

本文最初发布于Medium.com,经原作者授权由 InfoQ 中文站翻译并分享。
互联网上的信息如此之多,任何人穷其一生也无法全部消化吸收。你需要的不是访问这些信息,而是一种可伸缩的方式,可以用来收集、组织和分析这些信息。你需要的是 Web 爬取。Web 爬取可以自动提取数据,并以一种让你可以轻松理解的格式显示出来。Web 爬取可以用于许多场景,但本教程将重点介绍它在金融市场中的应用。
互联网上的信息如此之多,任何人穷其一生也无法全部消化吸收。你需要的不是访问这些信息,而是一种可伸缩的方式,可以用来收集、组织和分析这些信息。
你需要的是 Web 爬取。
Web 爬取可以自动提取数据,并以一种让你可以轻松理解的格式显示出来。Web 爬取可以用于许多场景,但本教程将重点介绍它在金融市场中的应用。
如果你是一名狂热的投资者,每天获取收盘价可能是一件比较痛苦的事情,尤其是当你需要的信息需要查看多个网页才能找到的时候。我们将通过构建一个网络爬取器,从互联网上自动检索股票指数,简化数据提取。

准备
我们将使用 Python 作为爬取语言,并使用一个简单而强大的库 BeautifulSoup。
对于 Mac 用户而言,OS X 预装了 Python。打开终端,输入
python --version。你应该可以看到 Python 的版本是 2.7.x。对于 Windows 用户,请通过官方网站安装 Python。
接下来,我们需要使用 pip(一个 Python 包管理工具)获取 BeautifulSoup 库。
在终端输入:
注意:如果你运行上述命令失败,试下在每一行前面加上 sudo。
基本概念
在一头扎进代码之前,让我们先了解下 HTML 的基本概念和一些爬取规则。
HTML 标签
如果你已经了解了 HTML 标签,大可以跳过这部分。
这是 HTML 页面的基本语法。每个<tag>服务于网页里的一个块:
<!DOCTYPE html>:HTML 文档必须以类型声明开始。HTML 文档包含在
<html>和</html>之间。HTML 文档的 meta 和 script 声明位于
<head>和</head>之间。HTML 的可视部分位于
<body>和</body>标签之间。标题的定义通过标签
<h1>到<h6>。段落使用
<p>标签定义。
其他有用的标签还有超链接标签<a>、表格标签<table>、表格行标签<tr>、表格列标签<td>。
此外,HTML 标签有时带有id或class属性。id属性为 HTML 标签指定一个惟一的 id,并且该值在 HTML 文档中必须是惟一的。class属性用于为具有相同 class 的 HTML 标签定义相同的样式。我们可以使用这些id和class帮助定位我们想要的数据。
要了解关于 HTML标签、id和class的信息,请查阅 W3Schools教程。
爬取规则
你应该在爬取之前检查网站的条款和限制。请仔细阅读关于合法使用数据的声明。通常,你收集的数据不应用于商业目的。
用你的程序从网站请求数据时不要过激(也称为滥发),因为这可能会对网站造成破坏。确保你的程序以一种合理的方式运行(即表现得像个人)。每秒请求一个页面是很好的做法。
网站的布局可能会不时发生变化,所以一定要重新访问网站,并根据需要重写代码。
查看页面
作为例子,让我们看一个来自Bloomberg Quote网站的页面。
作为关注股票市场的人,我们希望从这个页面上获取指数名称(标准普尔 500)及其价格。首先,右键单击并打开浏览器检查器来查看网页。
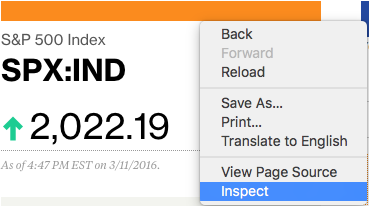
尝试把鼠标悬停在价格上,你应该可以看到一个蓝框。单击它,就可以在浏览器控制台中选择相关的 HTML。
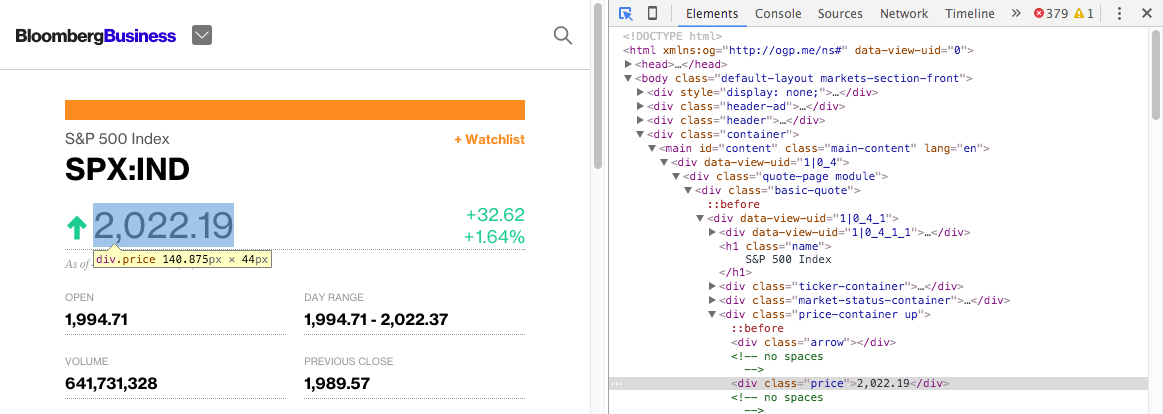
从中我们可以看到,价格位于多层 HTML 标签之中,即<div class="basic-quote"> → <div class="price-container up"> → <div class="price">。
类似地,如果你将鼠标悬停并单击名称“S&P 500 Index”,就会看到它位于<div class="basic-quote">和<h1 class="name">中。
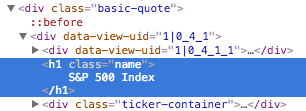
现在,我们已经借助 class 标签知道了数据的唯一位置。
进入代码
现在,我们已经知道我们想要的数据在哪,我们可以开始编写 Web 爬取器了。现在,打开编辑器。
首先,我们需要导入我们将要用到的库。
接下来,声明一个保存页面 URL 的变量。
然后,使用 Python urllib2 获取上述 URL 指向的 HTML 页面。
最后,将页面解析成 BeautifulSoup 的格式,这样我们就可以使用 BeautifulSoup 处理它了。
现在,我们有一个包含页面 HTML 的变量soup。从这里开始我们可以编写提取数据的代码了。
还记得我们需要的数据所独有的标签层次吗?BeautifulSoup 可以帮助我们进入这些层,并使用find()提取内容。在本例中,由于 HTML class 属性的名称在这个页面上是惟一的,所以我们可以简单地查询<div class="name">。
在找到标签之后,我们就可以通过获取其text属性来获取数据。
类似地,我们也可以获取指数价格。
运行程序,你应该可以看到它给出了标准普尔 500 指数的价格。

