
我一直在尝试理解最新的 AI 编程流行语:规范驱动开发(SDD)。我查看了三个自称是 SDD 的工具,并试图弄清楚它们的含义。
定义
像许多在这个快节奏领域中出现的新兴术语一样,“规范驱动开发”(SDD)的定义仍在变化。以下是我根据迄今为止的使用情况所能收集到的信息:规范驱动开发意味着在用 AI 编写代码之前先编写一个“规范”(“文档优先”)。规范成为人类和 AI 的真相来源。
GitHub:“在这个新世界中,维护软件意味着发展规范。……开发的通用语言转移到了更高的层次,代码是最后一英里的解决方案。”
Tessl:“一种开发方法,其中规范——而不是代码——是主要的产物。规范用结构化、可测试的语言描述意图,Agent 负责生成代码以匹配它们。”
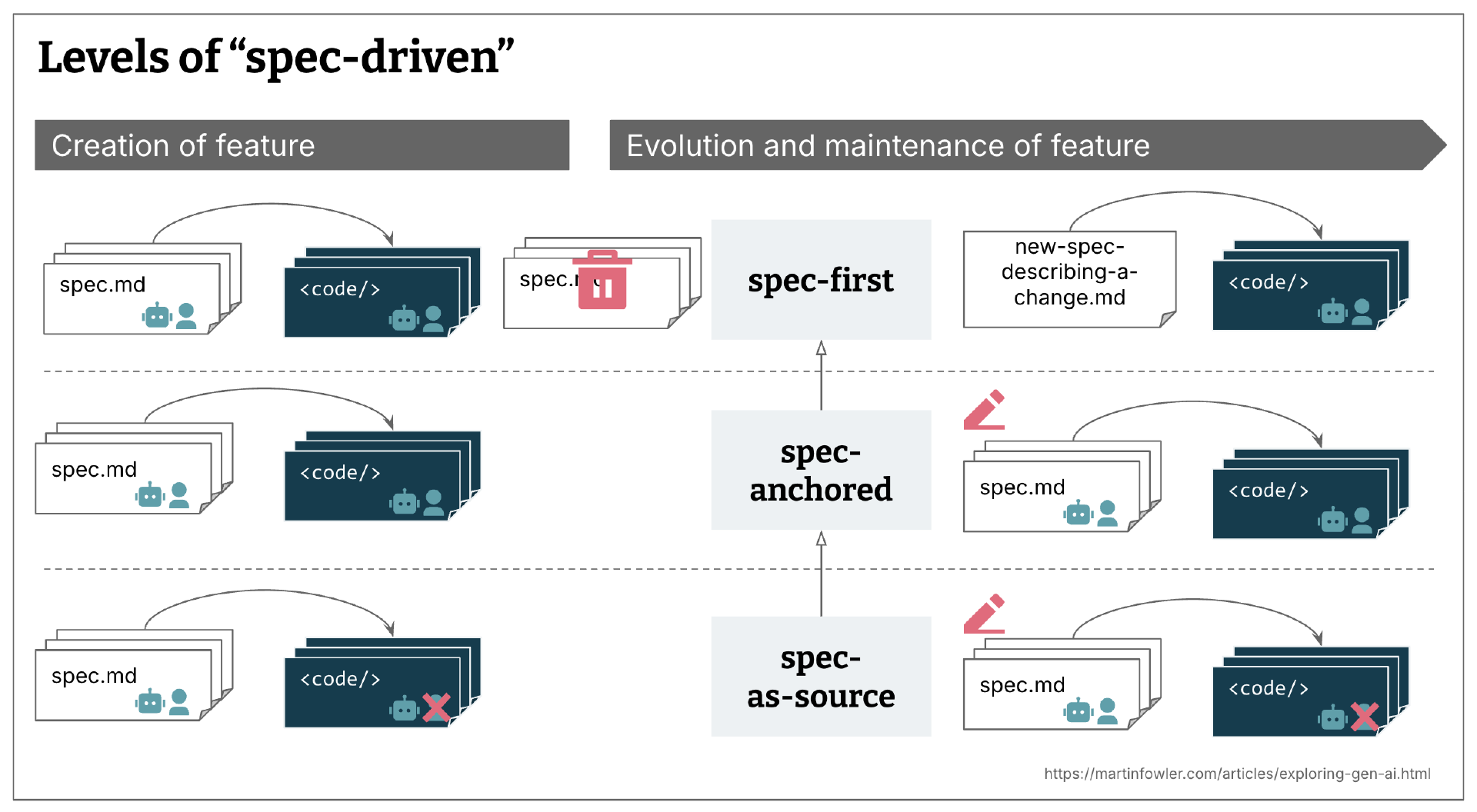
在查看了这个术语的使用情况和一些声称正在实现 SDD 的工具之后,在我看来,实际上,SDD 有多个实现层次:
规范优先:首先编写一个经过深思熟虑的规范,然后将其用于当前任务的 AI 辅助开发工作流。
规范锚定:即使在任务完成后,规范也会被保留,以继续用于相应功能的演变和维护。
规范作为源:随着时间的推移,规范成为主要的源文件,人类只编辑规范,从不接触代码。
我找到的所有 SDD 方法和定义都是规范优先的,但并非所有都努力做到规范锚定或规范为源。而且随着时间变化,规范维护策略往往是模糊的,或者完全开放的。
规范是什么?
当然,在定义方面的关键问题是:规范是什么?似乎没有通用的定义,我见过的最一致的定义是将规范与“产品需求文档”对比。
