
随着生成式 AI 技术的以惊人的速度迅猛发展,AI 已逐渐渗透到大家日常工作或生活中的各个领域。作为一名互联网程序员,除了会使用 AI 技术提效外,更是得“折腾折腾”,学习下 AI 背后的技术原理。
在去年 11 月,由 Anthropic 团队提出的 MCP(Model Context Protocol)相信大家肯定不陌生,MCP 如同 USB-C 接口般通过统一协议实现 LLM 与外部能力的高效互联。对 MCP 的概念在此就不过多介绍了,搜索引擎随便一搜就有大把 MCP 科普文章。而本文想讲点不一样的干货:
MCP 如何让大模型与外部系统互联的?
如何实现 MCP Server?
MCP Gateway 实践
MCP 代码原理剖析
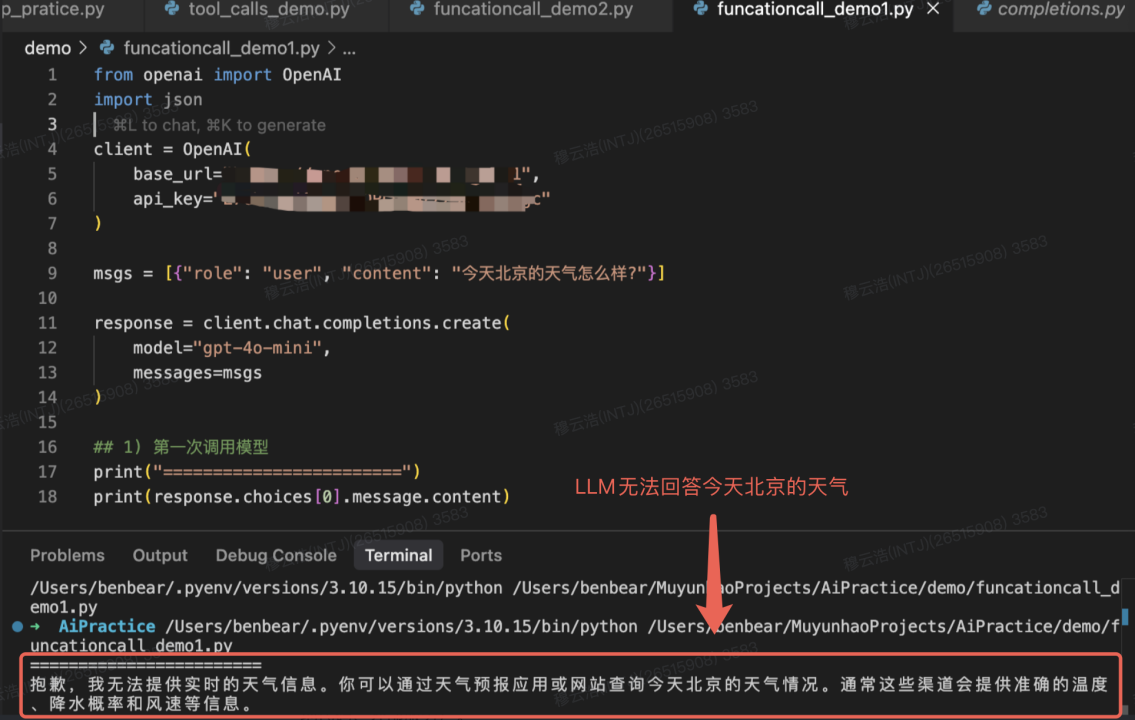
大语言模型(LLM)的回答通常会受限于训练数据,它们缺乏对实时数据的认知,例如让大模型查询今天天气、股票价格等是不可能的。让我们举个 OpenAI 官网的栗子,咨询一下 gpt-4o-mini:“今天北京的天气怎么样?”。此时,LLM 会因为预训练数据中没有相关答案,而无法回答这个问题。如图所示:
Tool Calls
Tool Calls 则为大模型提供了一种灵活的方式,使 LLM 能连接到外部数据和系统(本地代码、外部服务)。但 Tool calls 并不是 LLM 模型本身独立的能力,实际执行函数的环境不是在 LLM 内部,而是在外部系统中,这些外部系统可以是本地代码,也可以是独立运行的系统服务,LLM 模型可以通过自然语言输出的方式间接控制外部系统的执行,看起来就像 LLM 模型会以自己调用并执行 Function 一样。
以 OpenAI 官方的交互流程示例,LLM 与 Tool Calls 交互如下:
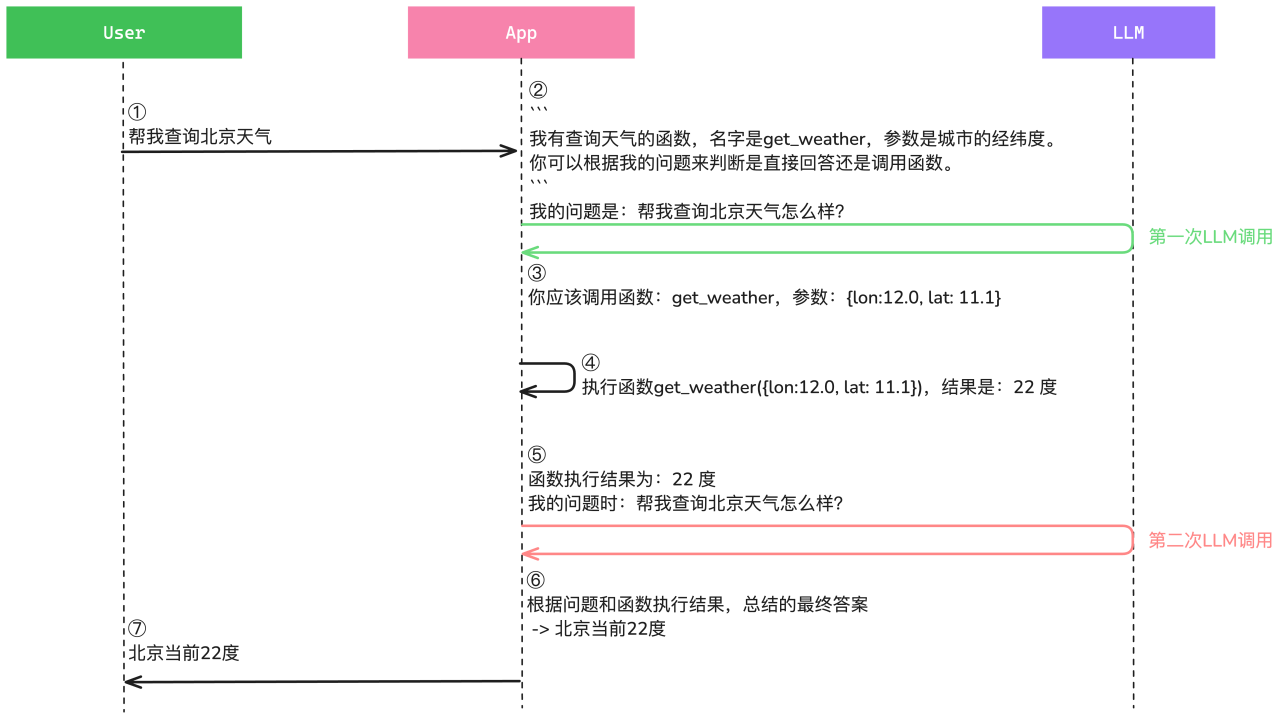
总结来说,在使用 Tool Calls 时,会产生两次大模型调用:第一次,让 LLM 决定调用哪个工具,按照协议返回工具入参。第二次,将工具执行结果放入上下文,大模型返回结果。
Talk is less, show code。下面将用实际代码来具象化描述执行过程:
a)首先,注册一个查天气的工具(tools)
本地写好 get_weather 方法,为了方便演示效果,该方法永远返回“22 度”。
