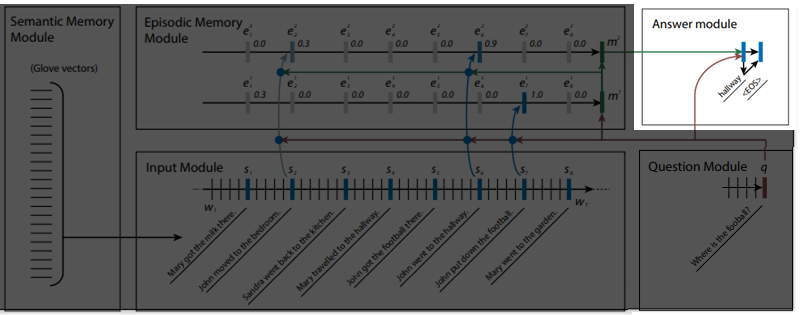
语义记忆模块
语义记忆模块指的是词嵌入(词向量表示),例如 Glove 向量,即输入文本在被传递到输入模块之前被转换成的向量。
输入模块

输入模块即指标准的 GRU(或 BiGRU),每个句子的最后的隐状态是明确可访问的。
问题模块
问题模块也是标准的 GRU,其中待解答的问题作为输入项,并且最后的隐状态是可访问的。
情景记忆模块
这一模块可让输入数据进行多次前馈。在每次前馈时,输入模块中的句子嵌入表示(sentence embedding)作为输入传递到情景记忆模块中的 GRU。 此时,每个句子嵌入表示都会被赋予权重,权重与其被询问的问题的相关性相对应。
对于不同的前馈,句嵌入表示会被赋予不同的权重。 比如,在下面的例子中:

由于句子(1)与问题没有直接关系,因此可能不会在第一次被赋予高权重。 然而,在第一次前馈时,模型发现足球与约翰相关连,因此在第二次前馈时,句子(1)被赋予了更高权重。
在第一次前馈(或第一个“episode”)中,问题嵌入表示(question embedding)'q’被用于计算来自输入模块的句子嵌入表示(sentence embedding)的注意力分数。然后,将句子 sᵢ的注意力得分输入 softmax 层(使得注意力得分总和为 1)或单个 sigmoid 单元来获得 gᵢ。gᵢ是赋予句子 sᵢ的权重,并作为在 timestep i 中 GRU 的输出项的全局门(global gate)。
timestep i 和 episode t 的隐状态计算如下:
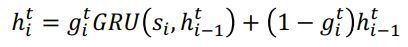
当 g = 0 时,直接复制隐状态:
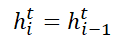
论文中用 mᵗ来表示 GRU 第 t 个 episode 最后的隐状态,可被视为在第 t 个 episode 中发现的事实聚集。 从第二个 episode 开始,mᵗ被用于计算第 t+1 个 episode 中句子嵌入表示以及问题嵌入表示 q 的注意力分数。
计算过程如下:
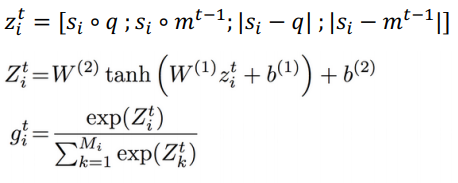
论文采用了许多简单的度量方法来计算 sᵢ和 q 以及 sᵢ和 mᵗ-1 之间的相似性,即元素相乘法和绝对值。然后将连接的结果输入一个 2 层的神经网络来计算 sᵢ的注意力得分。 对于第一个 episode,m⁰被替换为 q。
episode 的数量可以是固定的、预定义的数字,也可以由网络本身确定。在后一种情况下,为输入附加一项特殊的前馈结束表示(end-of-passes representation)。如果门函数(gate function)选择该向量,则停止迭代。
回答模块
回答模块由解码器 GRU 组成。 在每个 timestep,之前的输出将与问题嵌入表示一同作为输入项输入该模块。
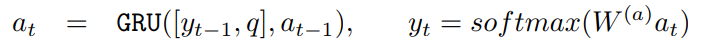
然后使用词汇表上的标准 softmax 生成输出。
解码器通过 m 个向量的一个函数(来自情景记忆模块的 GRU 计算的最后隐藏状态)进行初始化。
情感分析应用
该论文发表时,其模型取得了当时情绪分析领域的最先进结果。
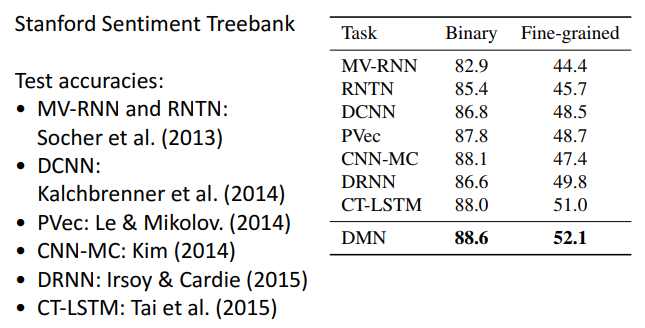
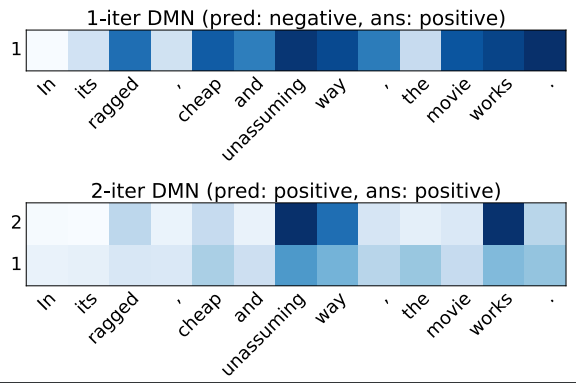
例如,在下面示例中,模型会关注所有的形容词,在仅允许 1 次前馈时,模型会产生不正确的预测。 然而,当允许 2 次前馈时,该模型在第二次前馈时会对积极的形容词倾注非常高的注意力,并产生正确的预测。
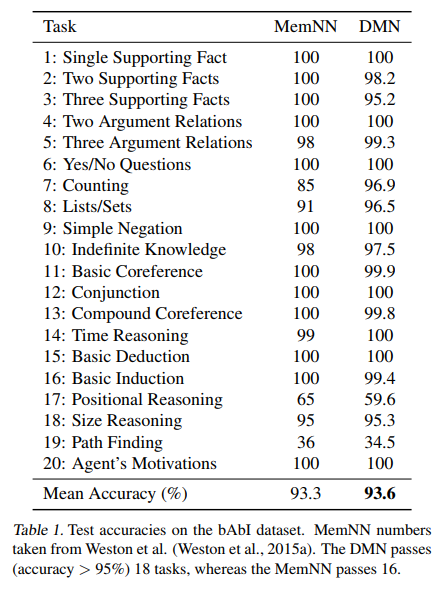
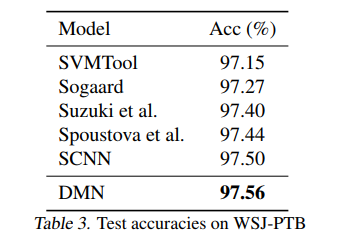
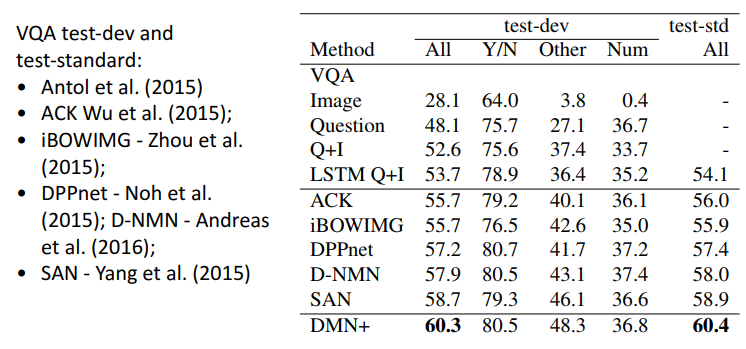
其它数据集的表现
替换模块
模块化的一个重要好处是,可以在不修改任何其他模块的情况下将一个模块替换为另一个模块,只要替换模块具备正确的接口。
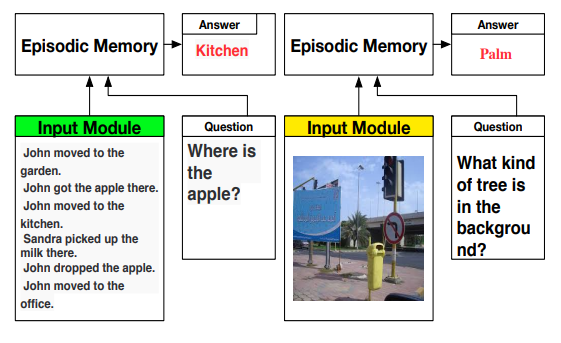
论文《用于视觉和文本问答的动态记忆网络》展示了动态记忆网络在基于图像回答问题中的作用。
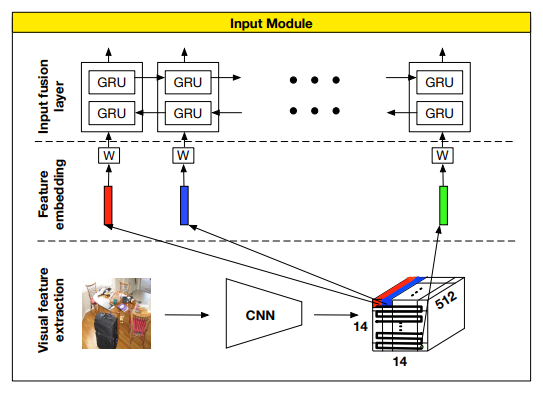
输入模块被另一模块替换,后者基于 CNN 的网络从图像中提取特征向量。然后提取的特征向量会像以前一样输入到事件记忆模块。
阅读原文:
https://towardsdatascience.com/a-step-towards-general-nlp-with-dynamic-memory-networks-2a888376ce8f

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论