目前这个术语包含的东西太多了,以下是我尝试定义规范的尝试:
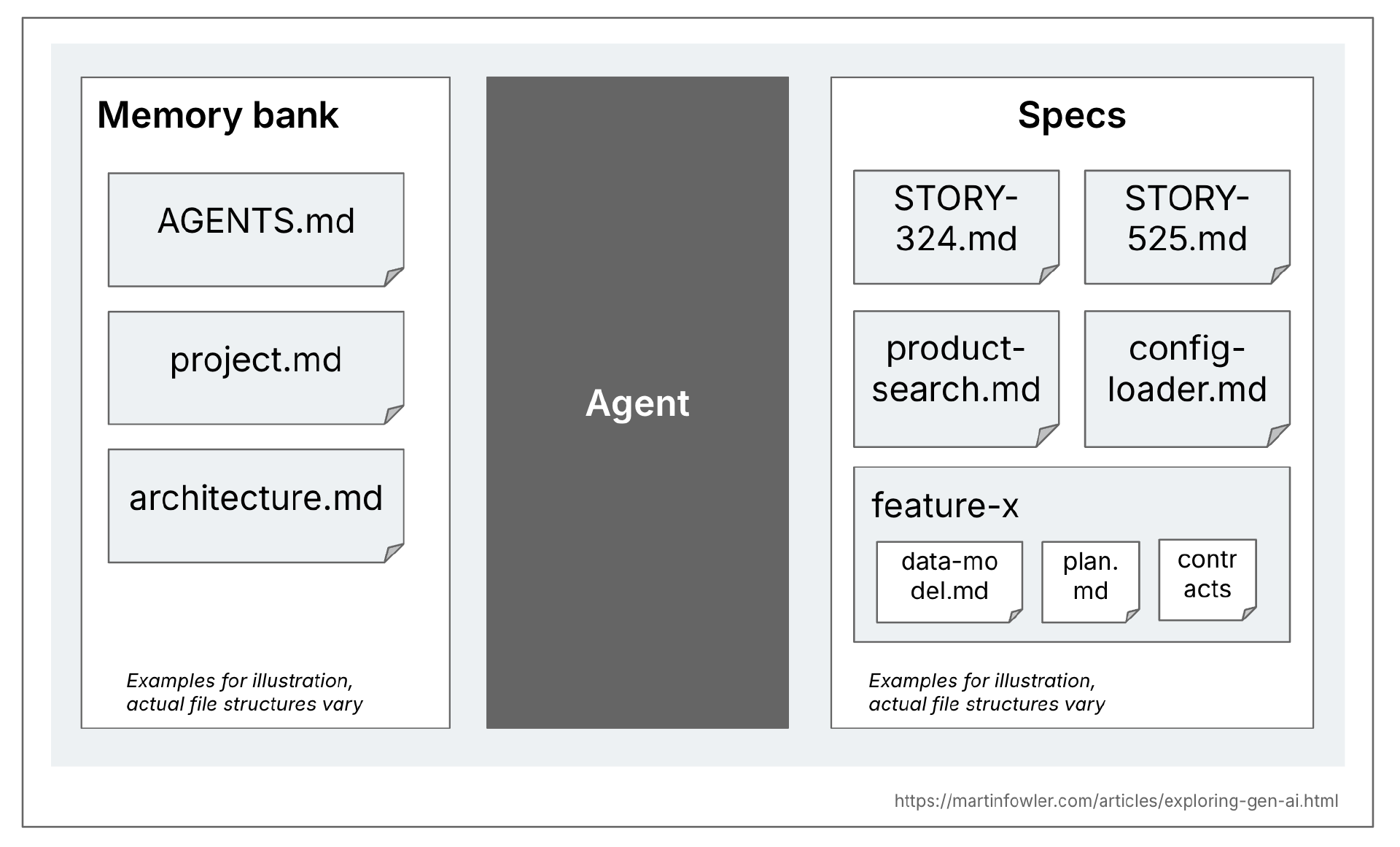
规范是一个结构化、面向行为的产物——或一组相关的产物——用自然语言编写,表达软件功能,并作为 AI 编程 Agent 的指导。每种规范驱动开发的定义都定义了它们对规范结构、细节水平以及这些产物在项目中的组织方式的方法。
我认为规范和代码库的一般性上下文文档之间有一个明显区别。那些一般性上下文是规则文件,或者是产品和代码库的高级描述。一些工具称这个上下文为记忆库,所以我会在这里用这个说法。这些文件与代码库中的所有 AI 编程会话相关,而规范只与实际创建或更改特定功能的任务相关。
评估 SDD 工具的挑战
