

2018 年 6 月 22 号发布《秒 X 平台-助力实时分析》(秒 X 平台现已命名为 FAST 天眼-贝壳服务监控平台)文章中,系统的架构就有提到关于 ElasticSearch(简称 ES)查询引擎,FAST 系统检索功能和报警功能都依赖对全量日志的存储和检索,在存储系统中进行查询,用于分析和报警,对详情数据的实时存储和查询都有很高的要求。为了满足业务要求和提供系统稳定和高效的能力,调研过程中考虑了 solr 和 ES,而分析 solr 的实时性不是很好之后,就重点针对 ES 进行调研。都说 ES 实时性好,延迟低,容错性高,易扩展,查询速度快,但是为什么查询会快呢?
当然离不开 ES 的特点,ES 是基于 Lucene 非常成熟的索引架构,加入了集群、sharding,replication 等分布式实现,而且 Elastic Stack 生态圈比较完善,如 ELK、Beats 、Elastic Cloud、Swiftype、ES-Hadoop 等,能支持聚合。
在 ES 中要清楚几个名词,shard、segment、analyzer、term、index、type、mapping、document、id 等。
1)Shard 是一个最小的 Lucene 索引单元,是 Lucene 的一个实例。分散在不同的 Node 上,但不会存在两个相同的 Shard 存在一个 Node 上;
2)segment 是 Lucene 中的倒排索引,是通过词典(Term Dictionary)到文档列表(Postings List)的映射关系,设计的时候考虑到空间 size 的问题,为词典做了一层前缀索引(Term Index),Lucene 4.0 以后采用的数据结构是 FST(Finite State
Transducer);
3)Analyzer 对文档的内容进行分词处理;
4)Term 是搜索的基本单位;
5)index 是索引;
6)type 是索引类型;
7)mapping 是映射关系,定义了 index 中的 type,properties 中定义了字段名、字段类型的信息,mapping 不能修改字段类型;
8)document 是用来描述文档的,是由多个 Field 对象组成的;
9)id 是文档的标识。
这儿介绍 index、type、mapping、document 的时候没有与关系型数据库类比,在 Elasticsearch 6.0.0 或更高版本中创建的索引可能只包含一个映射类型。在 5.x 中使用多种映射类型创建的索引将继续像以前一样在 Elasticsearch 6.x 中运行。映射类型将在 Elasticsearch 7.0.0 中完全删除。因为“类型”与“表”相当,导致错误的假设,因为 SQL 表彼此独立,一个表中的列与另一个表中的相同名称的列没有关系。而映射类型中的字段不是这种情况,在相同索引中存储具有很少或没有共同字段的不同实体,会导致数据稀疏,并干扰 Lucene 有效压缩文档的能力。所以官网以后计划发布的版本和这个类比没有很强依赖的关系。
为了更深入地理解 ES 的工作原理,将对 Lucene 的一些底层技术和细节进行讲解。使用过的很多人都知道如何进行索引和查询数据,但大多数人对底层技术细节不是很清楚,对调优性能不了解。例如文件是如何分布到集群的?又是如何从集群中获取的? 搜索如何保证近实时的? 如何对文档的 CRUD 操作是实时的?如何保证断电时也不丢数?数据是如何被存储到分布式文件系统中的,存储文件类型和格式是什么样的?以下内容将对这些问题进行探寻原理。
1 分布式文档存储
文件是如何被分布存储到集群的,又是如何从集群中获取的呢?
