

“大模型的 Scaling Law 并未失效,AI 技术的增长进入了一个全新的阶段。也就是说大模型技术的创新依旧是突飞猛进的进行时,甚至还有速度越来越快的迹象。”智谱 AI CEO 张鹏在 6 月 5 日的 Open Day 上说道。
飞速变化的不只是技术,还有价格。继 5 月宣布入门级产品 GLM-3 Turbo 模型调用价格从 5 元/百万 Tokens 降至 1 元/百万 Tokens 后,智谱 AI 再次宣布模型全面降价。
MaaS 2.0 发布:全面降价
“我们切切实实通过模型核心技术的迭代和效率的提升,通过技术的创新来实现了应用成本的持续降低以及客户价值的持续升级,并不是简单的价格战。”张鹏说道。
根据介绍,智谱 AI 的 MaaS 开放平台的日均调用量已经超过了 400 亿的 tokens,API 每日消费量在过去 6 个月增长了 50 倍以上。这次,智谱 AI 宣布推出 MaaS 2.0 的同时,还采取了一系列降价措施。
首先,GLM-4-flash 版本的价格降到了 GLM-3 Turbo 的 1/10,“现在仅仅需要 1 毛钱我们可以拥有 100 万 token,100 万 token 够写两本四大名著,像《红楼梦》写两遍也只需要 1 毛钱。”智谱 AI COO 张帆说道。
那如何让智谱 AI 最受欢迎的 GLM-4 也更加便宜呢?智谱 AI 为此发布了 GLM-4 Air 版本,性能非常接近原来的 GLM-4,但是价格进一步降低,达到 1 元/100 万 token。“我们只用了 1%的价格,性能可以比肩原来的 GLM-4。”
