
在这篇文章中,我将逐步讲解如何使用 TensorFlow 创建一个简单的机器学习模型。
TensorFlow 是一个由谷歌开发的库,并在 2015 年开源,它能使构建和训练机器学习模型变得简单。
我们接下来要建立的模型将能够自动将公里转换为英里,在本例中,我们将创建一个能够学习如何进行这种转换的模型。我们将向这个模型提供一个CSV文件作为输入,其中有 29 组已经执行过的公里和英里之间的转换,基于这些数据,我们的模型将学会自动进行这种转换。
我们将使用有监督学习算法,因为我们知道数据的输入和输出结果。并使用 Python 作为编程语言。Python 提供了一系列与机器学习相关的方便的库和工具。本例中所有的步骤都是使用Google Colab执行的。Google Colab 允许我们在浏览器上零配置地编写和执行 Python 代码。
导入必需的库
我们首先导入在我们的例子中将要使用到的库。
import tensorflow as tfimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt我们将导入 TensorFlow 来创建我们的机器学习模型。
我们还将导入 Pandas 库来读取包含有公里和英里转换数据的 CSV 文件。
最后,我们将导入 Seaborn 和 Matlotlib 库绘制不同的结果。
加载样例数据
我们将含有逗号分隔的值的文件(Kilometres-miles.csv)读取到我们的数据帧中。这个文件包含一系列公里和英里值的转换。我们将使用这些数据帧来训练我们的模型。你可以在这个链接下载这个文件。
要从 Google Colab 读取文件,你可以使用不同的方法。在本例中,我直接将 CSV 文件上传到我的 Google Colab 上的 sample_data 文件夹中,但你可以从一个 URL 中读取文件(比如,从 GitHub)。
上传到 Google Colab 的问题是,数据会在运行时重启时丢失。
数据帧是二维的大小可变的并且各种各样的表格数据。
df = pd.read_csv('/content/sample_data/Kilometres-miles.csv')df.info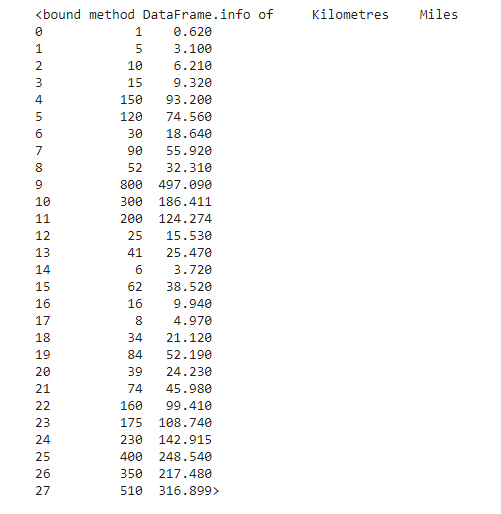
绘制数据帧
我们将“searborn”库的“scatterplot”导入并命名为“sns”,然后使用这个库来绘制上述图形。它显示了 X(公里)和 Y(英里)对应关系的图形化表示。
print("Painting the correlations")#Once we load seaborn into the session, everytime a matplotlib plot is executed, seaborn's default customizations are addedsns.scatterplot(df['Kilometres'], df['Miles'])plt.show()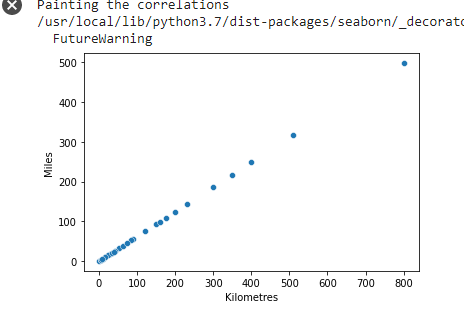
我们定义数据帧的输入和输出来训练模型:
X(公里)是输入,Y(英里)是输出。
print("Define input(X) and output(Y) variables")X_train=df['Kilometres']y_train=df['Miles']输入和输出变量
创建神经网络
现在,让我们使用“keras.Sequential”方法来创建一个神经网络,其中依次添加“layers”。每一个层(layer)都具有逐步提取输入数据以获得所需输出的功能。Keras 是一个用 Python 写的库,我们创建神经网络并使用不同的机器学习框架,例如 TensorFlow。
接下来,我们将使用“add”方法向模型添加一个层。
print("Creating the model")model = tf.keras.Sequential()model.add(tf.keras.layers.Dense(units=1,input_shape=[1]))创建神经网络
编译模型
在训练我们的模型之前,我们将在编译步骤中添加一些额外设置。
