

跨 AZ 部署是实现服务高可用较为有效的方法,同时也极具性价比。如果实现了跨 AZ 部署,不仅可以消除服务中的单点,同时还可以逐步建设如下能力:服务隔离,灰度发布,N+1 冗余,可谓一举多得。因此,接下来我们会对有状态的开源软件进行一系列的跨 AZ 部署的介绍,从 Elasticsearch 开始。
最佳实践
首先,我们介绍下 Elasticsearch 基于跨 AZ 部署的最佳实践,下图 1 是一个 Elasticsearch 部署架构示意图,一个集群部署在 3 个 AZ,各个角色说明如下:
专有主节点,主要是通过跨 AZ 来避免脑裂,3 个实例的部署形式是 1+1+1(AZ1:AZ2:AZ3),5 个实例的部署形式是 2+2+1(AZ1:AZ2:AZ3),这样最大可以接受 N 个实例同时故障(2N+1=实例总数);
协调节点,主要是通过跨 AZ 来增加其自身的冗余,每个 AZ 至少部署 2 个实例,防止另外一个 AZ 故障后无可用实例或者形成单点;
数据节点,主要是通过每个 AZ 都存储完整的数据,从而在单个 AZ 整体故障的情况,依然可以对外提供服务,单个 AZ 需要有一定的冗余来避免机器或者交换机故障;
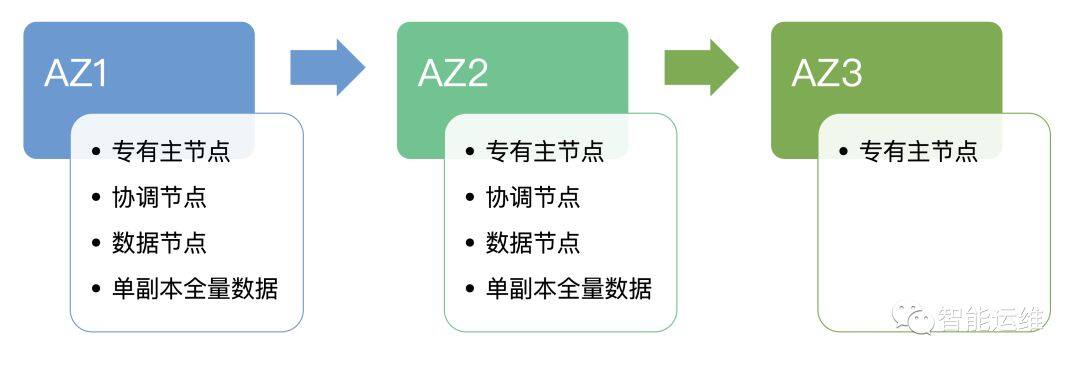
图 1:Elasticsearch 基于 3 个 AZ 的部署架构示意图
成本因素
关于成本,对于这种架构,很多人会有疑问,这样做好归好,任意 1 个 AZ 故障,依然可以对外提供服务,但 2 个 AZ 存储了同样的数据,成本上太浪费了!其实不然,对于所有的分布式存储系统来讲,默认至少都是两个副本(HDFS 默认三副本),从而避免单机故障导致的数据丢失问题。对于 Elasticsearch,我们只是利用他的机架感知特性,将其随机分布的两个副本按照 AZ 维度重新排布,因此并未增加其成本。如下图 2 和 3 所示,正常情况下,每个 shard(可以理解为一组数据)的两个副本均分布在 2 个 AZ 中,当 AZ1 故障后,AZ2 依然可以提供完整的数据集从而继续对外服务
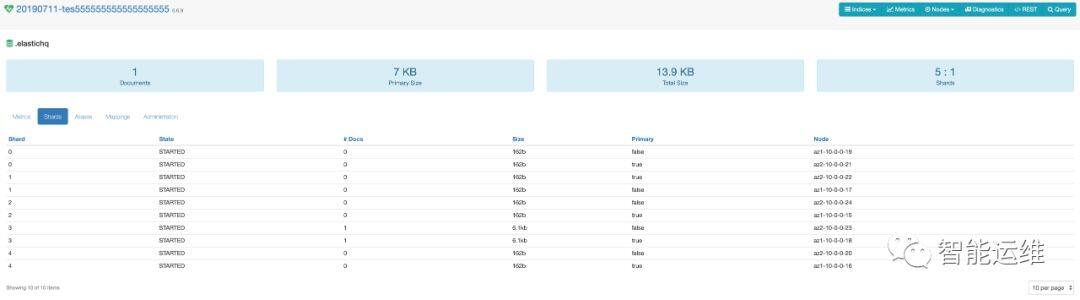
图 2:Elasticsearch 正常状态下双副本的分布情况示意图
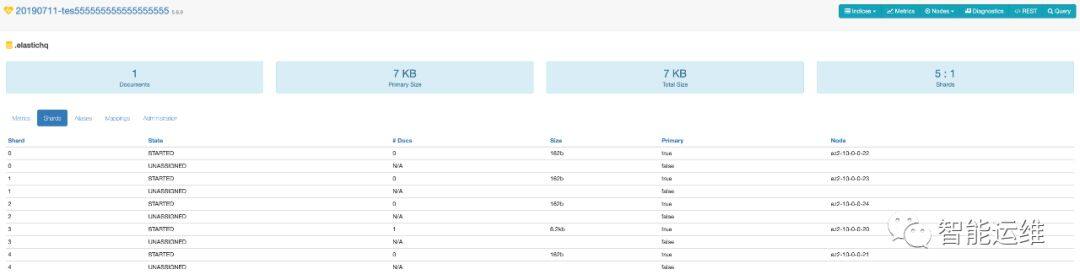
图 3:Elasticsearch 在单个 AZ 故障后单副本的分布情况示意图
