

轻量级定时任务调度库 Schedule 是一串可用性非常棒的代码。在计算机系统中,他们和操作系统拥有同样久远的历史。在真实世界中,他们也和我们的闹钟一样古老。在计算机世界里,程序员通常需要和操作员(一种职业)预约运行他们的代码。后来,程序员们认为这样的操作太过繁琐,因此就编写了一套调度算法(scheduling algorithms)来代替操作员的工作。
当计算机操作系统出现后,调度算法取代原先的计算机系统操作员将程序指令输入 CPU 内自动执行。但最近几年,随着 CPU 核心数量的增加,计算机的调配算法的复杂性也不断提升。硬件缓存层、RAM 以及硬盘为长期、中期、短期的调度算法提出了不同的需求。
在当前云计算与分布式架构的时代,在软件体系中,调配器逐渐变为一次性甚至不可用的体系结构组件。这些异步任务执行器,往往隐藏于电子邮件、登陆、通知、电子邮件的发送报告等窗口中。
Celery、RabbitMQ、Redis、Google Task Queue API 以及 Amazon 的 SQS 都是分布式环境中任务调度的主要参与者。这篇文章将会介绍传统的任务队列系统、异步执行所处的位置以及上述几款调用工具的优缺点。
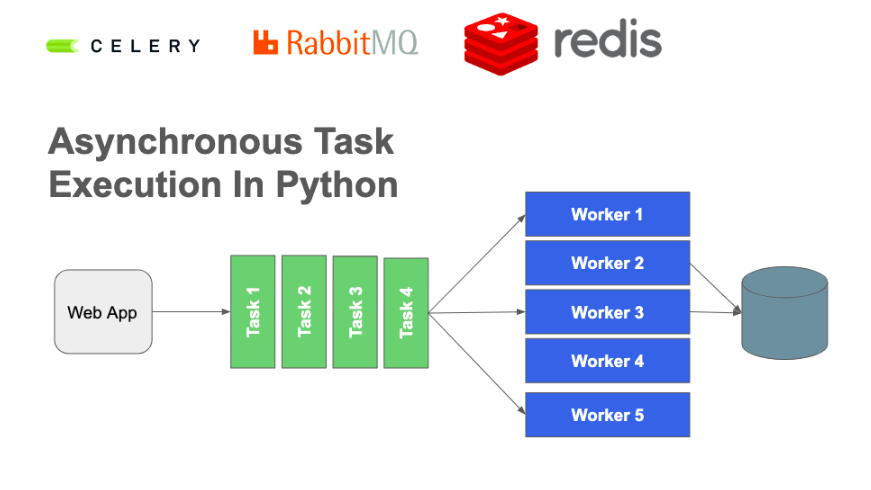
传统任务调度
传统的任务队列在使用数据库时通常拥有两个进程(分为生产者和消费者)。每一个任务被生产者创建后,在数据库里都有相应的状态,比如 NotStarted、Running、Completed、Failed 等等。无论什么时候,守护者任务(如一个从不停止的 Python 程序)都会不间断地对数据库进行查询,以期主动找到未完成的任务并开始运行它。尽管这种方式让队列系统变得更加简单,但依然存在一定的缺陷。
在数据表上进行数据维护,意味着你的数据表单会随着任务的数量不断增长。当数据体量增长得如此之快,并且运维人员不得不处理因数据增长所带来的额外问题时,这种情况就变得非常复杂。
每一个使用者都可以用任务调度来查询数据库,以获取可以运行的调度任务列表。当然,随着数据体量的增长,这样的每一次查询将会变得愈发昂贵。
Cron
Cron 是最简便的,能够设定时间执行异步任务的工具。这个工具专门用来维护一个叫做“crontab”的表。该工具以每分钟调用一次的规律来运作,会自动记录并运行在当前时间段下的每条命令。Cron 具备多种功能,如具备数据备份、临时文件清理以及提醒等。
依下图所示,这里编写了一个 Python 脚本来自动触发 Mac 的通知功能,该通知内容为每 20 分钟休息一下。
注意事项:
1、如果存在跨时区的用户怎么办?每当我们处理时间问题时,也等同于在处理跨时区的问题。Cron 被设置默认运行在系统所属的时区下,我们可以使用 TZ 环境变量来修改。但是如果我们在不同的时区下运行不同的表,则 Cron 并不适合这样的应用场景。
2、如果 Cron 挂掉了怎么办?当脚本执行 Cron 失败时,这个错误会被记录并等待 Cron 的下一次调度来运行。当然这并非处理错误最可靠的方法,我们通常会选择重启这个调度程序,直到达到了某个阈值。
3、伸缩性。如何在固定时间内处理大量的任务?如果其中的某个任务在被调用时占用了大量的内存怎么办?
