
运营数据库中的每笔交易都讲述着一个故事——客户购买、库存更新或用户交互。然而大多数企业仍需等待数小时甚至数天才能对这些洞察采取行动,用昨日的数据进行分析的同时,实时机会悄然流失。
以下痛点屡见不鲜:工程团队受困于防火墙后的运营数据库;脆弱的 ETL 管道因模式变更而崩溃;批处理窗口造成关键业务延迟——从业务事件发生到可用于分析之间存在数小时滞后。
随着 Snowflake 近期对 Crunchy Data 的收购,我们正通过 Snowflake Postgres 构建运营数据与分析数据统一于单一系统的愿景——不再需要为分析目的转移事务数据。但我们也认识到许多企业将继续使用 Snowflake 之外的传统 OLTP 数据库。这正是 Openflow 的变更数据捕获(CDC)技术发挥关键作用的领域,它通过将任何运营数据库的变更无缝流式传输至 Snowflake AI 数据云,为实时分析和 AI 应用提供了处理传统 CDC 工作的全新视角。
技术挑战:从数据库日志到分析洞察
传统的变更数据捕获(CDC)实施方案面临复杂的工程挑战。开发人员需要深入解析特定数据库的事务日志——如 PostgreSQL 的预写日志(WAL)、MySQL 的二进制日志、SQL Server 的变更跟踪功能、Oracle 的重做日志——同时还需处理各数据库复制协议的复杂细节。随后必须将这些变更可靠地流式传输到数据平台,优雅地处理模式演进,并维护精确一次(exactly-once)的交付语义。
我们通过 Openflow 数据库连接器着力解决的核心问题包括:
安全与网络隔离:多数事务型数据库部署在防火墙和内网虚拟私有云中,处于严格隔离环境,无外部互联网暴露。
大规模性能要求:需同时跨数百张表以每秒 20,000+变更事件的速率处理数据。
模式演进能力:自动适应数据定义语言(DDL)变更,例如字段增删、重命名或删除。
运维复杂性:维护 CDC 基础设施、处理故障场景并确保数据一致性。
Openflow 的 CDC 架构:原生协议与 Snowpipe Streaming 的融合