实现原理
那如何实现?一般来讲都是基于 Tag 筛选的形式实现,当然前提是需要开源软件自身支持该功能。具体到 Elasticsearch,节点有两种属性(暂不考虑自定义 Tag 的方式),一种是 rack(机架感知),一种是 zone(可用区),从达成跨 AZ 部署的角度看,推荐使用 zone 来实现是较为合适的,也较为简单,仅需要将 AZ 信息维护到 ES 的配置文件中即可。在实际工作中,可以设置两个 ES 的分组,每个分组使用不同的配置文件即可解决。
rack 更多的是从机架角度去进行调度,适合于一个 AZ 内部,将副本分配到不同的机架,从而避免多副本落到同一个机架上,因机架掉电而导致的数据不可用。但机架信息和机器的对应关系维护也是有成本的,更何况在虚拟化场景下,机架和虚拟机/docker 中间还隔着一层宿主机,那更加重了这个维护成本,因此对于有多副本放置要求的场景,更建议使用云厂商提供的高可用组/置放群组来解决。
网络延时
那延时有多大呢?是否会对业务产生显著的影响?先说结论,跨 AZ 传输的延时一般在 2ms 以内,因此对于绝大多数业务来讲,是没有影响的。从理论角度分析,因为多个 AZ 会分布在同一城市的不同地方,距离不超过一百公里,因此光纤传输的延时可以控制在 2ms 以内(基于公有云厂商的经验值而非 SLA)。从实战角度看,大型的互联网公司,也是把多个 AZ 当做一个机房来使用的。因此跨 AZ 的网络延时,对于大部分业务来讲,都是无感的。以笔者实际的 ES 集群为例来进行说明,两个集群节点数均为 26 台,持续的 Indexing Rate 均为 3 万/S 的情况下,使用跨 AZ 部署的集群其 Indexing Latency 比同 AZ 部署的集群高 0.05ms。
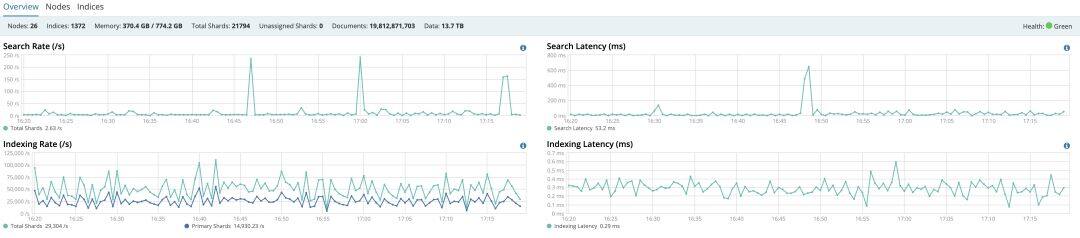
图 4:采用单 AZ 部署的延时 0.27ms
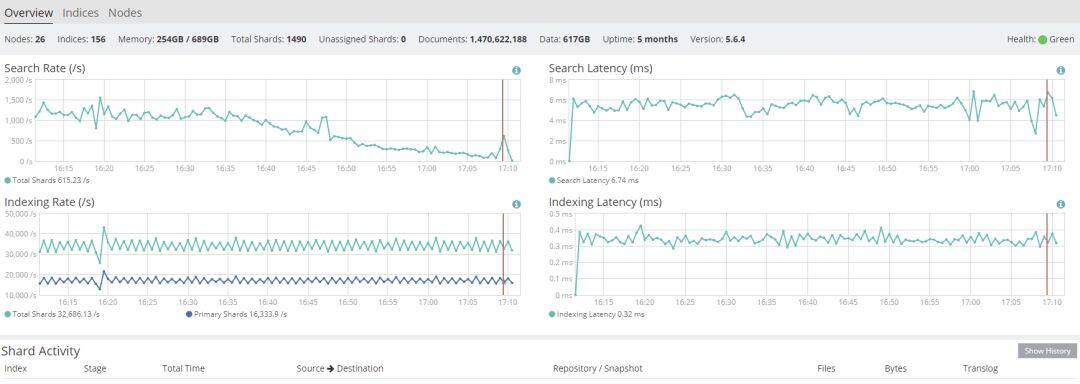
图 5:采用跨 AZ 部署的延时 0.32ms
具体实现
那如何才能让 ES 实现跨 AZ 部署呢,可以参考下面的内容,完整的配置文件可以参考文末提供的测试环境使用的配置
