

本文讲述了 5 个提高性能的方法,从使用更好的算法到多处理。
如何加速 Python 代码?
1. 优化代码和算法
一定要先好好看看你的代码和算法。许多速度问题可以通过实现更好的算法或添加缓存来解决。本文所述都是关于这一主题的,但要遵循的一些一般指导方针是:
测量,不要猜测。 测量代码中哪些部分运行时间最长,先把重点放在那些部分上。
实现缓存。 如果你从磁盘、网络和数据库执行多次重复的查找,这可能是一个很大的优化之处。
重用对象,而不是在每次迭代中创建一个新对象。Python 必须清理你创建的每个对象才能释放内存,这就是所谓的“垃圾回收”。许多未使用对象的垃圾回收会大大降低软件速度。
尽可能减少代码中的迭代次数,特别是减少迭代中的操作次数。
避免(深度)递归。 对于 Python 解释器来说,它需要大量的内存和维护(Housekeeping)。改用生成器和迭代之类的工具。
减少内存使用。 一般来说,尽量减少内存的使用。例如,对一个巨大的文件进行逐行解析,而不是先将其加载到内存中。
不要这样做。 听起来很傻是吧?但是你真的需要执行这个操作吗?不能晚点儿再执行吗?或者可以只执行一次,并且它的结果可以存储起来,而不是一遍又一遍地反复计算?
2. 使用 PyPy
你可能正在使用 Python 的参考实现 CPython。之所以称为 CPython,是因为它是用 C 语言编写的。如果你确定你的代码是 CPU 密集型(CPU bound)(如果你不知道这一术语,请参见本文“使用线程”一节)的话,那么你应该研究一下 PyPy,它是 CPython 的替代方案。这可能是一种快速解决方案,无需更改任何一行代码。
PyPy 声称,它的平均速度比 CPython 要快 4.4 倍。它是通过使用一种称为 Just-in-time(JIT,即时编译)技术来实现的。Java 和 .NET 框架就是 JIT 编译的其他著名的例子。相比之下,CPython 使用解释来执行代码。虽然这一做法提供了很大的灵活性,但速度也变得慢了下来。
使用 JIT,你的代码是在运行程序时即时编译的。它结合了 Ahead-of-time(AOT,提前编译)技术的速度优势(由 C 和 C++ 等语言使用)和解释的灵活性。另一个优点是 JIT 编译器可以在运行时不断优化代码。代码运行的时间越长,它就会变得越优化。
PyPy 在过去几年中取得了长足的进步,通常情况下,它可以作为 Python 2 和 Python 3 的简易替换方案。使用 Pipenv 这样的工具,它也可以完美地工作,试试看吧!
3.使用线程
大部分软件都是 IO 密集型,而不是 CPU 密集型。如果你对这些术语还不熟悉的话,请看看下面的解释:
IO 密集型(I/O bound):软件主要是等待输入 / 输出操作完成才能工作。在从网络或缓慢的存储中获取数据时,通常会出现这种情况。
CPU 密集型(CPU bound):软件占用了大量的 CPU 资源。它使用了 CPU 所有的能力来产生所需的结果。
在等待来自网络或磁盘的应答时,你可以使用多个线程使其他部分保持运行状态。
一个线程是一个独立的执行序列。默认情况下,Python 程序有一个主线程。但你可以创建更多的主线程,并让 Python 在它们之间切换。这种切换发生得如此之快,以至于它们看上去就好像是在同时并排运行一样。
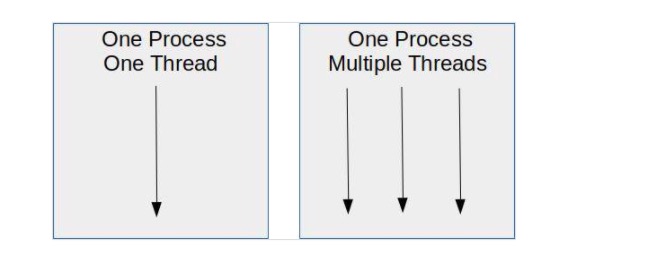
线程是独立的执行序列,共享相同的内存空间
但与其他编程语言不同的是,Python 并不是同时运行的,而是轮流运行。这是因为 Python 中有一种全局解释器锁( Global Interpreter Lock,GIL)机制。这一点,以及 threading 库在我撰写的关于 Python 并发性的文章有详细的解释。