将 get_weather 函数加入到的 tools 列表中(tools 是一个对象数组)。
为 get_weather 函数描述它的作用(description,description 的质量好坏能直接影响 LLM 是否能正常进行工具调用),描述它的入参规范(类型、参数名、参数含义、是否必传)。
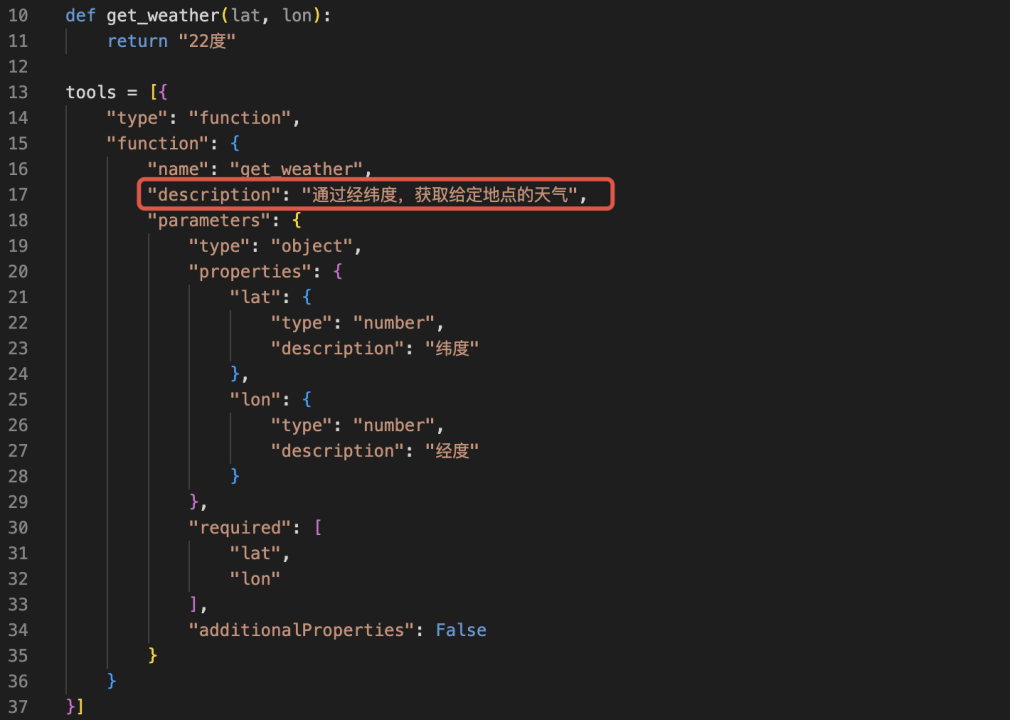
这样,一个能根据经纬度获取天气温度的工具,就注册好了。
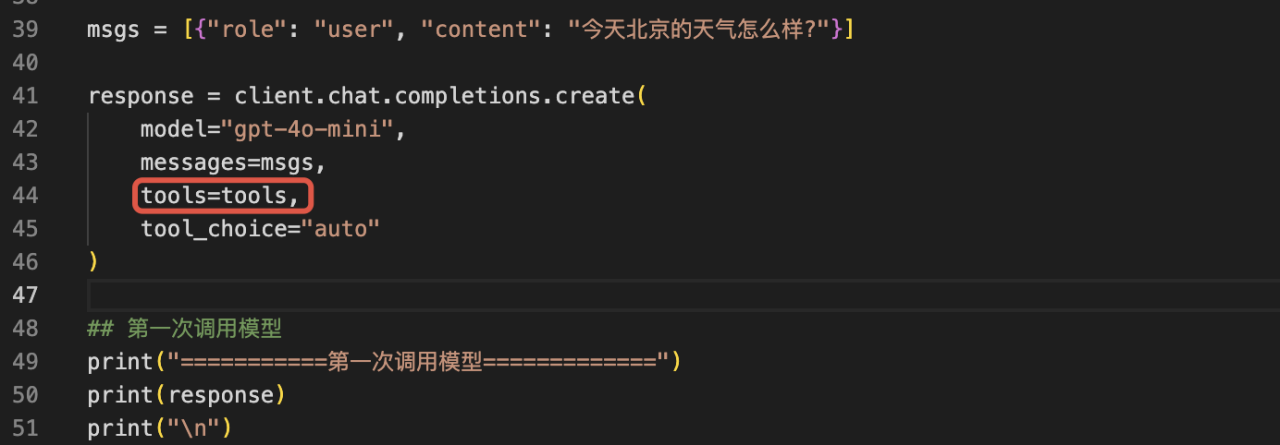
b)调用 LLM 时,将 tools 作为参数传入 LLM,由 LLM 决定是否调用工具
引入 openai SDK(python),将 tools 工具集作为参数传入到 completions-chat 中进行 client 初始化。此时,LLM 会根据用户问题,以及传入的 tools 工具集,来决定是否调用工具。
此例中,LLM 判断需要调用 get_weather 工具来获取北京的天气结果,所以,LLM 返回的结果中,message.content 为 None,message.tool_calls 中,返回了需要被调用的工具名称、入参。
需要注意的是,如果 LLM 判断不需要调用工具时,则会直接在 mesaage.content 返回答案。
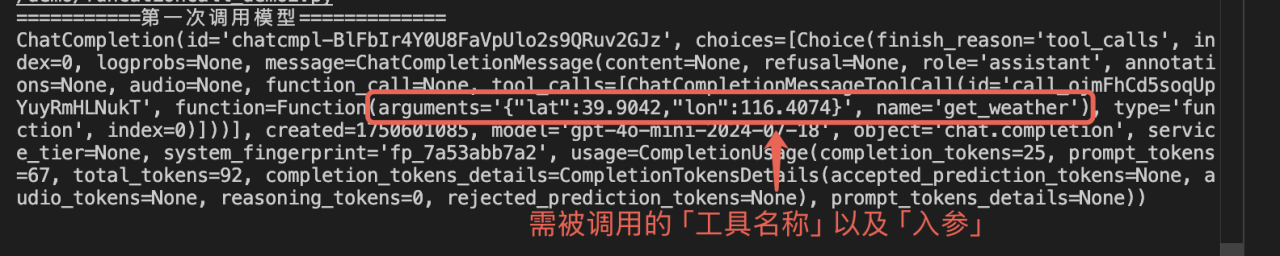
c) 执行 Tool 工具将工具执行结果放入上下文,并第二次调用 LLM
依据 LLM 返回的工具方法名称和入参,我们即可以在本地执行函数,拿到 get_weather 执行结果。
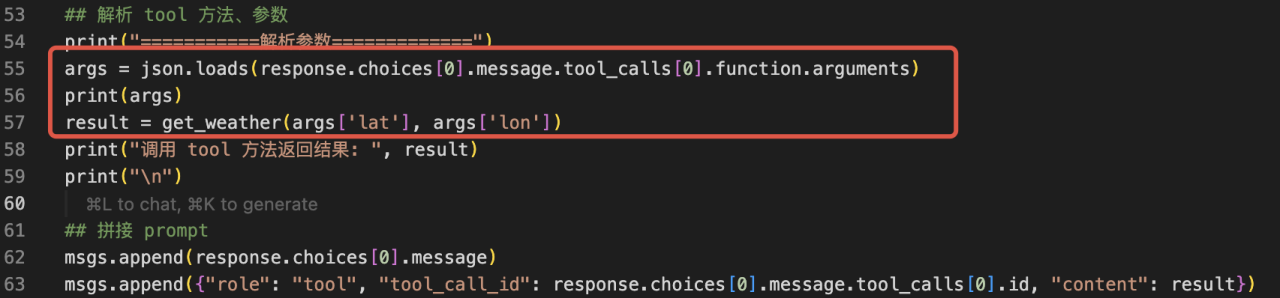
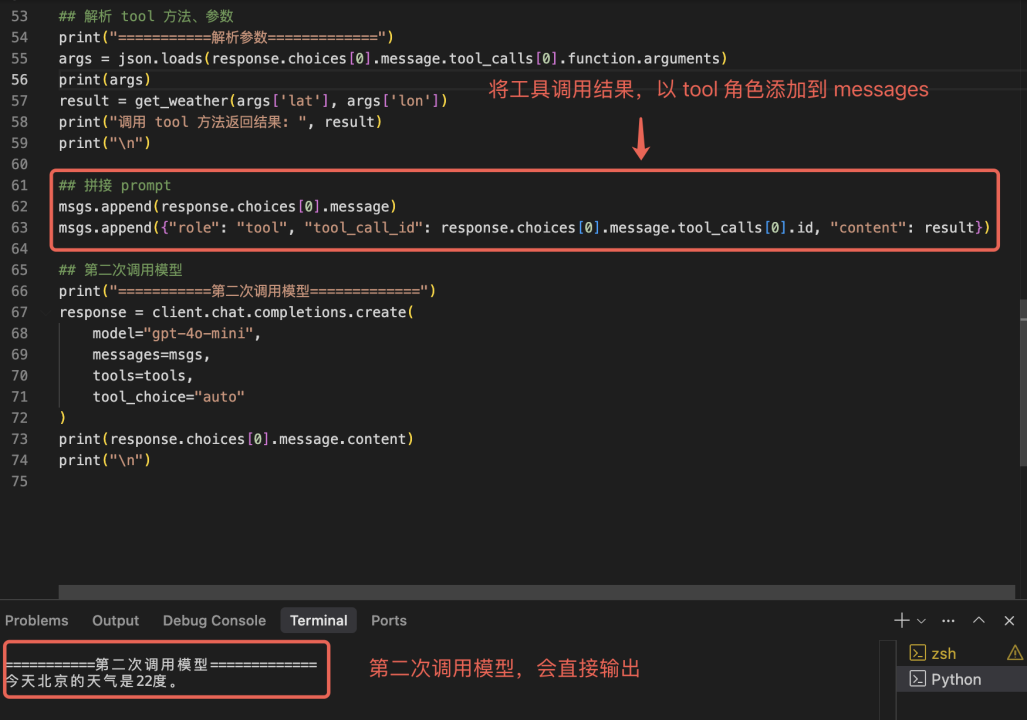
将 get_weather 的执行结果,以 tool 角色添加到 messages 中,同时发起第二次 LLM 调用。
模型返回结果 message.content => “今天北京的天气是 22 度。”
相信大部分开发者习惯用 Langchain 等优秀框架,在 LLM 中使用工具调用,感觉就一个 SDK API 调用就完事了。诚然,Langchain 为用户做了极其友好的,开箱即用的各种 API,方便开发者们快速构建 AI 应用,但是在提供各种开发便利的同时,Langchain 屏蔽了很多底层实现细节。希望本例中实际代码,能帮助大家更进一步了解 Tool calls 背后的实际工作原理。
