
随着 Agent 的逐步普及,以及 Seedream4.0、Sora2 等模型的陆续发布,AI 落地企业的进程进一步加快,数据类型变得更加丰富,数据消费的需求和链路也在发生变化,企业级数据架构正经历一次深度重构。
过去,企业依赖 ETL 与湖仓体系构建的数据管道,通常只能产出 T+1 的分析结果。但在实时交互的智能体场景中,传统架构的固有延迟已成为瓶颈。数据平台必须从静态的“分析仓库”,转型为能够实时支撑模型的“数据服务层”。
此外,数据治理的主要对象也在发生变化,多模态数据的体量正在快速增加。IDC 预测,从 2024 年到 2029 年,在中国和全球范围内,多模态数据规模都将处于高速增长阶段。6 年内增长 3 倍以上,年均复合增长率接近 30%。
这样的增速,早已超出了“湖仓一体”架构的原始设计预期。湖仓一体的概念由 Databricks 提出,并在 2020 年前后迎来大规模产品化:Delta、Hudi、Iceberg 等技术相继兴起,主要面向结构化与半结构化数据(如用户行为里的 JSON 字段),共同撑起了“湖仓一体”的黄金阶段,直到生成式 AI 的爆发打破了这一格局。
在这一背景下,AI 产业迫切需要一种全新的企业级数据架构,能够围绕多模态数据进行重点优化,既实现极致性能,又尽可能降低模型的训推成本,从而优化 GenAI 落地生产环境后的产品体验。
火山引擎给出的答案,是构建多模态数据湖:在统一底座上纳管文本、图像、音视频与向量数据,支持上下文的动态组装,并实时服务于训练、检索与在线推理,从而将数据能力从“可存可查”推进到“即取即用”的阶段。
最重要的是,其“服务对象”也在发生转变:从过去单一服务于人,逐渐扩展到同时服务人和 AI。
从“给人用”到“让模型能用”,旧思路跟不上了
某种程度上,AI 把过去“难用起来”的数据,统统变成了“数据金矿”。
合同和技术白皮书这类 PDF,不再只是归档文件,它们可以被转成可检索、可问答的知识;客服录音与通话转写,也能用来训练情绪识别与对话策略;产品图片和相关视频,可以变成多模态可检索的素材。换句话说,企业里“最难处理”的那批非结构化资产正在成为模型效果提升的直接燃料,参与检索增强与训练微调。
与此同时,数据的体量与节奏也完全不同于传统表格:图片和视频动辄比行列数据大上几个数量级;业务与设备不断产出新帧、新段落、新语音片段;更重要的是,模型本身也在“自产数据”,从生成内容到推理日志、评测结果与用户反馈,都会实时回流到训练与评估环节,持续改进整体效果。多模态由“特例”变成“默认”:输入端常常是“图片 + 文本描述”这样的组合,输出也可能跨模态,例如从文本到音频 / 视频。
因此,数据的服务对象自然发生迁移,用火山引擎数智平台产品总监王彦辉的话说:“如今服务对象从‘让人理解和使用数据(看报表)’,变成了‘让模型来使用、消费和理解数据’。”
然而,这种转换,并非没有挑战。当涉及 AI 和多模态数据集时,利用数据去改进模型的迭代周期非常痛苦。在一个工作流里,你需要能快速扫描(比如过滤和 EDA 探索),也需要支持随机访问(比如搜索或训练时的数据打乱 shuffle),还得能管理大文件,比如图片和视频,从对象存储中高效流式传输到 GPU。传统栈里鲜有系统能在这三点上同时表现出色。