导出到 Excel CSV
现在我们要保存获取到的数据了。Excel 逗号分隔格式是一个不错的选择。它可以在 Excel 中打开,这样你就可以看到数据并轻松地处理它。
但是首先,我们必须导入 Python csv 模块和 datetime 模块来获取记录日期。将以下代码插入导入部分。
在代码底部添加将数据写入 CSV 文件的代码。
现在运行程序,你应该就可以导出到index.csv文件,然后你就可以用 Excel 打开,其中应该包含如下这行数据。

这样,你每天运行下这个程序就可以轻松获得标准普尔 500 指数的价格了,就不用在网站上翻来翻去了。
进一步探究(高级用法)
多指数
对你而言,爬取一个指数并不够用,对吗?我们可以尝试下同时提取多个指数。
首先,将quote_page改成 URL 数组。
然后,将数据提取代码放入一个 for 循环,它会逐个处理数组中的 URL 并将所有数据以元组的形式保存到变量data中。
修改数据保存部分,逐行保存数据
运行这个程序,应该就可以同时提取两个指数了。
高级爬取技术
BeautifulSoup 非常简单,适合于小规模 Web 爬取。但是,如果你对更大规模的数据爬取感兴趣,就应该考虑下下面这些选项:
Scrapy是一个非常强大的 Python 爬取框架。
尝试在你的代码中集成一些公共 API。数据检索的效率会远远高于爬取网页。例如,看看Facebook Graph API,它可以帮助你获得 Facebook 网页上没有显示的隐藏数据。
当数据变大时,考虑使用类似MySQL这样的数据库后端来存储数据。
采用 DRY 方法

DRY 的意思是“不要重复你自己”,试着像这个人一样自动化你的日常任务。还可以考虑其他一些有趣的项目,比如跟踪 Facebook 上朋友的活动时间(当然要征得他们的同意),或者在论坛上列出一些话题,并尝试自然语言处理(这是目前人工智能的热门话题)!如果有任何问题,请在下面留言。
原文链接:
How to scrape websites with Python and BeautifulSoup

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论