读到这里,或许有人就会有疑问了,不是讲 MCP 吗?怎么就一直在讲 Tool calls?别慌,这就来。
MCP 协议详解
首先,在你的应用第一次向一个 LLM (比如 OpenAI 的 GPT、Google 的 Gemini 或 Anthropic 的 Claude)发送请求后,一旦 LLM 决定使用外部工具来回答你的问题时,不同 LLM 厂商返回的工具调用指令 的数据结构不同的,例如:
OpenAI (GPT):会在响应的 message 对象中包含一个 tool_calls 数组,数组中每个元素格式如下:
{ "id": "call_ojmFhd5...", "type": "funcation", "name": "get_weather", "arguments": "{\"lat\":39.9042, \"lon\":116.4074}"}Anthropic (Claude):会在响应的 content 数组中包含一个 tool_use 代码块
{ "role": "assistant", "content": [ { "type": "text", "text": "<thinking>To answer this question, I will: 1....." }, { "type": "tool_use", "id": "toolu_ojmFhd5...", "name": "get_weather", "input": {"lat":39.9042, "lon":116.4074} } ]}Gemini(Google) 格式如下:
{ "funcationCall": { "name": "get_weather", "args": {"lat":39.9042, "lon":116.4074} }}往往开发者需要针对不同的 LLM 厂商所返回的工具调用指令做不同的数据格式适配,接入的 LLM 越多,这个适配过程越痛苦。MCP,则是一个基于 JSON-RPC 2.0 的开源协议,创建一个标准化的中间层,像一个”通用适配器“一样,旨在统一 LLM 与外部工具调用的交互方式,解决了因不同 LLM 返回的工具调用指令格式不一所带来的适配工作量问题。
在没有 MCP 之前,我们可能需要这么做:
def process_llm_tool_call(response: dict, provider: str):"""接收来自不同 LLM 的响应,解析其独特的工具调用格式,然后执行本地工具。这是适配工作量集中的地方。"""tool_name = Nonetool_args = {}
# ==========================================================# 这部分代码就是为适配不同模型而产生的“胶水代码”。# 每增加一个模型,就需要增加一个新的 `if/elif` 块。# ==========================================================if provider == "openai": try: tool_call = response["choices"][0]["message"]["tool_calls"][0] tool_name = tool_call["function"]["name"] # OpenAI的参数是JSON字符串,需要解析 tool_args = json.loads(tool_call["function"]["arguments"]) except (KeyError, IndexError, TypeError) as e: print(f"Error parsing OpenAI response: {e}") return elif provider == "anthropic": try: tool_call = next(item for item in response["content"] if item["type"] == "tool_use") tool_name = tool_call["name"] # Anthropic的参数直接是字典可以看到,示例中存在大量”胶水“代码,增加开发者工作量,但有了 MCP 协议之后:
所有的 MCP Server 上的工具接受如下形式的请求结构:
所有的 MCP Server 返回数据结构(也即 MCP client 接收到的响应):
{ "id": 2, "jsonrpc": "2.0", "result": { "content": [ { "type": "text", "text": "22度" } ] }}MCP Client 中将不同 LLM 返回的工具调用指令适配为 MCP 协议规定的请求体格式、发送到 MCP server 并解析结果,最终返回给用户。对开发者而言,只需要关注 MCP Server 的实现细节,MCP Client 会自动将各个大模型的输出转换为标准请求,开发者无需关心模型间的差异。
MCP 调用实践
讲完 MCP 协议,示例下如何用 langchain_mcp_adapters + langgraph 去调用 MCP Server:
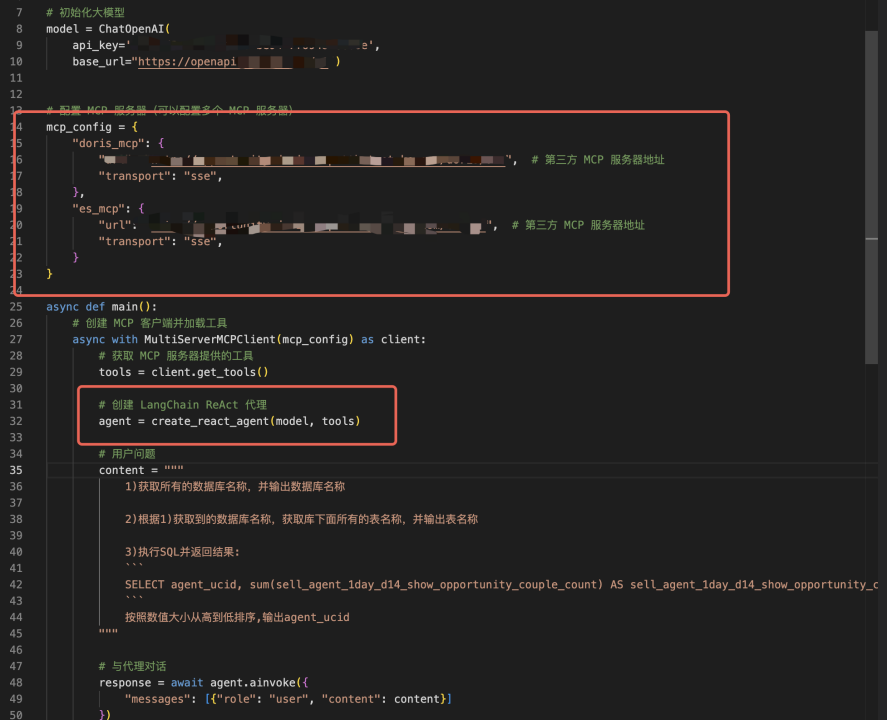
找到提供服务的 MCP Server 地址
此例中,我们集成了 Doris MCP server,该 server 背后连接了贝壳商机平台中的 Doris 数据库。
初始化 LLM Client
Langgraph 是 Langchain 生态系统中的一部分,专门用于构建基于 LLM 的复杂工作流和 Agent 系统,示例中使用 Langgraph 中的 create_react_agent 来初始化 LLM Client。
create_react_agent 需要传入两个参数,一是大模型 model,二是外部工具列表,使用 client.get_tools 可以直接获取 MCP Server 上所有的工具列表。
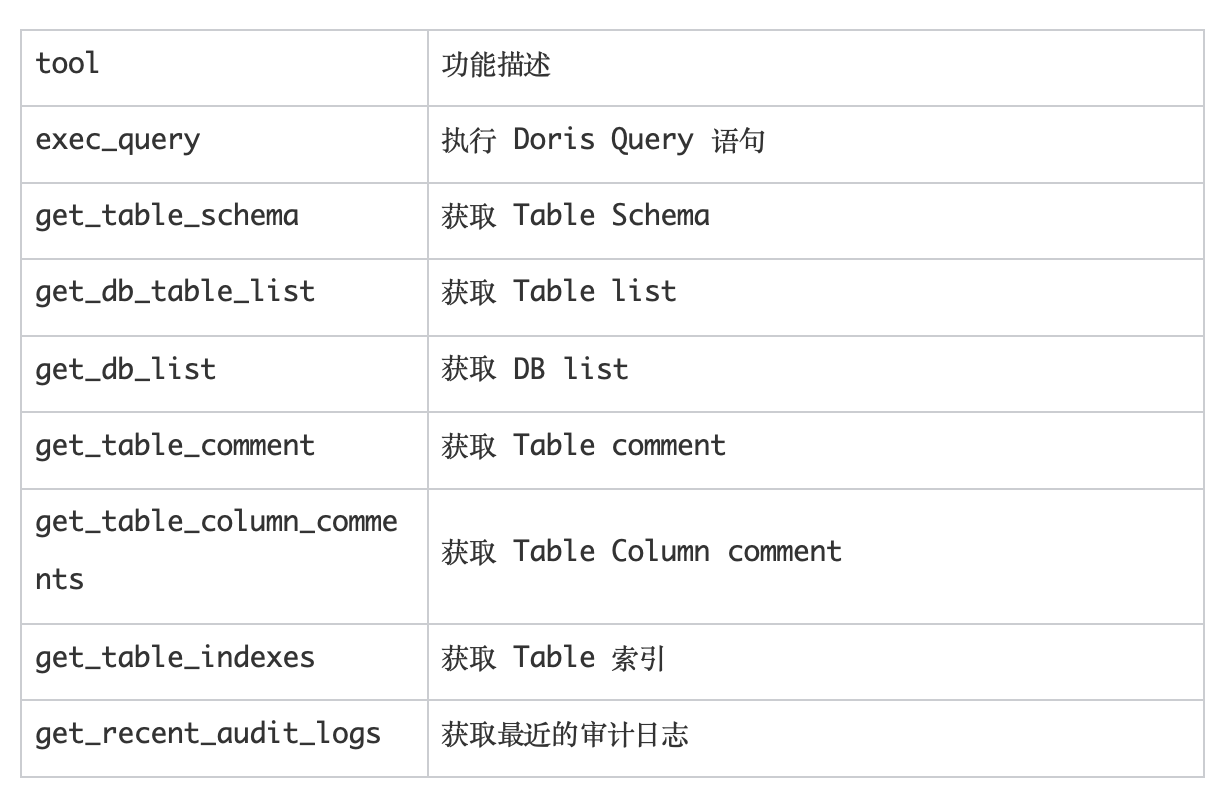
该 MCP Server 背后提供 8 个 tools,功能分别如下:
写模型 prompt
在 prompt 中让 LLM 执行三个数据库操作:1) 获取所有 Doris 数据库名称,2)根据库名获取库下所有表名 3)执行一段 SQL 并返回结果。
可以看到,大模型最终返回的结果中如预期的分别执行了以上的数据库操作。在传统的工作流编排中,一般是需要实现「意图识别->参数提取-> API 调用->结果解析」 的,这一定程度上会抑制模型的智慧,而使用 MCP Server 则让 LLM 充分的自主决策是否选择调用外部工具,充分发挥大模型的智慧,并且随着以后大模型能力的快速迭代和提升,准召率也会自然而然随之提升。
本例中使用了 OpenAI 的模型,如想更换为 Google 的 gemini 模型或者 Anthropic claude 模型,直接替换 model 变量即可,无需更多代码适配的开发量。
Funcation Call 和 MCP 的核心区别是什么?