在旧有地基上搭建的后果,就是你往往要为不同任务维护同一份数据的多份拷贝。如今训练数据都到 PB 了,多份拷贝成本显然也会非常高。还得手工在不同格式之间转换、保持同步,用一堆各自为政的工具。这让系统过于复杂,也让你团队里最贵的工程师把时间浪费在底层数据搬运上,而不是改进模型或 AI 应用。
因此,从管理者的角度看,如今的瓶颈已不在于“分析是否足够深入”,而在于“用于 AI 是否足够顺手”。
数据湖必须从“报表型设施”升级为“AI 原生底座”:底层不仅要能存,还要能管。其中计算从以分析为中心转向跨模态转换与混合检索的常态,管理对象从“表”扩展到模型、AI 工具与 Agent。
这也是为什么“对象存储 + 传统表格式层”已难以承载多模态的一体化诉求。Iceberg 仍是表格类数据湖的事实标准,但其面向文本 / 表数据的演进路径,难以同时满足 快速扫描 + 随机访问 + 大文件流式传输 的组合需求。企业需要与数据湖深度协同的云原生架构,用同一份数据统一支撑存储、搜索、训练到在线检索的完整 AI 工作流。
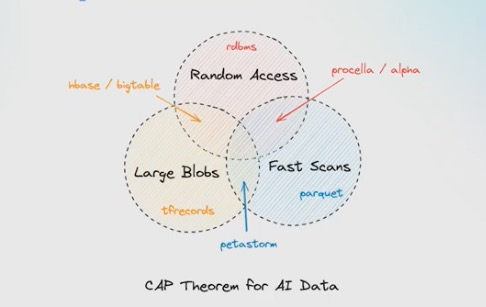
这种背景下,在调研多个开源技术路线后,火山引擎选择了 Lance 作为新的湖格式。
王彦辉表示,多模态的结合与跨模态转换的需求,自 2023 年起就呈现出快速增长的趋势。Lance 的突出优势在于对多种模态数据的原生支持,这在传统的数据湖建设中非常少见。
“可以说,我们是国内最早引入 Lance 的团队之一,并将其作为多模态数据湖的基础设施进行落地和推广。”
这一颇具前瞻性的技术选型,并非追逐热点,而是基于一个明确的判断:在 AI 定义数据架构的新范式下,对多模态的原生支持将不再是可选项,而是下一代数据湖的基石。
从“能用”到“好用”:一套“为模型服务”的开放式底座
王彦辉回忆,2023 年下半年,大模型的快速爆发成为团队的转折点。无论是字节内部,还是火山引擎服务的 ToB 客户侧,大家都已明显感受到对数据基础设施的新需求。团队随即从计算和存储两条主线入手,启动技术升级。
在计算层面,Spark 已经成为大数据处理的核心技术栈,广泛用于文本类 LLM 的任务,比如全局去重。但大模型场景下,分区数量远远超过了传统搜索或报表平台的规模,于是团队就在现有产品上不断做优化和升级。
到了 2023 年底至 2024 年初,多模态模型迅速兴起,图像、音视频等数据处理的需求骤然增加,要高效、分布式的完成数据处理,这是当时用户关注的最核心的问题,而原有的文本计算框架显得捉襟见肘。团队敏锐地捕捉到 Ray 的潜力,并在内部和客户场景中率先推广,将其作为多模态分布式计算的基石。
与此同时,存储层面也遇到了新挑战:如何在模型训练过程中支持高效点查,成为当时最亟需解决的问题。在调研国际开源技术路线时,团队注意到 Lance 格式的出现。