代码示例——寻宝
这里将会以一个寻宝猎人程序为例去解释上文提到的一些概念。问题和背景都很简单,就是现在有 10000 个文件,其中一个文件包含一个单词宝藏,需要用这个寻宝程序从这些文件中找到宝藏。代码实例如下:
Python 的异步执行
Python 的异步执行在 asyncio 标准库发布后变得越来越流行,尽管这与任务调度程序无关,但是了解它的作用和历史是十分重要的。
线程
Python 线程拥有一个很老的历史,尽管它提出了同时运行多条线程的想法,但实际上却无法实现。为什么?因为 CPython 中存在 GIL(Global Interpreter Lock,防止多线程并发执行机器码的全局锁)。除非你的程序有很多外部事件在等待,否则就无法显现出线程的作用。即使你的笔记本电脑拥有多个核心,由于 GIL 的存在,你会发现它们在 CPU 密集型任务上经常处于空闲状态。
使用线程实现的寻宝猎人程序,你可以通过线程的功能来查看任意范围的文件。
将需要设置的线程统一以 treasure_found 为标志。
异步多重处理
多重处理模块可以很好地解决现成的一些缺陷。有一点很容易理解,GIL 只适用于线程,而不适用于进程,这种特性为实现并行性提供了很好的思路。
Multiprocessing 多处理通常也适用于 CPU 的密集型任务,因为我们可以使用所有的可用内核。当设计多处理程序时,往往会出现多个进程共享同一个队列,并且每一个进程都能读取任务并用于下次的执行加载。
Asyncio–异步 I/O
在上述两个案例中,可以看到线程和进程之间的切换是由 CPU 处理的。在某些情况下,开发者可能更加熟悉什么时候应该通过 CPU 进行上下文切换。Asyncio 让开发者决定一个应用程序在即将停止时如何保留其它的任务及进程,而不是变更进程或线程。
Celery - Python 分布式任务队列
Celery 是一个基于分布式消息传递的异步任务调度工具,它专注于实时操作,同时也支持调度操作。
Celery 主要工作于队列和独立的职程周围。队列通常也被称为消息中间人(Broker),是一个可以异步执行任务的队列系统。通过职程(Worker)ping 向队列来执行任务。
Message Broker—消息中间人
不熟悉的开发者可能经常会混淆 Redis、Celery 以及 RabbitMQ 这三者。上文所提到的队列(Queue)并不是内置在 Celery 中的。并且,由于 Celery 使用 RabbitMQ 或 Redis 来构建队列系统,这就是为什么你会经常在文章中发现这些信息。
Worker—职程
开启一个 Celery 职程时,它会自动创建一个监督进程,会在执行池内推动一系列其它的进程执行。另外,Celery 职程可执行的任务数量取决于执行池中的进程数量。
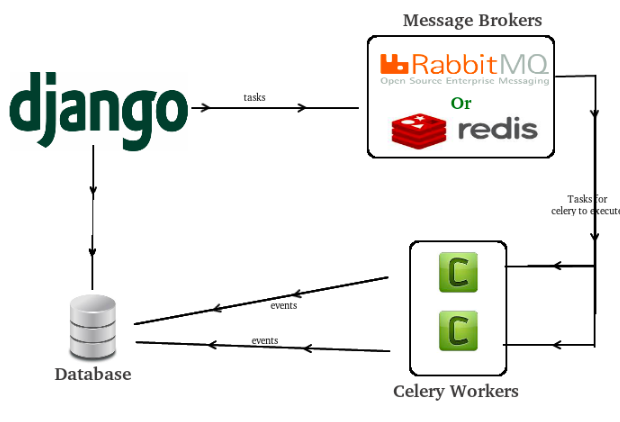
Celery 的任务调度
与 Linux Crontab 不同的是,Celery 在默认的情况下不会安排在特定时间执行某个任务。Celery 使用自己的 Celery Beat 来支持作业调度。那么当任务执行失败时怎么样呢?当特定任务失败时,可以将 Celery 设置为重试状态直到发生特定的异常,或者通过设置 max_retries 参数,在启用之前重试 N 次。
Idempodency
假设一下,当需要将 N 项数据备份至数据库中,如果需要两个职程来执行,那么就需要调用函数来确保在数据库中不会执行两次相同的条目,职程就不会感知到运行特定任务所带来的副作用。
Redis Queue
通常情况下,Redis 只是一个内存数据库。RQ(Redis queue)是一个执行异步任务的任务调度程序,通过使用 Redis 的队列数据结构,并通过内置的职程实现,其结构与工作原理与 Celery 大致相同。
RQ vs Celery
如果有一天你醒来后决定要重构你的队列系统,虽然 RQ 仍然是建立在 Redis 的基础上,但 Celery 支持了消息代理广泛排列功能;
Celery 支持子任务,RQ 不支持;