对于企业在使用大模型时对于速度的需求,智谱 AI 在之前基础上推出了极速版,可以在效果不变的情况下将推理速度增加 162%,相当于 71 个 token/秒,就意味着每秒钟可以展示出 100 多个汉字。
GLM-4 进一步的升级,全新推出了 GLM-4-520 版本,相对 GLM-4,该版本综合能力提升 11.9%,指令遵从能力提升 18.6%。“看起来这个数字不是很大,但真正做过模型应用的同学一定能够感觉到,这一点点的提升相当于进一步提升了我们模型的天花板,能够极大扩展应用范围,降低应用成本。”
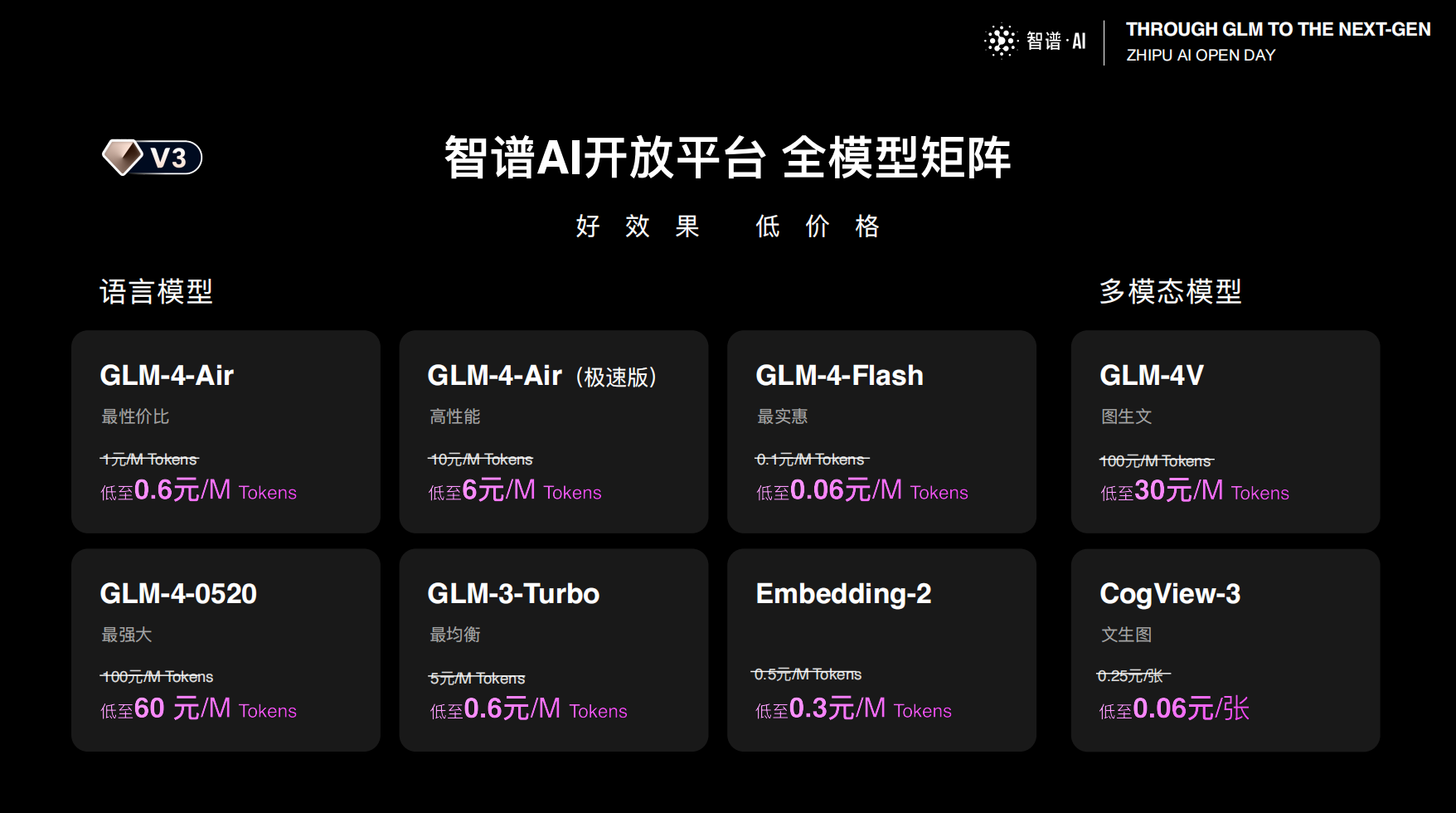
此外,智谱 AI 对其他模型也进行了全面降价:GLM-3-Turbo 降价 80%,GLM-4V 降价 50%,Cogview-3 降幅接近 60%、一毛钱一张图片。

针对企业用户,智谱 AI 还支持根据使用规模快速为调整价格和并发,并推出从 V0、V1、V2、V3 四个版本,每个版本享受不同的优惠。

可以看下,"尊贵 V3"可以拿到什么样的价格:
为支持企业私有部署,智谱 AI 升级了平台:⽆需代码,三步完成微调,⽀持 GLM-4 全系列模型:
第一步,准备训练数据,按照模版收集并准备数据,然后将其导入数据集中以训练数据;
第二步,创建微调任务,使用平台微调工具,训练专属行业大模型;
第三部,部署微调模型,LoRA 微调模型可以直接调用,全参微调模型需将训练好的模型部署到私有云服务器。
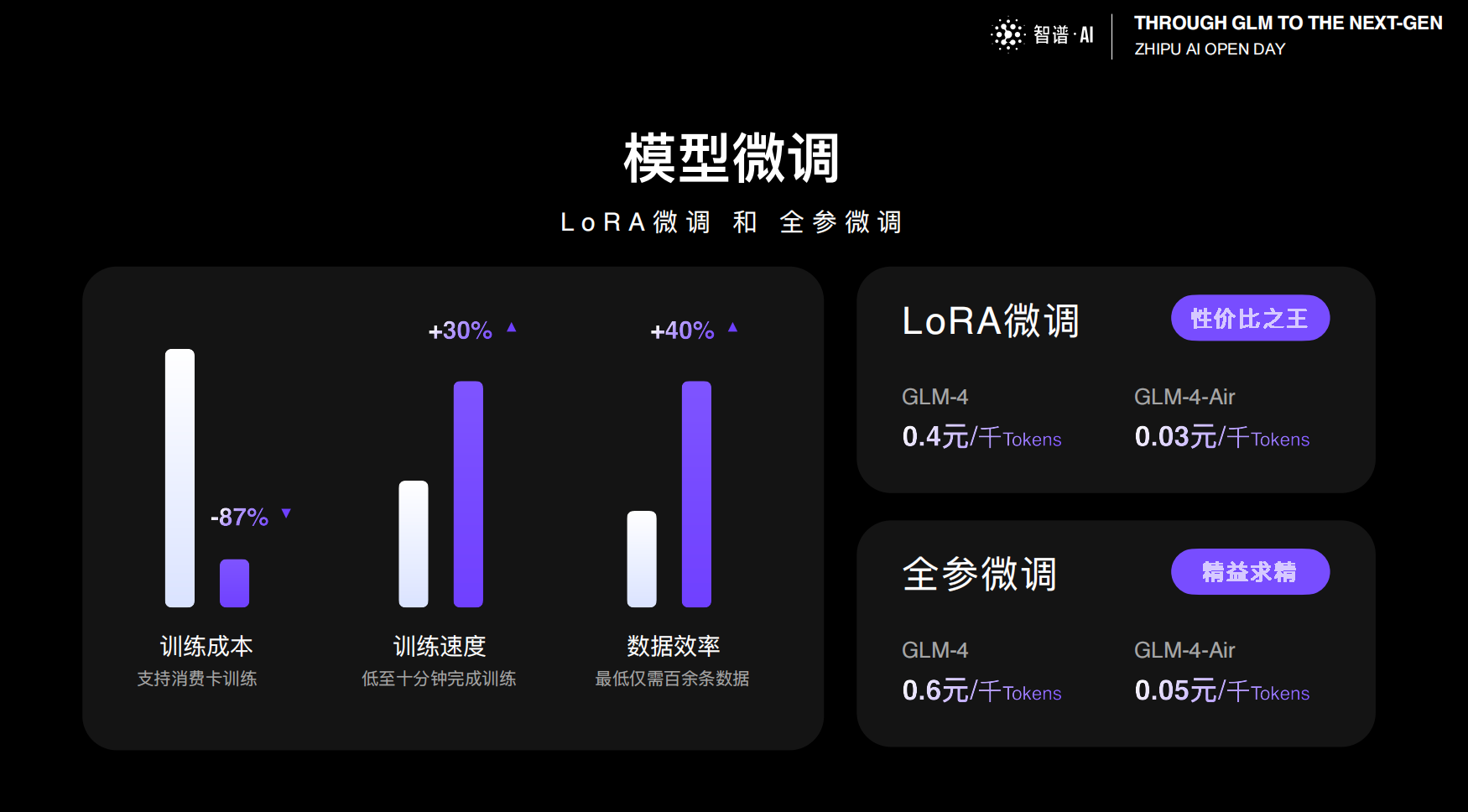