与传统的 Parquet、ORC 以及基于它们构建的 Iceberg、Delta、Hudi 不同,Lance 从一开始就面向 AI 时代的数据需求而设计。它的目标是成为多模态数据的 “单一事实来源”, 让文本、图像、音视频与向量都能放在同一张表中,并在其上完成分析、检索与训练。
在 AI 与多模态数据的场景里,Lance 提供了一种全新的数据湖格式。“我们当时的判断是,先要解决存储问题。如果这个环节没有在关键时间点完成突破,很多应用只能依赖临时性的 work around,而这些方案往往无法真正落地。” 王彦辉回顾道。
基于这些选型思考,团队决定以 MVP 方式快速落地产品原型,再持续迭代打磨。
火山引擎多模态数据湖一方面在 EMR 产品中快速集成了 Ray 和 Lance,另一方面也孵化出全新的 AI 数据湖服务(LakeHouse AI Service)。“这一切,都是为了更好地契合快速爆发的 AI 业务对数据基础设施的需求。”
在做出这些技术选择的背后,团队也逐渐形成了一套明确的方法论。面对新一代 AI 工作负载,他们不仅关注技术性能,还从三个维度进行判断:
其一是技术的成熟度和未来演进方向,能否持续跟上行业节奏;
其二是市场上是否存在真实而强烈的需求,避免停留在实验室阶段;
其三是上下游生态的协同度,能否与既有的数据湖、计算引擎和 AI 平台顺畅对接。
正是基于这三条标准,他们最终选择优先“补齐地基”——先解决存储与检索的核心问题,再推动计算侧的产品化与规模化,这种思路也成为后续火山引擎多模态数据湖打磨过程中的一条主线。
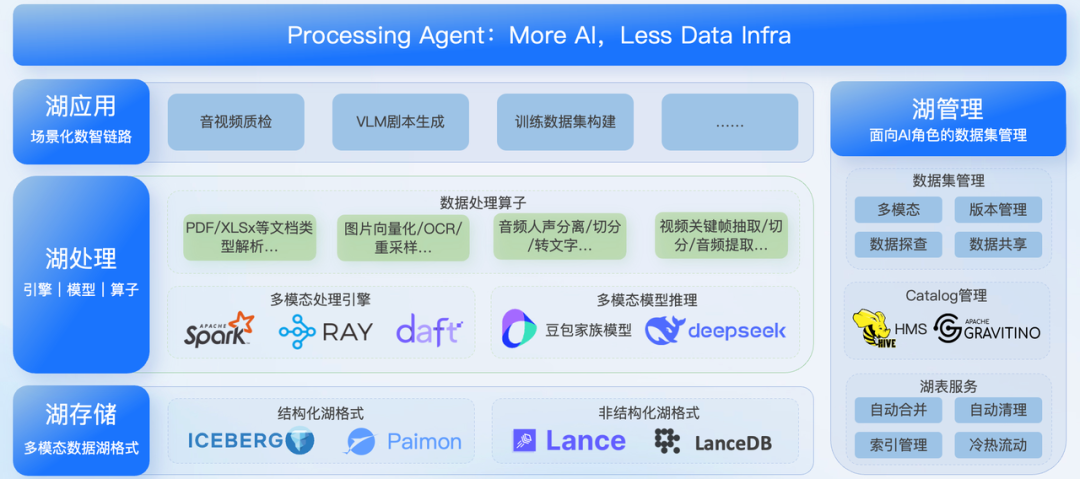
火山引擎多模态数据湖全景架构
如何把多模态数据湖“用出 AI 原生优势”
在早期技术选型阶段结束之后,火山多模态数据湖团队不再满足于“跑得起来”,而是把目标放在“跑得更高效、更易用”。
在实际使用中,用户对算力的需求往往波动极大。比如在需要快速交付一批数据时,会瞬间拉起大量算力,而数据清洗完成后,又不再需要如此多的资源。为了应对这种高起伏的负载特性,团队选择了 Ray on Kubernetes 技术栈,以保障算力的弹性调度和交付能力。
随着大模型生态的快速扩张,开发者群体数量与质量的提升也给产品提出了新要求:许多个人或小团队主要是聚焦自己的业务,并不具备非常强的数据处理或数据开发能力,但仍希望能够低门槛处理多模态数据。为此,团队将字节跳动内部最佳实践沉淀为一批 AI 数据处理算子,覆盖去重、质量评估、特征生成等关键环节,让开发者能够开箱即用地完成数据准备,缩短从原始数据到可训练样本的路径。
火山引擎把统一元数据管理从传统“只管理表”,扩展到模型、AI 工具(如检索组件)和 Agent。同一份数据从获取、清洗、切分、标注,到被哪些模型 /Agent 使用、效果如何,都能被追踪与评估;一旦线上指标出现抖动,能够快速溯源到数据或算子层面,明确是“数据不足需要补采”,还是“存在事实性错误需修正”。名义上仍是“统一元数据”,但管理对象、路径与使用场景已迥异于大数据平台时代。