事实证明,以接近实际使用的方式评估 SDD 工具和方法非常耗时。你必须用不同大小的问题、绿地、棕地来试用它们,并真正花时间审查和修订中间产物,而不仅仅是粗略一瞥。因为正如 GitHub 关于 spec-kit 的博客文章所说:“关键是,你的角色不仅仅是引导,而是验证。在每个阶段,你都要反思和提炼。”
我尝试的三个工具中,有两个的情况是,似乎将它们引入现有代码库的工作量更大,因此更难评估它们对棕地代码库的有用性。在我听到人们在“真实”代码库上使用它们一段时间的使用报告之前,我仍然有很多关于这在现实生活中如何运作的开放问题。
话虽如此——我们还是来深入了解这三个工具吧。我将首先分享它们如何工作的描述(或者更确切地说,我认为它们是如何工作的),并将我的观察和问题留到结尾。请注意,这些工具正在快速发展,所以自九月份我使用它们以来,它们可能已经发生了变化。
Kiro
Kiro 是我尝试过的三个工具中最简单(或最轻量级)的一个。它似乎主要是以规范为先,我找到的所有示例都使用它来完成一个任务或用户故事,没有提到如何在多个任务中随时间推移怎样使用规范锚定的需求文档。
工作流:需求 → 设计 → 任务
每个工作流步骤都由一个 Markdown 文档表示,Kiro 在其基于 VS Code 的分发中指导你完成这 3 个工作流步骤。
需求:以需求列表的形式结构化,每个需求代表一个“用户故事”(以“作为一个…”的格式),并带有验收标准(以“给定… 当… 那么…”的格式)
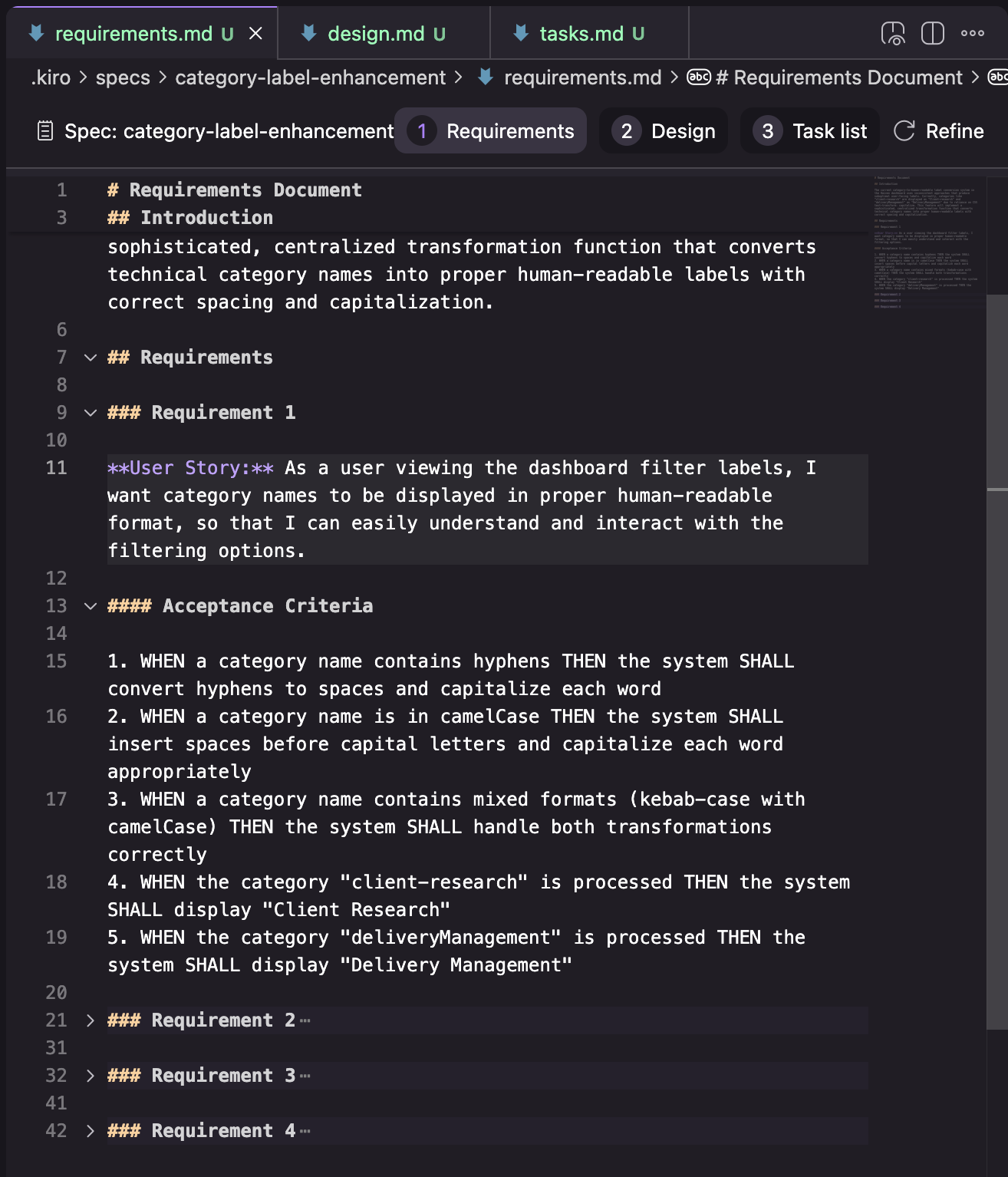
