

谷歌的研究人员发布了AudioPaLM,这是一个大语言模型(LLM),可以通过语音传输执行文本转语音(TTS)、自动语音识别(ASR)和语音到语音翻译(S2ST)。AudioPaLM 是基于PaLM-2 LLM的,在翻译基准测试上优于OpenAI的Whisper。
AudioPaLM 是一个基于 Transformer 的纯解码器模型,它将文本和音频输入组合成单个嵌入表示。与使用离散 ASR、机器翻译(MT)和 TTS 模型等级联的传统 S2ST 模型不同,AudioPaLM 可以保留声学特征,例如说话者的声音。AudioPaLM 在 S2ST 和 ASR 基准测试中取得了最先进的成绩,并且还展示了零样本能力,对训练数据中不存在的输入和目标组合执行 ASR。在FLEURS数据集上进行评估时,AudioPaLM 在 ASR 任务上“显著”优于 OpenAI 的 Whisper。
InfoQ 最近报道了其他几个多语言人工智能语音模型。2022 年,OpenAI发布了Whisper,这是一个基于 Transformer 的编码器/解码器 ASR 模型,可以转录和翻译 97 种不同语言的语音音频。今年早些时候,Meta发布了MMS,这是一个基于 wav2vec 的模型,可以用 1100 多种语言进行 ASR 和 TTS。
与这些相比,AudioPaLM 是一个基于 Transformer 的纯解码器模型。它是基于预训练的 PaLM-2 的。然后,将模型的标记字典扩展为包括声学标记,声学标记表示音频波形的短片段。它们被映射到与原始模型中文本标记相同的嵌入空间中。然后,模型的输入可以包括音频和文本。文本输入包括任务的简短描述,例如“[ASR 意大利语]”。当模型的输出被解码时,可以使用AudioLM模型将声学标记转换回音频波形。
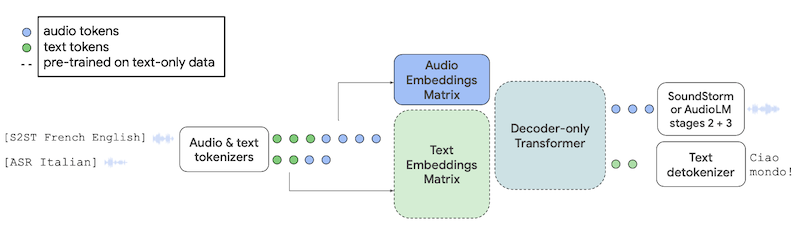
AudioPaLM 的架构图。图片来源:https://google-research.github.io/seanet/audiopalm/examples/
AudioPaLM 接受了来自 100 多种语言的数千小时的音频数据训练。它在多个基准上进行了评估,包括CoVoST2(AST)、CVSS(S2ST)和VoxPopuli(ASR)。它在 AST 和 S2ST 上的表现优于基线模型,在 ASR 上具有“竞争力”。在使用FLEURS基准的零样本 AST 中,AudioPaLM“显著”优于 Whisper。它在 ASR 任务上也优于 Whisper,Whisper 接受过 ASR 任务所涉及的语言的训练,而 AudioPaLM 没有。
研究人员还评估了 AudioPaLM 的音频生成质量,特别是在 S2ST 期间保留原始说话者的声音方面。他们结合“客观指标和主观评估研究”将其性能与基线模型进行比较,发现它“显著”优于基线。在他们的论文中,谷歌团队指出,需要更好的基准来衡量音频生成的质量:
与文本相比,生成文本/音频任务的既定基准集的丰富性还不够成熟。这项工作主要集中在语音识别和语音翻译,它们的基准比较成熟。为生成音频任务建立更多的基准和指标将有助于进一步加快该研究。
一些用户在 Hacker News 的帖子中讨论了AudioPaLM。在回答关于 LLM 翻译准确性的问题时,鉴于其会“产生幻觉”的倾向,一位用户表示,对于像 AudioPaLM 这样最先进的模型,幻觉“几乎不存在”。关于 AudioPaLM 的翻译,另一位用户观察到:
令人印象深刻的是,它将“Morgenstund hat Gold imMund”(早晨口中含金子)翻译成了相应的英语表达“早起的鸟儿有虫吃”,而不是直译。
AudioPaLM输出的若干示例可以在网上找到。
原文链接:
https://www.infoq.com/news/2023/07/google-audiopalm/

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论