通过修改 elasticsearch.yml 配置文件,增加上面两行配置,跨 AZ 部署的目的就实现了,所有数据的副本会落在两个 AZ 上。如果 AZ1 故障,那么 ES 集群会利用 AZ2 的副本,在 AZ2 内部重新复制一份出来,从而保持整体两副本的要求。但这恰恰也是隐患所在,意味着当 AZ1 故障的时候,AZ2 内部会产生大量的副本复制动作,从而对 ES 集群造成很大的性能压力甚至于稳定性隐患。如果 AZ2 的存储空间不足以支撑完整副本,那么 AZ2 的磁盘就会被打满,导致新数据无法写入,从而导致业务停顿。好在 ES 提供了解决方案,通过强制分配机制,在配置文件中增加下面一行配置,即可解决该问题。这时候,假设 AZ1 故障,那么集群整体就会以单副本的形式继续运行,而不会在 AZ2 内重新复制副本。
数据备份
Elasticsearch 的多副本场景,主要是解决机器、交换机以及单个 AZ 故障下的可用性问题,因此能够在一定程度上避免数据丢失的风险。但需要注意:多副本+权限管控,并不能绝对保证数据不会被破坏。如果数据重要性足够高,还需要将数据进行离线备份,在公有云场景下,可以将数据备份到云存储中。
可能会有同学提问,如果我是两套 ES 做热备,是否还需要将 ES 的数据进行离线备份呢?答案依然是确定的,两套 ES 做热备,能够更好的提升集群整体的可用性,但这两套 ES 会有很多共通的地方,很有可能是同一套管理系统,同一组运维人员,以及同样的 bug。
测试方法
建议尽量使用虚拟机/docker,这样在测试配置以及优化配置的时候,可以通过重建虚机来避免脏数据产生的影响
注意事项
每次修改配置后,需要通过检查集群配置信息确认修改是否生效
数据迁移需要时间,基于日志等信息判断为准
三行配置文件中,node 属性名称需要保持一致
第一行配置需要重启实例,其余可通过 api 设置
写在最后
希望本文提到的 Elasticsearch 多 AZ 的方案,能够在不增加成本,延时的情况下,给大家带来更好的服务可用性。
参考文档
ES 官方的配置文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/allocation-awareness.html
可供测试环境使用的跨 AZ 部署的配置文件:
https://github.com/cloud-op/software/blob/master/elasticsearch/elasticsearch.yml

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论