我们设计的 Openflow 数据库连接器,将数据库原生 CDC 协议与 Snowflake 的高性能 Snowpipe Streaming API 相结合。每个连接器的核心均通过 Apache NiFi 数据流实现,既可部署于 Snowflake 托管基础设施中,也可通过后文将详述的 BYOC(自带云)模式直接部署于客户 VPC 内。
数据库原生变更捕获
Openflow 连接器并非通过解析 SQL 语句或轮询变更实现,而是直接接入各数据库的原生复制流:
PostgreSQL:通过预写日志(WAL)进行逻辑复制,支持将 wal_level 参数配置为 logical
MySQL:通过二进制日志(binlog)复制实现实时变更捕获
SQL Server:通过变更追踪(CT)API 实现增量数据提取
Oracle(即将支持):通过 XStream API 实现高性能变更数据捕获该技术方案具有多重优势
其一,实现真正的实时捕获:变更在提交至数据库的瞬间即可被检测。其二,通过采用高效的原生复制机制而非查询生产表,显著降低对源数据库的性能影响。
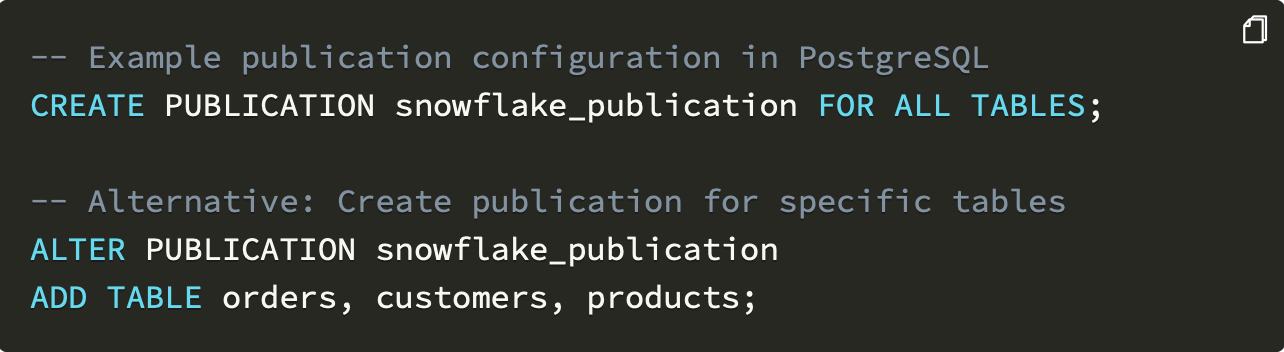
OpenFlow 中的连接器配置支持灵活的表选择模式
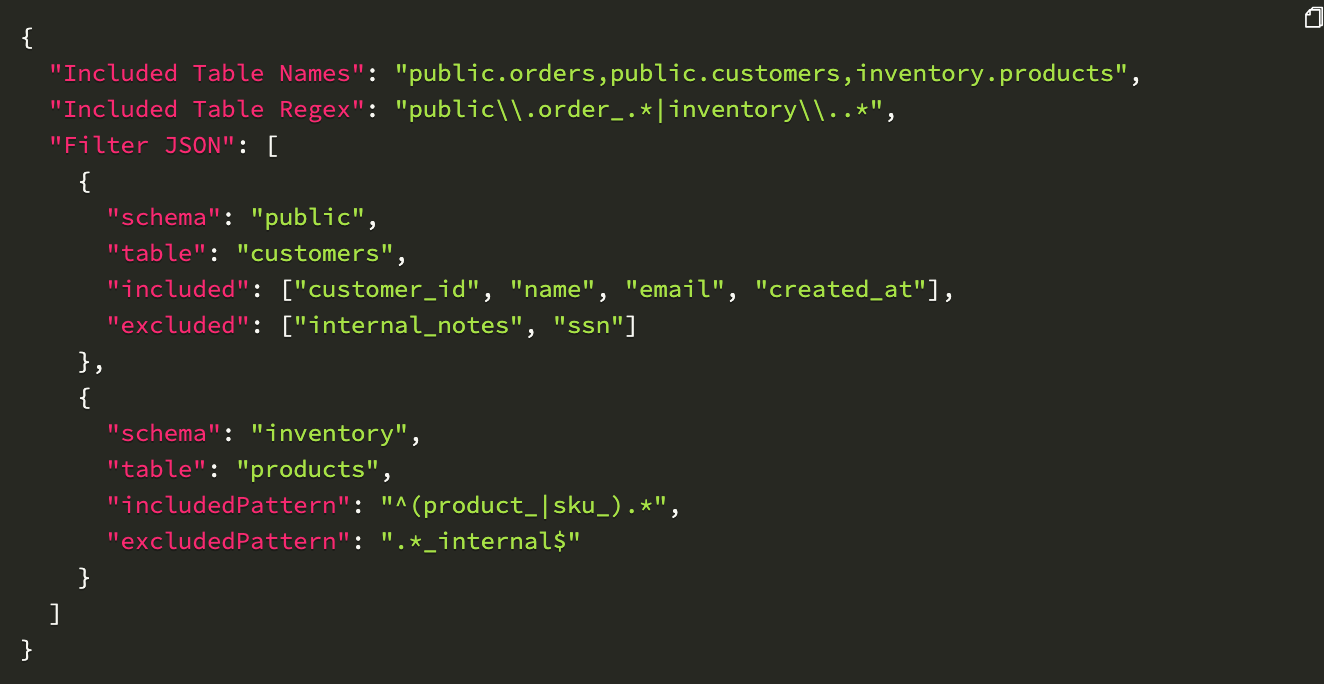
高性能流处理架构
OpenFlow 的核心突破在于将数据库原生 CDC(变更数据捕获)流与 Snowflake 的 Snowpipe Streaming API 无缝桥接。我们的连接器采用先进的缓冲与流处理机制,既能处理高吞吐量数据流,又能确保至少一次(at-least-once)的投递语义。
每个 OpenFlow 连接器作为多线程 NiFi 数据流运行,包含以下核心组件:
CDC 捕获处理器:通过原生 API 读取数据库复制日志(例如 CaptureChangeMySQL、CaptureChangePostgreSQL、CaptureChangeSqlServer)
流缓冲层:在内存中累积变更数据,实现最优批量流传输
Snowpipe Streaming 客户端:将缓冲的变更数据流式传输至 Snowflake 通道(例如 PutSnowpipeStreaming)