张帆介绍,LoRA 微调用更低的成本达到一个相对较好的结果,而全参微调相当于探索模型微调的极限。在此之上,智谱 AI 通过技术能力将训练成本最低降低 87%,训练速度提升 30%,数据利用效率提升 40%。而 Lora 微调是性价比之王,对于 GLM-4,每千 token 只需要 4 毛钱,而 GLM-4-Air 只需要 3 分钱。即使全参微调,GLM-4 需要 6 毛钱,GLM-4-Air 需要 5 分钱。
首次发布开源多模态模型
围绕着这方面,智谱 AI 发布了第四代 GLM 系列开源模型:GLM-4-9B。
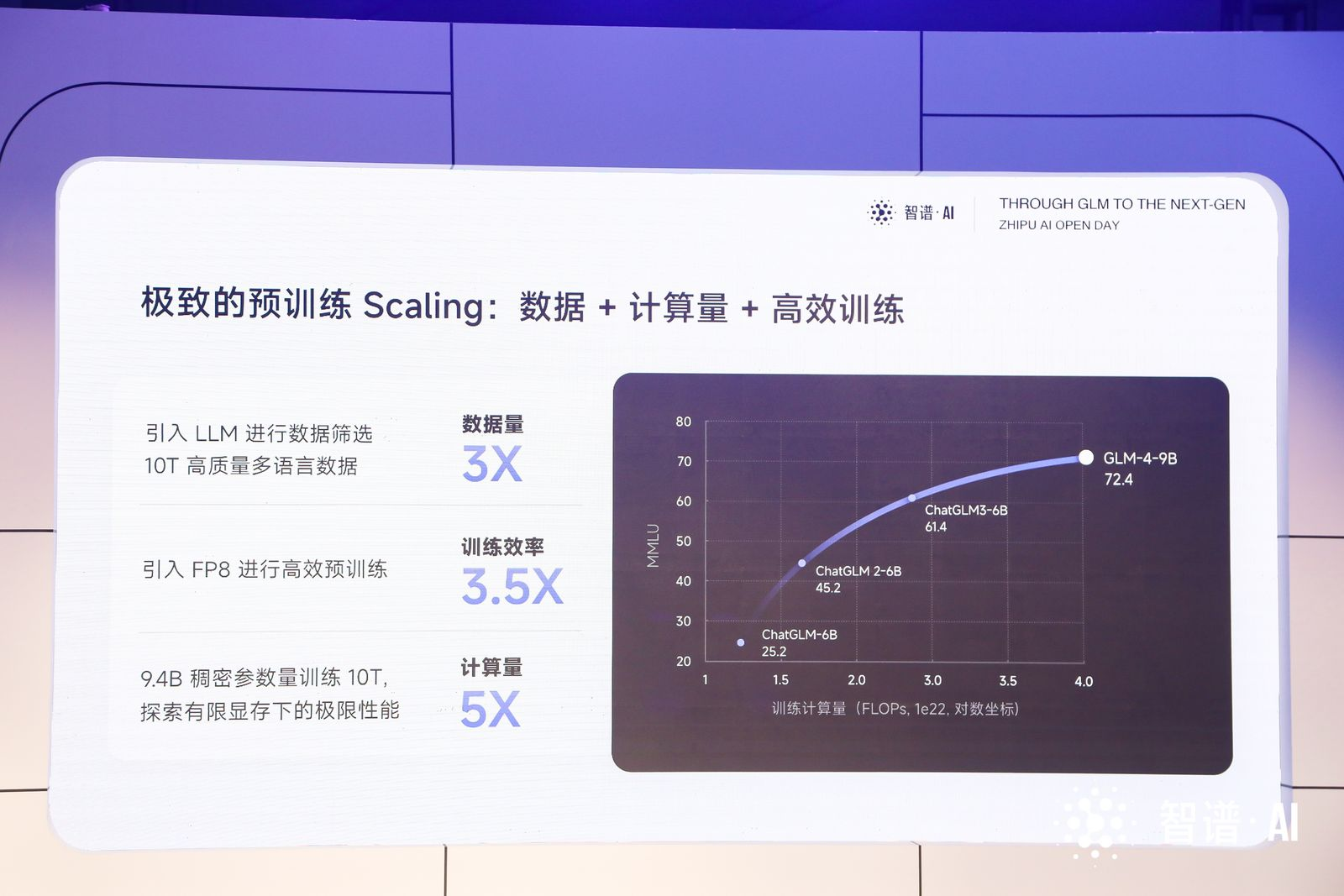
GLM-4-9B 的出现是源于团队在预训练时引入了大语言模型进入数据筛选流程,最终获得了 10T 高质量多语言数据,数据量是 ChatGLM3-6B 模型的 3 倍以上。同时采用 FP8 技术进行高效的预训练,相较于第三代模型,训练效率提高了 3.5 倍。在有限显存的情况下,团队发现 6B 模型性能有限,因此在考虑到大多数用户的显存大小后,将模型规模提升至 9B,并将预训练计算量增加了 5 倍。
根据介绍,GLM-4-9B 模型具备了更强大的推理性能、更长的上下文处理能力、多语言、多模态和 All Tools 等突出能力。
GLM-4-9B 中英文综合性能相比 ChatGLM3-6B 提升 40%,尤其是在中文对齐能力 AlignBench,指令遵从 IFeval,工程代码 Natural Code Bench 方面显著提升。对比训练量更多的 Llama 3 8B 模型,英文方面有小幅领先,中文学科方面更是有着高达 50% 的提升。