总结来说,Funcation Call 不是协议,是大模型为了连接外部系统或数据所提供的一种能力,MCP 里的工具调用,是基于 Funcation Call 能力实现的,对于工具来说,MCP 和 Funcation Call 是依赖关系。但 MCP 除了工具外,还有 Prompts、Resources 等其它上下文定义。
MCP 当前的不足
Tool Call 是大模型连接外部世界的”能力基石“,MCP 则是推进各模型生态协同的”协议桥梁“。MCP(模型上下文协议)解决了各模型厂商中 Tool Call 接口格式不一的问题,实现了跨模型、跨工具的统一交互标准,实现了”一次开发、多模运行“的规模化效应,成为了 AI 技术生态中的“USB-C”,让工具只需要按统一协议封装一次,即可在多模型中通用,大幅降低跨模型之间的适配成本。
这一点非常重要:如果你有 n 个模型或 Agent,要接入 m 个数据源,那你不该为了每一个组合都单独写接入逻辑,工作量不应该是 n x m,而应该是 n + m。MCP 正是朝着这个方向迈出的非常棒的第一步。
尽管 MCP 看起来如此闪耀,但落地时仍会面临许多挑战:
社区生态成熟度不足:MCP 应用市场中虽有超 1.3w+ MCP server,但实现方式不规范、且同质化严重,能直接用于生产环境的工具很少。吴恩达教授在分享中也指出,MCP 虽然非常令人兴奋,但目前尚处”蛮荒“,很多 MCP server 其实都跑不起来,身份验证系统也很混乱。同时,接入数据源越多,MCP 会返回一个很长的工具资源列表,成百上千个 API 调用都会塞进一个扁平列表中让大模型自己筛选,这是很影响准确率的。或许之后,加入层级式的资源工具发现机制可能是个不错的解法。
准确率局限:MCP 工具是否能被准确调用,一部分靠 LLM 自身的能力(与 LLM 是否支持 Tool Call、LLM 预训练过程相关),一部分靠 Description 写的是否准确。在某些要求高准场景下(如安全审计、权限隔离),此时基于 API 开发确定性的 workflow 工作流或许更有效。
基于 MCP 构建私域数据服务--从 0 到 1 开发 ES MCP Server
在 MCP 出现之前,我们通常通过 Tool Calls 或者 动态拼接 Prompt 的方式,让大语言模型(LLM)访问我们内部的私域数据和系统。这些方式虽然可行,但在标准化和易用性上存在一些挑战。
如今,通过 MCP 协议构建大模型应用生态已成为一种新范式。它就像是为大模型和企业内部服务之间搭建了一座“标准化的桥梁”。我们就以 Elasticsearch(ES)为例,从 0 到 1 动手开发一个 ES MCP Server,让 LLM 能够以标准快捷的方式查询 ES 数据。
定义你第一个“工具”(Tool)
本示例基于 FastMCP 框架开发,这是一个基于 Python 的轻量级框架,可以帮助开发者急速构建 MCP Server,让我们能专注于业务逻辑的实现,无需关心 MCP 协议本身的复杂细节。
a. 工具声明
在 MCP 的世界里,一个“工具”就是一个封装好的、可被 LLM 理解和调用的函数。它有三个核心要素:名称、描述和输入参数。这三要素将作为“说明书”,告诉 LLM 这个工具是做什么的、怎么用。
让我们从最核心的 search_by_dsl 工具开始。
我们使用 @mcp.tool 装饰器来声明一个工具。
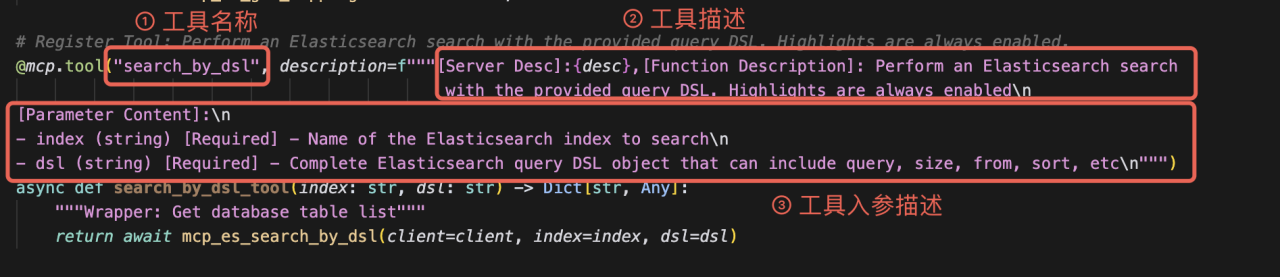
我们做了几件事:
1. @mcp.tool:这个装饰器是关键,它告诉 FastMCP:“Hi,这是一个工具,请把它管理起来。
2. 函数名 search_by_dsl :自动成为工具的名称。
3. 工具描述 description:这段描述至关重要,LLM 将依据它来判断在何种场景下应该调用此工具。
4. 函数参数(index: str, dsl: dict):自动成为工具的入参。类型注解(str, dict)会被框架用来做参数校验,确保 LLM 传来的参数格式正确。
b.功能实现
声明只是“说明书”,接下来我们需要填充工具的具体逻辑。这里我们引入官方的 Elasticsearch Python SDK 来执行查询
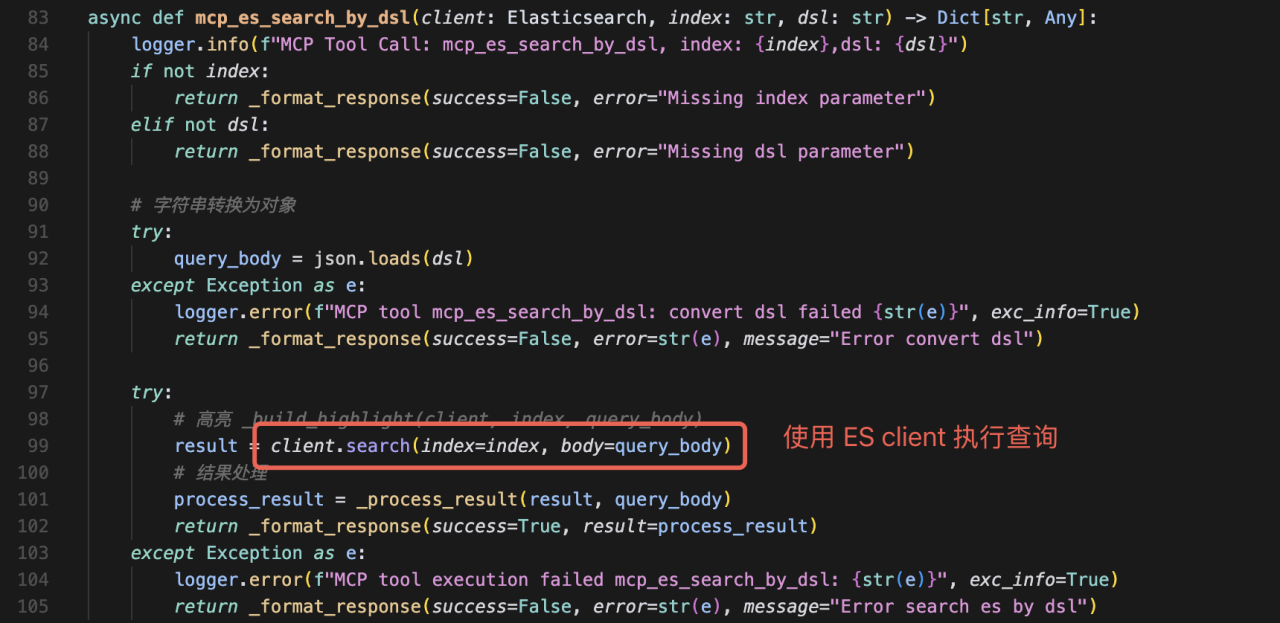
至此,我们的第一个工具就开发完成了!它封装了调用 ES search API 的所有细节,并以一个简洁的 Python 函数形式存在。
丰富你的“工具箱”
一个强大的 MCP Server 通常包含一组相关的工具。让我们再实现一个常用的 get_mappings 工具,用于获取索引的字段定义,这对于 LLM 理解数据结构很有帮助。
@mcp.tool("get_mappings", description=f"""[Server Desc]:{desc},[Function Description]: Get field mappings for a specific Elasticsearch index [Parameter Content]: - index (string) [Required] - Name of the Elasticsearch index to get mappings for""") async def get_mappings_tool(index: str = None) -> Dict[str, Any]: """Wrapper: Get field mappings for a specific Elasticsearch index""" return await mcp_es_get_mappings(client=client, index=index) async def mcp_es_get_mappings(client: Elasticsearch, index: str = None) -> Dict[str, Any]: logger.info(f"MCP Tool Call: mcp_es_get_mappings, index: {index}") logger.info(f"test-mcp_es_get_mappings:{index}") if not index: return _format_response(success=False, error="Missing index parameter") try: # 调用 Elasticsearch 的 indices.get_mapping API 来获取索引映射信息 response = client.indices.get_mapping(index=index) if not response: return _format_response(success=False, error="index not found or has no fields", message=f"Could not get mapping for index {index}")
以此类推,我们可以逐渐强大我们的“工具箱”。