在解决了这些核心问题之后,随着客户技术演进,新的关注点逐渐转向成本控制与数据管理。为此,团队又设计并提供了一系列数据管理工具,帮助用户在追求效率的同时,更好地实现成本目标。
在生态上,火山引擎多模态数据湖也以“集成”而非“替换”为原则坚持开放,与企业现有引擎与平台集成,而非一刀切替换。它既能与火山引擎内部生态(如方舟机器学习平台、向量数据库等)顺畅对接,也欢迎主流开源组件:Ray、Daft、Spark 等都可无缝接入。对外部团队来说,这意味着技术栈可选、架构可演进、无供应商锁定。
这也正如王彦辉所强调的:“最好的竞争力,一定来自 生态。”
一个典型行业缩影
值得注意的是,凭借起步早的优势,火山多模态数据湖已经在具身智能和自动驾驶行业积累了大量的客户案例与实践。
以智能驾驶为例,这是最早落地的重要场景之一。摄像头采集的图像、激光雷达点云、行车路线等多模态数据正以前所未有的速度涌现。这类数据不仅规模庞大、形式多样,而且对实时处理提出了极高要求。
一家国内知名汽车企业在建设智驾系统时,就曾遇到这样的问题:单辆测试车每天产生数 TB 数据,量产后规模将飙升至 EB 级。如何在降低存储成本的同时保证高效检索?如何在单机实验与大规模生产间平滑切换?如何让海量非结构化数据真正释放价值?这些都成为横亘在他们面前的挑战。
火山引擎多模态数据湖的引入,给出了答案。它支持在动态标注场景中灵活新增特征,无需重写历史数据集,大幅节省存储资源;其透明压缩机制让点云数据压缩率达到 70%,显著缓解了网络带宽压力;在模型训练环节,通过轻量级调度和列级读取,有效避免 IO 放大,使 GPU 利用率从不足 60% 提升至 90% 以上。
落地效果同样显著:客户在真实场景中实现了 EB 级数据三倍处理效率提升,模型训练交付速度加快 40%,整体研发迭代节奏随之提速。更重要的是,这套体系帮助企业真正完成了从“能跑起来”到“跑得高效、用得轻松”的转变。
事实上,自动驾驶只是火山引擎多模态数据湖落地的一个起点。随着多模态数据在 AI 产业中的爆发式增长,这一体系正在展现出更广泛的应用潜力。未来,它将在更多行业场景中发挥作用:在医疗影像领域,能够统一管理 CT、MRI 影像与病历文本,助力辅助诊断与新药研发;在工业制造中,可以处理来自传感器、视频监控和日志的多模态数据,实现预测性维护与质量检测;在文娱内容生产中,则能组织图像、视频与音频素材,为 AIGC 创作提供高效的训练数据底座。
这些多模态应用场景的共同点在于数据规模庞大、类型复杂、需要实时处理与反馈。火山引擎多模态数据湖的价值就在于此:它不仅解决了这些场景下 AI 使用者的痛点,也正在成为 AI 时代通用的数据基础设施。
活动推荐
10 月 16 日 14:00, 诚邀您参与 AI 创新巡展·武汉站 Data+AI 闭门会!现场重磅发布:Data Agent 新能力与《2025 数据智能体实践指南》,并分享多模态数据湖技术栈与企业可复制案例。席位有限,锁定名额,与行业大咖共探 Data+AI 落地新路径!点击链接立刻报名~