我们将设置一个优化器和损失函数,它们会测量我们的模型的准确性。Adam 优化是一种基于第一次和第二次矩的自适应预算的随机梯度下降算法。
为此,我们将使用基于平均方差的损失函数,它测量了我们预测的平均方差。
我们的模型的目标是最小化这个函数。
print("Compiling the model")model.compile(optimizer=tf.keras.optimizers.Adam(1), loss='mean_squared_error')编译模型
训练模型
我们将使用“拟合(fit)”方法来训练我们的模型。首先,我们传入独立变量或输入变量(X-Kilometers)和目标变量(Y-Miles)。
另一方面,我们预测 epoch 的数值。在本例中,epoch 值是 250。一个 epoch 就是遍历一遍所提供的完整的 X 和 Y 数据。
如果 epoch 的数值越小,误差就会越大;反过来,epoch 的数值越大,则误差就会越小。
如果 epoch 的数值越大,算法的执行速度就会越慢。
print ("Training the model")epochs_hist = model.fit(X_train, y_train, epochs = 250)
评估模型
现在,我们评估创建的模型,在该模型中,我们可以观察到损失(Training_loss)随着执行的遍历次数(epoch)的增多而减少,如果训练集数据有意义并且是一个足够大的组,这是合乎逻辑的。
print("Evaluating the model")print(epochs_hist.history.keys())#graphplt.plot(epochs_hist.history['loss'])plt.title('Evolution of the error associated with the model')plt.xlabel('Epoch')plt.ylabel('Training Loss')plt.legend('Training Loss')plt.show()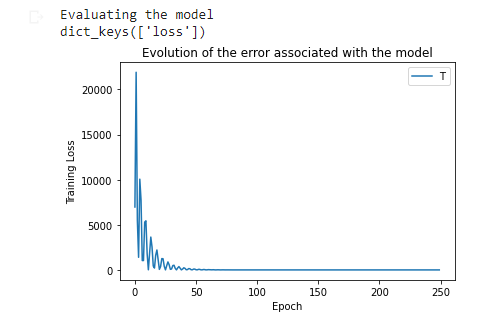
从图中我们可以看出,用 250 次训练模型并没有多大帮助,在第 50 次遍历后,误差并没有减少。因此,训练该算法的最佳遍历数大约是 50。
进行预测
现在我们已经训练了我们的模型,我们可以使用它来进行预测。
在本例中,我们将 100 赋值给模型的输入变量,然后模型会返回预测的英里数:
kilometers = 100predictedMiles = model.predict([kilometers])print("The conversion from Kilometres to Miles is as follows: " + str(predictedMiles))从公里到英里的换算为 62.133785.
检查结果
milesByFormula = kilometers * 0.6214print("The conversion from kilometers to miles using the mathematical formula is as follows:" + str(milesByFormula))diference = milesByFormula - predictedMilesprint("Prediction error:" + str(diference))使用公式从公里到英里的换算值为:62.13999999999999。预测误差为 0.00621414
总结
通过本例,我们了解了如何使用 TensorFlow 库来创建一个模型,这个模型已经学会自动将公里数转换为英里数,并且误差很小。
TensorFlow 用于执行此过程的数学非常简单。基本上,本例使用线性回归来创建模型,因为输入变量(公里数)和输出变量(英里数)是线性相关的。在机器学习中,过程中最耗时的部分通常是准备数据。
随着时间的推移,我们收获了一些经验,这些经验可以帮助我们选择最适合的算法及其设置,但一般来说,这是一项分析测试并改进的任务。
作者介绍
Kesk -*- ,软件工程师,软件爱好者,科幻作家。
原文链接