1.1 路由一个文档到一个分片中
公式:
根据公式创建文档的时候确定一个文档存放在哪个一个分片中。routing 是一个可变值,默认是文档的_id,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards(主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards - 1 之间的余数,就是我们所寻求的文档所在分片的位置。
1.2 主分片和副分片的交互
以官网的例子进行分析,从图中能看出一个集群由三个节点组成,有两个分片,两个副本。
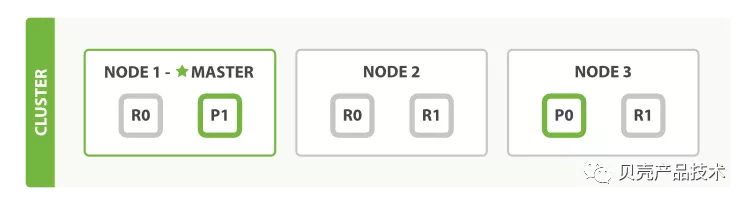
上图中集群中的任意一个节点有能力处理任意的请求,每个节点都知道集群中任意一个文档所处的位置。
1.3 写一个文档操作
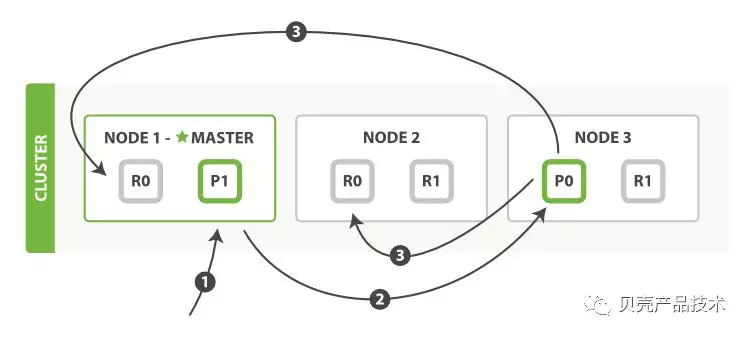
上图中写操作必须在主分片上面完成之后,才能被复制到其他节点作为分片副本,新建、索引和删除请求都是写操作。
1)客户端向 master 发送写入请求,该节点作为协调节点;
2)根据文档的_id 确定分片,图中请求文档属于分片 0,协调节点请求转到节点的主分片;
3)在节点 3 上执行请求,成功之后,节点 3 根据副本数将请求并行转到副本分片对应节点,一旦副本分片执行完成,都向节点 3 报告成功,节点 3 将向协调节点报告成功,协调节点再向客户端报告成功。
客户端收到成功响应时,则变更操作是安全的。这个过程中有些请求参数影响效率。
1.4 取回一个文档
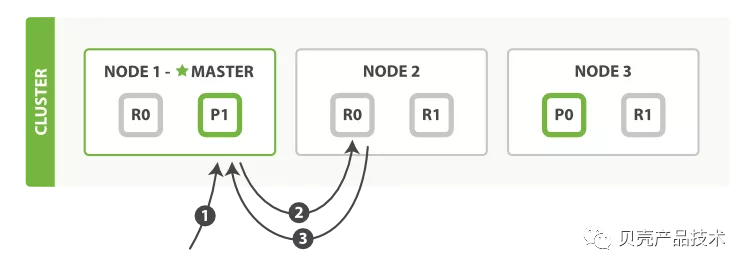
1)客户端向 master 发送获取请求,该节点作为协调节点;
2)根据文档的_id 确定分片,图中请求文档属于分片 0,分片 0 的主副分片都在三个节点上,这儿将请求转到节点 2;
3)节点 2 将文档返回给节点 1,然后将文档返回给客户端。
在文档被检索时,已经被索引的文档可能已经存在于主分片上,但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
1.5 局部更新文档
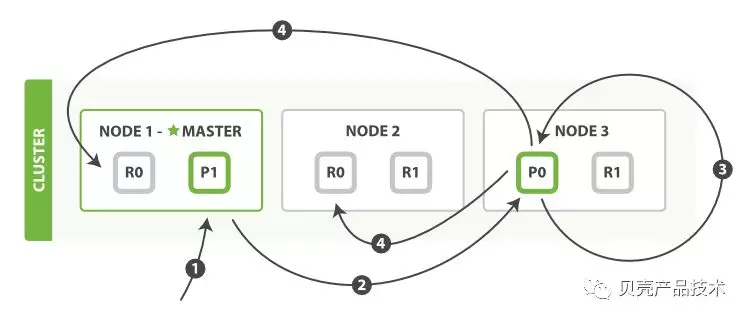
1)客户端向 master 发送更新请求,该节点作为协调节点;
2)根据文档的_id 确定分片,图中请求文档属于分片 0,协调节点将请求转到节点 3;
3)节点 3 从主分片检索文档,修改 _source 字段中的 JSON ,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤 3,超过 retry_on_conflict 次后放弃;
4)如果节点 3 成功地更新文档,它将新版本的文档并行转发到其他节点上的副本分片,重新建立索引。一旦所有副本分片都返回成功,节点 3 向协调节点也返回成功,协调节点向客户端返回成功。
1.6 多文档模式
mget 和 bulk API 的模式类似于单文档模式。区别在于协调节点知道每个文档存在于哪个分片中。 它将整个多文档请求分解成 每个分片 的多文档请求,并且将这些请求并行转发到每个参与节点。协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端。