对外发布及验证
工具开发完成后,我们需要将它们打包成一个标准的 MCP 服务暴露出去,等待 LLM 的调用。
FastMCP 让这个过程变得极其简单。它底层使用 SSE (Server-Sent Events,一种轻量级的单向通信协议)来发布服务。
只需运行 mcp.run(),一个功能完备的 ES MCP Server 就在你指定的端口启动了。
你可以访问http://127.0.0.1:8000/sse 来访问服务是否启动正常,当前你可以直接使用 MCP inspector 来直接测试和 debug 你的 MCP Server。
在贝壳商机平台的 AI workflow 编排平台中,可在 LLM 工具调用节点中直连 MCP Server,快速的将 MCP server 与 LLM 绑定起来。
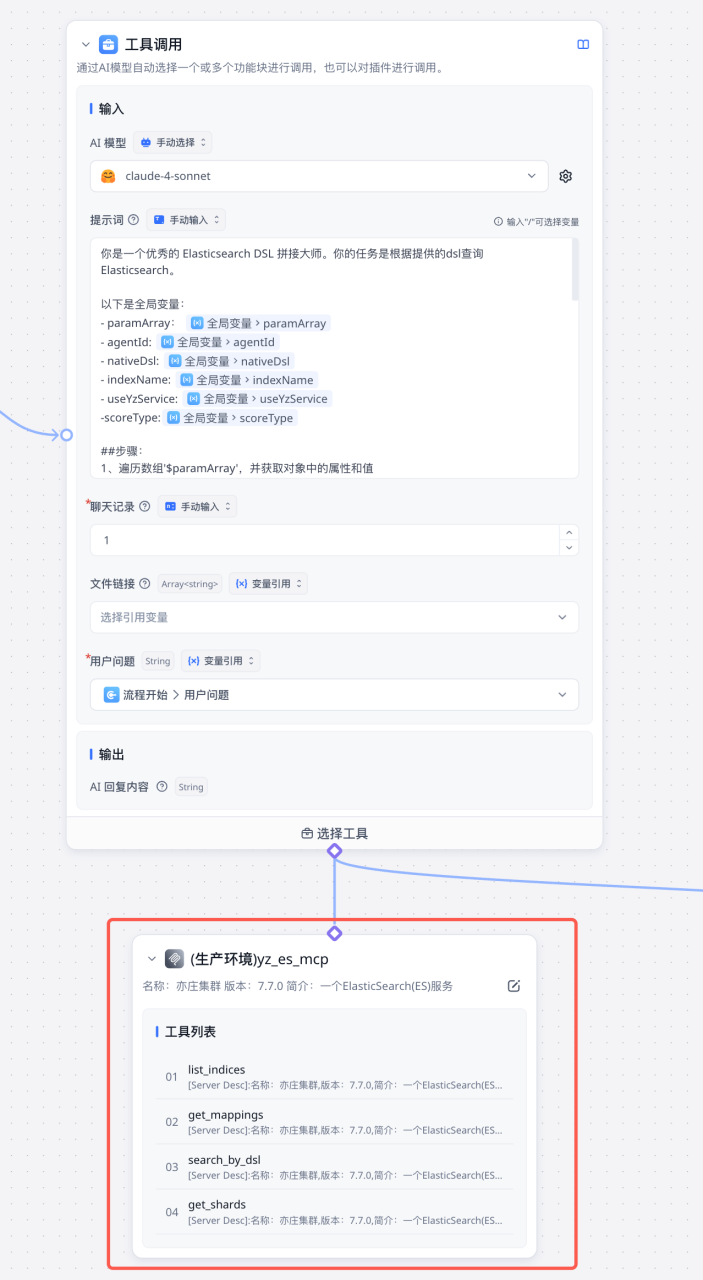
MCP Gateway
这里会自然而然引出一个工程化的问题:如果企业内有成百上千个服务,我们难道要为每一个都手写一个 MCP Server 吗?这显然不现实。
这正是 MCP Gateway 出现的意义所在。
为了解决这个问题,我们可以引入一个中间层——MCP Gateway。能够将企业内已有的、标准的 HTTP/API 接口,实时、动态地转换成符合 MCP 协议的工具,而无需对现有业务系统进行任何代码改造。
在这里,我们推荐一个优秀的开源项目:
GitHub - AmoyLab/Unla:
MCP Gateway - A lightweight gateway service that instantly transforms existing MCP Servers and APIs into MCP servers with zero code changes. Features Docker deployment and management UI, requiring no infrastructure modifications.
它的核心优势是:配置驱动,业务无侵入
业务无侵入:你的业务系统可以是任何语言(Java, Go, Python, Node.js)开发的,只要它提供了标准的 RESTful API 接口。你完全不需要修改一行业务代码,也无需关心什么是 MCP。你的服务继续做它最擅长的事情。
配置驱动,开箱即用:你不需要编写任何代码,只需要通过简单的 YAML 文件或前端页面上“填表单”,就能完成一个 API 到 MCP 工具的转换。
统一配置和注册中心:
· 统一入口:所有 AI Agent 只需连接到 Gateway 这一个地址,就能发现企业内所有可用的工具。
· 集中管理:认证、授权、限流、日志、监控等治理策略都可以在 Gateway 层统一实施,而无需在每个业务服务中重复实现。
· 动态更新:可以随时通过修改配置来上线、下线或更新工具,无需重启后端业务系统。
在贝壳商机平台内部,服务间会存在很多 Dubbo RPC 调用,因此,我们也正在开发 Dubbo2MCP 功能,届时也会提交 PR 到社区里。
写在最后
当 Manus 以颠覆性姿态叩开通用 AGI 时代的大门时,当 OpenAI 的 Responses API 用几行代码重构人机协作的边界,整个硅谷都在为之举杯相庆时,在开源社区的土壤深处,Model Context Protocol(MCP)正如一粒觉醒的种子,悄然舒展根系——它不急于争夺阳光下的喝彩,而是默默构建连接万物的地下网络,为智能体世界铺设真正的数字脉络。