我们得到的结论是,线程对于 IO 密集型的软件有很大的影响,但对 CPU 密集型的软件毫无用处。
这是为什么呢?很简单。当一个线程在等待来自网络的答复时,其他线程可以继续运行。如果你要执行大量的网络请求,线程可以带来巨大的差异。如果你的线程正在进行繁重的计算,那么它们只是等待轮到它们继续计算,线程化只会带来更多的开销。
4. 使用 Asyncio
Asyncio 是 Python 中一个相对较新的核心库。它解决了与线程相同的问题:它加快了 IO 密集型软件的速度,但这是以不同的方式实现的。我将立即坦承我并非 Python 的 asyncio 拥趸。它相当复杂,特别是对于初学者来说。我遇到的另一个问题是,asyncio库在过去几年中有了很大的发展。网上的教程和示例代码常常已经过时。不过,这并不意味着它就毫无用处。如果你有兴趣的话,Real Python 网站有一个不错的 asyncio 指南。
5 同时使用多个处理器
如果你的软件是 CPU 密集型的,你通常可以用一种可以同时使用更多处理器的方式重写你的代码。通过这种方式,你就可以线性地调整执行速度。
这就是所谓的并行性,但并不是所有的算法都可以并行运行。例如,简单的将递归算法进行并行化是不可能的。但是几乎总有一种替代算法可以很好地并行工作。
使用更多处理处理器有两种方式:
在同一台机器内使用多个处理器和 / 或内核。在 Python 中,这可以通过
multiprocessing库来完成。使用计算机网络来使用多个处理器,分布在多台计算机上。我们称之为分布式计算。
这篇关于 Python 并发性的文章侧重于介绍如何在一台机器的范围内扩展 Python 软件的方法。它还介绍了multiprocessing 库。如果你认为这是你需要的资料,一定要去看看。
与 threading 库不同, multiprocessing 库绕过了 Python 的全局解释器锁。它实际上是通过派生多个 Python 实例来实现这一点的。因此,现在你可以让多个 Python 进程同时运行你的代码,而不是在单个 Python 进程中轮流运行线程。
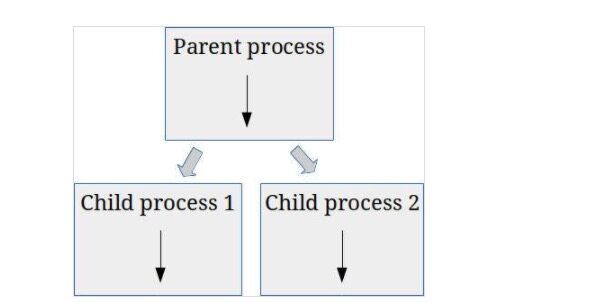
多处理的可视化
multiprocessing 库和 threading 库非常相似。可能出现的问题是:为什么还要考虑线程呢?答案是可以猜得到的。线程是“轻量”的:它需要更少的内存,因为它只需要一个正在运行的 Python 解释器。产生新进程也还有其开销。因此,如果你的代码是 IO 密集型的,线程可能就足够好了。
一旦你实现了软件的并行工作,那么在使用 Hadoop 之类的分布式计算方面就前进了一小步。通过利用云计算平台,你可以相对轻松地进行扩展规模。例如,你可以在云端中处理大型数据集,并在本地使用结果。使用混合操作的方式,你可以节省一些资金,因为云端中的算力非常昂贵。
总结
总结起来就是:
首先考虑优化你的算法和代码。
如果原始速度可以解决你的问题,请考虑使用 PyPy。
对 IO 密集型软件使用
threading库和asyncio。使用
multiprocessing库解决 CPU 密集型问题。如果所有这些措施还不够的话,可以利用 Hadoop 等云计算平台进行扩展规模。
作者介绍:
Erik-Jan van Baaren,作家、软件 / 数据工程师。
延伸阅读:
https://towardsdatascience.com/how-to-speed-up-your-python-code-d31927691012

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论