合并执行引擎:调度 MERGE 操作以将变更应用到目标表,并在执行合并时压缩数据(例如 MergeSnowflakeJournalTable)

双表架构实现变更历史追踪
我们的关键创新之一是采用双表架构进行 CDC 数据管理。针对每个源表,我们创建:
目标表:存储数据的当前状态,通过 MERGE 操作持续更新。
日志表:仅追加表,完整记录所有数据变更历史,包含支持 SCD2 分析的元数据和有效载荷,提供至少一次投递保证,并在合并操作期间执行压缩。
日志表完整捕获变更历史:
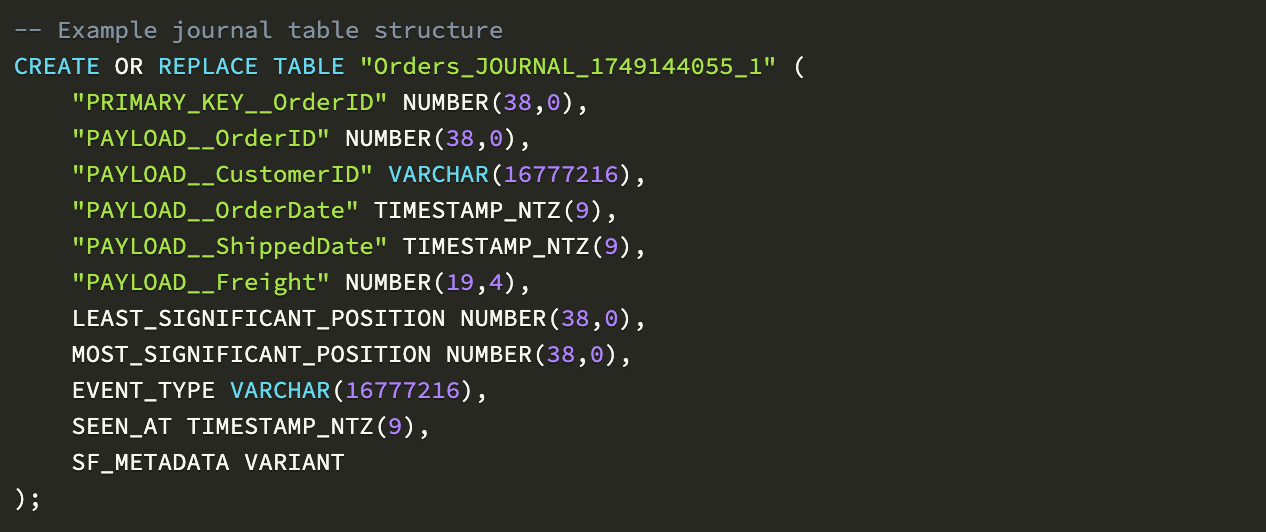
该架构支持多种强大用例:
时间点分析:查询历史任意时刻的数据状态
变更审计:追踪变更内容及发生时间
事件溯源:通过变更流重建业务事件
合规报告:维护不可篡改的审计追踪
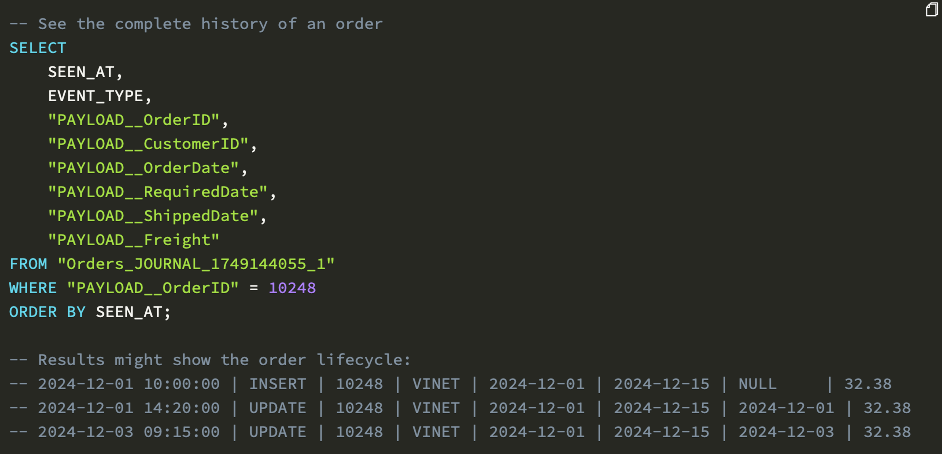
示例:通过日志表跟踪订单的完整生命周期。
应对企业级挑战
安全性:BYOC 部署模式实现增强控制
在 OLTP CDC 场景中,数据集成常见挑战在于既确保穿越客户网络的安全性,又兼顾灵活性与可控性。为此,BYOC(自带云)部署方案提供了理想的解决方案。Openflow 在客户 VPC 内创建基础设施,通过私有子网托管 EKS 集群。这意味着敏感的数据库连接不会超出您的网络边界——控制平面仍由 Snowflake 统一管理监控,而所有数据流动均严格限定在您的安全边界内。
BYOC 部署提供:
网络隔离:数据库连接器运行于您的私有子网
传输加密:所有通信均采用 TLS 加密协议
密钥管理:支持与 AWS 密钥管理服务或 HashiCorp Vault 集成
合规性:满足数据本地化的监管要求
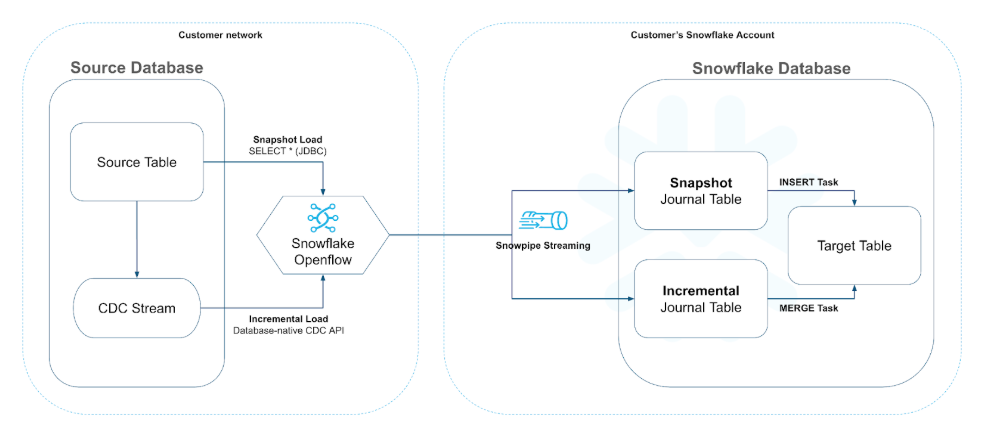
图 1:Openflow BYOC(自带云)部署架构示意图,展示了从源数据库到 Snowflake 的安全灵活数据集成流程,确保数据始终处于客户安全边界内。
模式演进:自动适配