RQ 通过让开发者将特定任务配置为优先级的方式来实现优先级队列的处理。Celery 是通过将任务路由到不同的服务器上来实现;
RQ 只支持 Python,Celery 还支持其它语言;
Celery 支持任务计划与调度;
RQ 的开发者只能运行在能够实现 fork()的系统上。这意味着它无法在 Windows 系统下使用,当然如果你使用的是基于 Linux 的 Windows 子系统来运行这个 bash shell 的话,是完全可以的。
RabbitMQ
RabbitMQ 是一款基于 AMQP 协议构建的队列系统,与 Celery(只有职程)和 RQ(职程和队列都有)相比,RabbitMQ 只有一个队列系统,当然这个队列系统非常强壮。
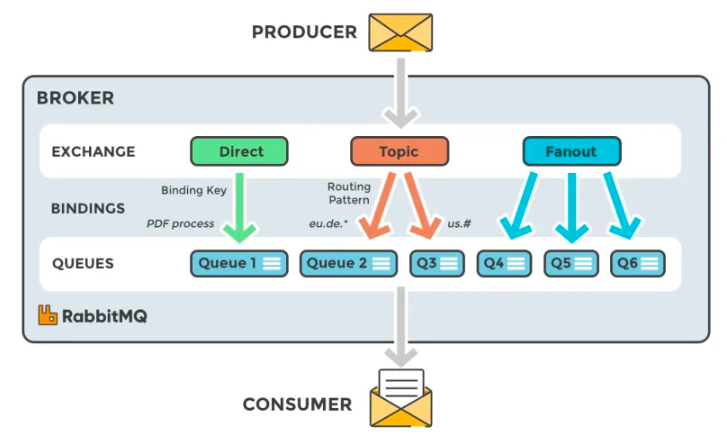
RabbitMQ 运行在订阅发布模型上,它由多部分组成,其中有 4 个最重要的部分,分别是 Producers、Exchangers、Queues 以及 Consumers。
Producers,一串将任务部署在队列中的代码;
Exchangers,决定这个消息应该进入到哪个队列中;
Direct,用各自的表向队列发送信息;
Topic,向队列发送与特定路由模式匹配的消息;
Fan-out,向所有队列发布消息;
Queues,队列为使用人员提供了任务列表;
Consumers,负责执行实际任务,任何时间都可以将职程配置在特定队列上。
RabbitMQ 没有独立的职程,依赖于 Celery 的任务职程。
RabbitMQ 虽然支持多个队列,但当与 Celery 一起使用时,创建一个队列、绑定相应的键值并与一个带有标签的 Celery 交换,就会隐藏 RabbitMQ 的所有高级配置。
并且,RabbitMQ 还具备优美的文档格式、支持多种语言、消息执行后可被确认等诸多优势。同样,也存在难以追踪和 debug、错误队列往往被存储在不同的队列中、不支持优先级等问题。
Google Task Queue - 谷歌任务队列
Google 的任务队列系统提供了两种队列机制类型:
Push Mode - 开发者主动将任务配置在队列中;
Pull Queue - 由代码自动化将任务退出队列并执行。
Google Pub/Sub
虽然谷歌的发布订阅在运作机制上十分接近异步执行,但是这两者主要关注的是消息队列和消息流。如果在 Facebook 的群组中发送消息或内容,每一位在该群组队列内的用户都会得到警告。这也是 Google Pub/Sub 的经典用法。
Pub/Sub 都是异步的,并且都能够正确无误的执行任务,那为什么我们不能直接用任务队列来实现 Pub/Sub 的模型发布呢?针对此问题,Google 为我们提供了一个很清晰的解释。
Google Cloud 的选择:Cloud Tasks 和 Cloud Pub/Sub
Cloud Tasks 和 Cloud Pub/Sub 都可以被用来实现消息订阅和异步集成。尽管他们两者的概念十分相似,但是他们都是为不同的用例所设计出来的。点击这个页面可以看到 Google Cloud 如何在 Cloud Tasks 和 Cloud Pub/Sub 之间进行选择。
核心区别
这两者的核心区别在于隐式调用和显示调用的概念。
Cloud Pub/Sub 的发布者无法控制消息的最终交付,除非保证交付。通过这种方式,Cloud Pub/Sub 支持隐式调用,发布者通过隐式发布事件来执行订阅服务器。相反,Cloud Tasks 则是显式调用,其中发布者保留对执行的完全控制。值得注意的是,发布者可以指定每个消息所发送的端点。总之,云任务适用于任务生成器延迟控制特定的 webhook 或远程调用用例的情况。Cloud Pub/Sub(云发布/订阅)更加适用于数据摄取和分布模式的情况,通过牺牲对执行的控制来实现效果的保证。
参考文档 & 博客推荐:
原文链接:
https://bhavaniravi.com/blog/asynchronous-task-execution-in-python

策划编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论