GLM-4-9B 的上下文从 128K 扩展到了 1M tokens,这意味着模型能同时处理 200 万字的输入,大概相当于 2 本红楼梦或者 125 篇论文的长度。同时,该模型支持 26 种语言。为了提升性能,团队将 tokenizer 的词表大小从 65k 扩充到了 150k,这一改进使得编码效率提高了 30%。
另外,团队在 GLM-4-9B 开源仓库中提供了一个完整的 All Tools Demo,用户可以在本地拥有一个轻量级的清言平替。

在强化文本能力的同时,智谱 AI 首次推出了基于 GLM 基座的开源多模态模型 GLM-4V-9B。这一模型采用了与 CogVLM2 相似的架构设计,能够处理高达 1120 x 1120 分辨率的输入,并通过降采样技术有效减少了 token 的开销。
为了减小部署与计算开销,GLM-4V-9B 没有引入额外的视觉专家模块,采用了直接混合文本和图片数据的方式进行训练,在保持文本性能的同时提升多模态能力。
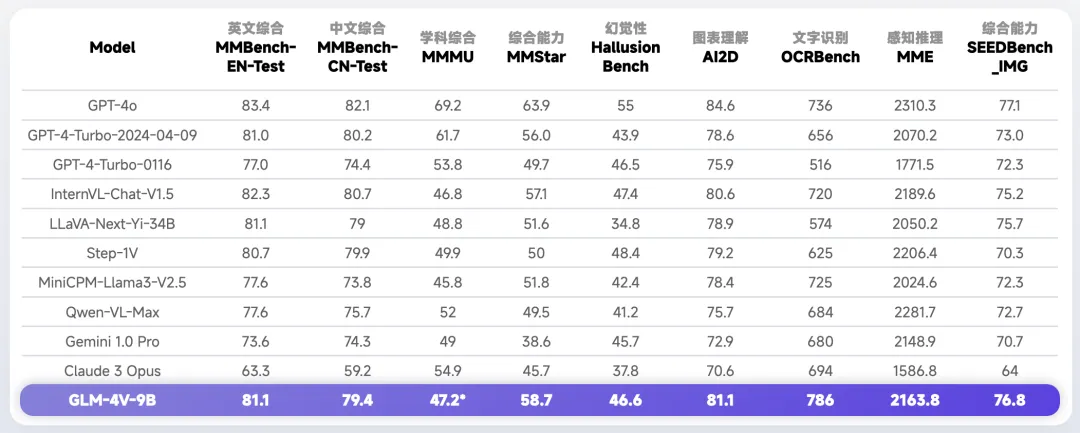
在性能方面,GLM-4V-9B 模型展现了显著的优势。尽管其参数量仅为 13B,但超越了许多参数量更大的开源模型。在众多任务中,GLM-4V-9B 的性能与 GPT-4V 不相上下。
Github:
https://github.com/THUDM/GLM-4
huggingface:
https://huggingface.co/collections/THUDM/glm-4-665fcf188c414b03c2f7e3b7
魔搭社区:
https://modelscope.cn/organization/ZhipuAI
刘慈欣、老罗,线上“整活儿”
除了正式的发布,智谱 AI 团队还邀请了刘慈欣和老罗来帮忙“整活儿”。
刘慈欣在线上分享他对 AGI 与科幻创作的思考。他表示,关于人类的想象力是否会被人工智能所限制,还是被它所激发和促进,这个问题涉及到各个维度和复杂的交互作用。
人工智能可能在以下两方面限制人类的想象力:依赖性和惰性 。AI 的快速响应和准确性可能会让人类变得更有惰性,不再愿意投入时间的精力去深入探索和创新。
人工智能也可能激发促进人的想象力。首先,AI 可以处理分析大量数据,对人类进行前所未有的信息和知识,这些信息作为灵感来源可以激发人类的想象力和创造能力。同时 AI 的运算能力和分析能力可以突破人类思维的局限性,提出全新的观点和问题。
综合来看,人工智能对人类想象力的影响是双面的,关键在于人类如何正确地使用和管理 AI 技术。
“在 AI 时代,决定人生起点的不再只有依靠记忆性获得的知识,还有我们的想象力,以及我们对于今天技术革命的认知度,我们需要更加注重想象力和创新力的培养。”刘慈欣说道,“我想在未来,当人工智能拥有超过人类的智力时,想象力也许是我们对于 AI 所拥有的唯一优势。”
而罗永浩 AI 智能体——AI 老罗,正式入驻智谱清言 App 智能体中心,工号 001,向全社会开放。

有趣的是,昨晚罗永浩直播的时候还被人怀疑不是真人是 AI,老罗听到后霸气回应“是什么就是什么,AI 就要标明是 AI”来否认。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论