2 使用 mget 取回多个文档
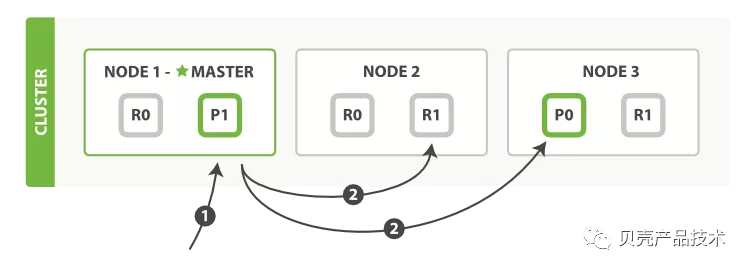
1)客户端向 master 发送 mget 请求,该节点作为协调节点;
2)节点 1 为每个分片构建多文档获取请求,然后并行转发这些请求到托管在每个所需的主分片或者副本分片的节点上。一旦收到所有答复,节点 1 构建响应并将其返回给客户端。
3 使用 bulk 修改多个文档
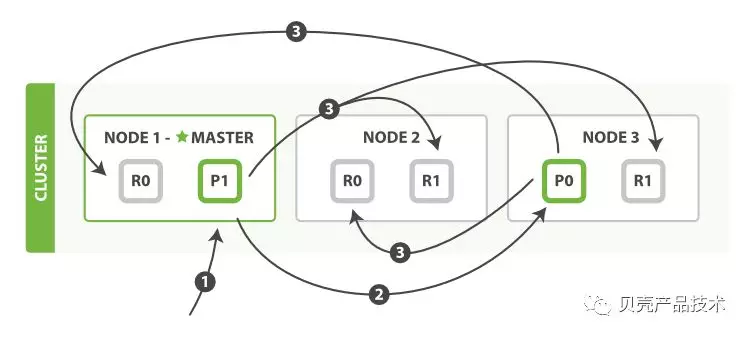
1)客户端向 master 发送 bluk 请求,该节点作为协调节点;
2)节点 1 为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机;
3)主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端。
4 分片内部原理
分片,可以把他当成 ES 中最小的工作单元,它是如何保证近实时的?为何对文档的 CRUD 操作是实时的?是如何保证断电时也不丢数的?
4.1 倒排索引
如何让文本可以被搜索的,Lucene 是一个高性能的 java 全文检索工具包,最好的支持一个字段多个值需求的数据结构,它使用的是倒排文件索引结构。如果对倒排索引不熟悉,关系型数据库的索引应该会有了解,在关系型数据库中,索引是检索数据最有效率的方式,采用的是 B+树来查询的,但是对于搜索引擎,并不能满足其特征要求。倒排索引的数据结构到底是怎么样的呢?一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。它会保存每一个词项出现过的文档总数,在对应的文档中一个具体词项出现的总次数,词项在文档中的顺序,每个文档的长度,所有文档的平均长度,等等。这些统计信息允许 ES 决定哪些词比其它词更重要,哪些文档比其它文档更重要。而不需要索引的 field 是可以设置为不被倒排索引的。
为了能够实现文档可以被搜索功能,倒排索引需要知道集合中的所有文档的位置,这是需要意识到的关键问题。早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。
4.2 不变性
倒排索引被写入磁盘后是不可改变的(它永远不会修改)。如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。但不变性有重要的价值:不需要锁,无并发问题;提升性能,一旦索引被读入内核的文件系统缓存,只要有足够的空间,大部分请求直接请求内存,不会命中磁盘;写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和需要被缓存到内存的索引的使用量。
ES 中的数据可以概括为两类:精确值和全文。精确值有大小之分,检索中很少对全文类型的域做精确匹配。相反,在文本类型的域中搜索。不仅判断文档和给定查询条件的相关性,还希望搜索能够理解检索的意图 :搜索 ES 会返回包含 Elastic Search 的文档;搜索 head,会匹配 heap,heads 相关。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论