我们的核心优势之一是支持源表结构变更的自动适配。当发生 DDL 变更时,系统会自动检测模式修改,更新目标表以匹配新结构,为更新后的模式创建新的日志表,并在无需人工干预的情况下实现无缝复制。
这种自动模式演进支持常见的数据库操作(如增加、重命名或删除列),消除了传统 CDC 实施方案中最大的运维痛点。
超越传统 ETL:面向 AI 的实时数据就绪
当结合现代 AI 与分析用例时,Openflow 的 CDC 架构真正优势得以显现。该架构通过近实时双向数据流,将企业数据与 AI 系统连接——无论模型或智能体位于何处。
通过近实时变化数据流,您可以:
构建实时机器学习特征库:通过分钟级最新数据持续更新机器学习特征,实现更精准及时的模型预测启用
事件驱动型分析:在业务事件发生瞬间自动触发分析与告警,实现即时洞察与响应
实现实时个性化推荐:基于即时客户行为数据驱动推荐引擎,提供高相关性且与时俱进的用户体验
驱动运营型 AI:通过最新系统状态赋能智能自动化,实现更灵敏高效的自主运营
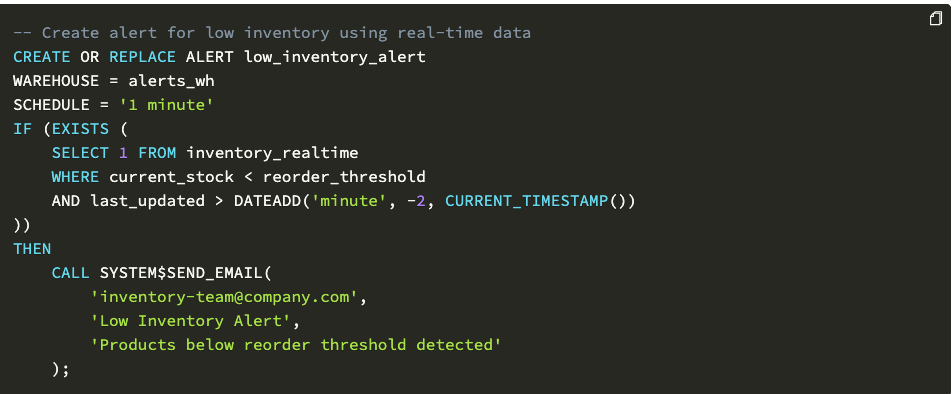
示例:基于 Snowflake 告警的事件驱动分析方案
展望未来:数据移动技术的演进方向
Openflow 标志着数据集成理念的根本性变革。通过将数据库原生 CDC 协议与云原生流式架构相结合,我们成功打破了性能、安全性和运维简易性之间传统的权衡取舍。
随着企业日益广泛部署人工智能代理和实时应用,能否在数秒而非数小时内获取新鲜、一致的数据已成为关键竞争优势。我们正持续投入建设 Snowflake Openflow 平台,即将推出包括 Oracle 数据库支持、多云部署架构、扩展型连接器生态以及 Apache Iceberg 表支持等核心功能——这一切都致力于让实时数据集成变得像执行 SQL 查询般简单可靠。
批处理时代正走向终结。未来属于能够以商业速度安全可靠地海量传输数据的架构——而这样的未来已通过 Openflow 成为现实。
原文地址:https://www.snowflake.com/en/engineering-blog/real-time-change-data-capture-openflow/