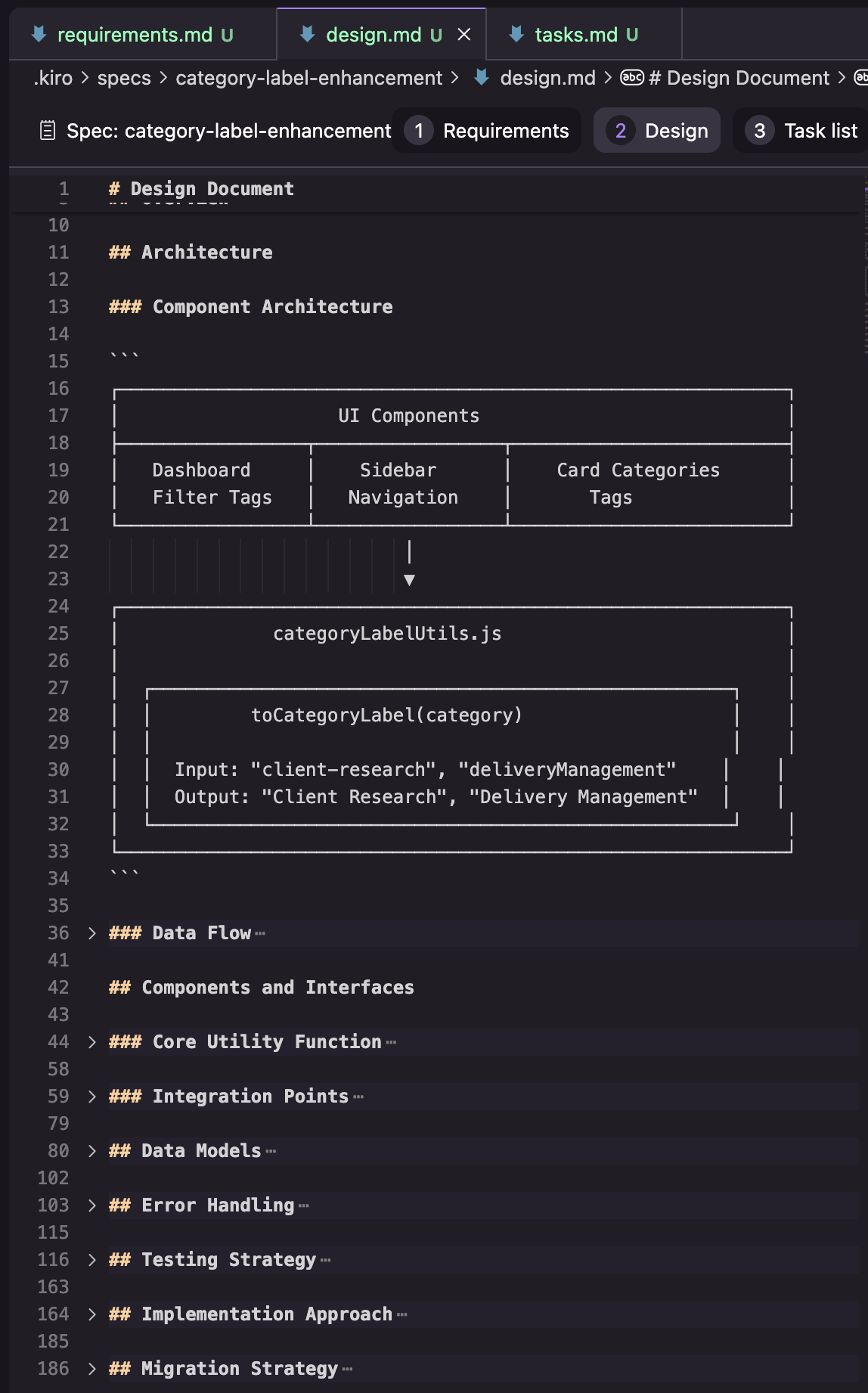
设计:在我的尝试中,设计文档由下图所示的部分组成。这里只有我尝试中的一个结果,所以我不确定这是一个一致的结构,还是根据任务的不同而变化。
任务:一个任务列表,追溯到需求编号,并得到一些额外的 UI 元素来逐个运行任务,并按任务审查更改。
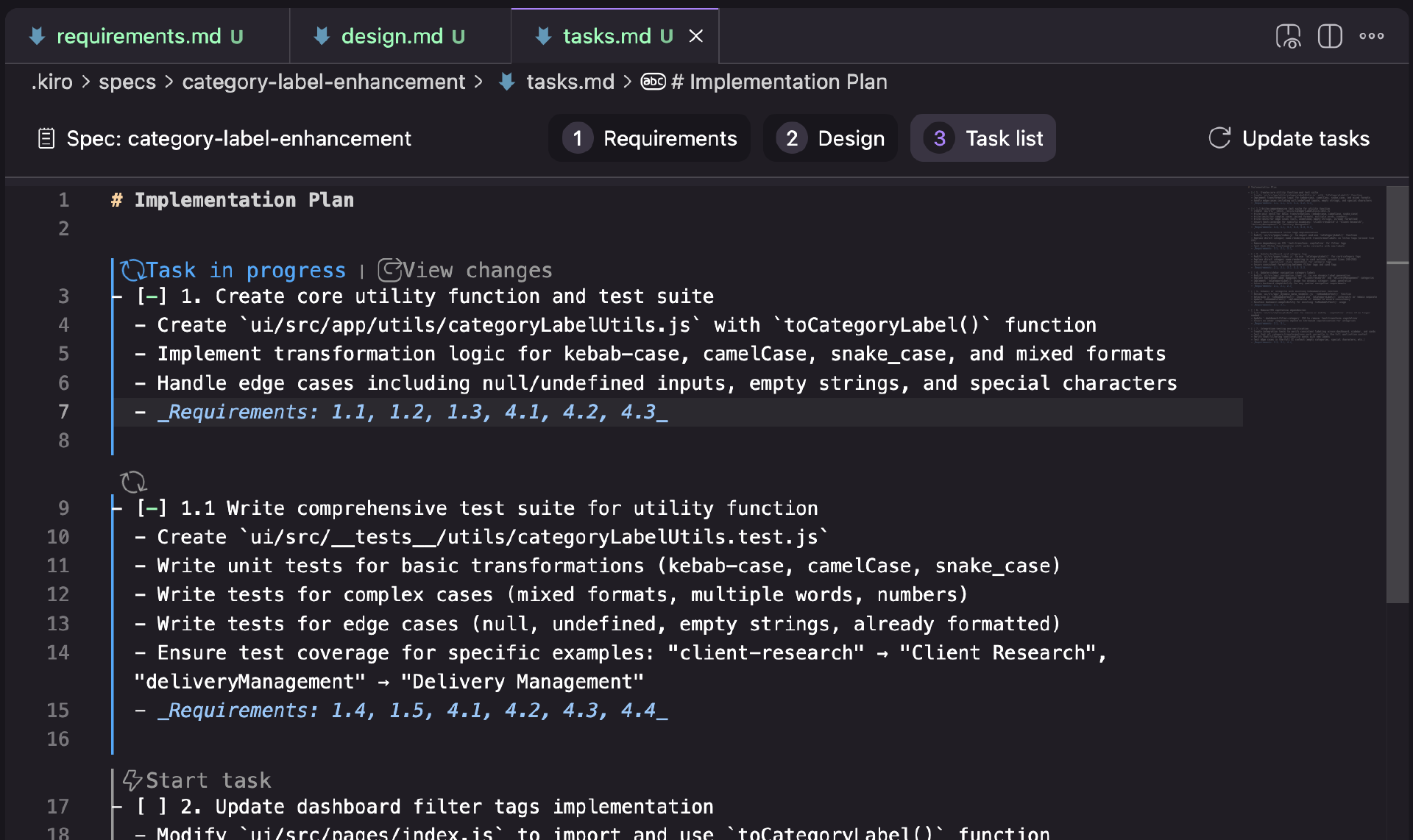
Kiro 还有一个记忆库的概念,他们称之为“指导”。其内容是灵活的,他们的工作流似乎不依赖于任何特定文件的存在(我发现指导部分之前就尝试用了一下)。当你要求 Kiro 生成指导文件时,默认拓扑结构是 product.md、structure.md、tech.md。
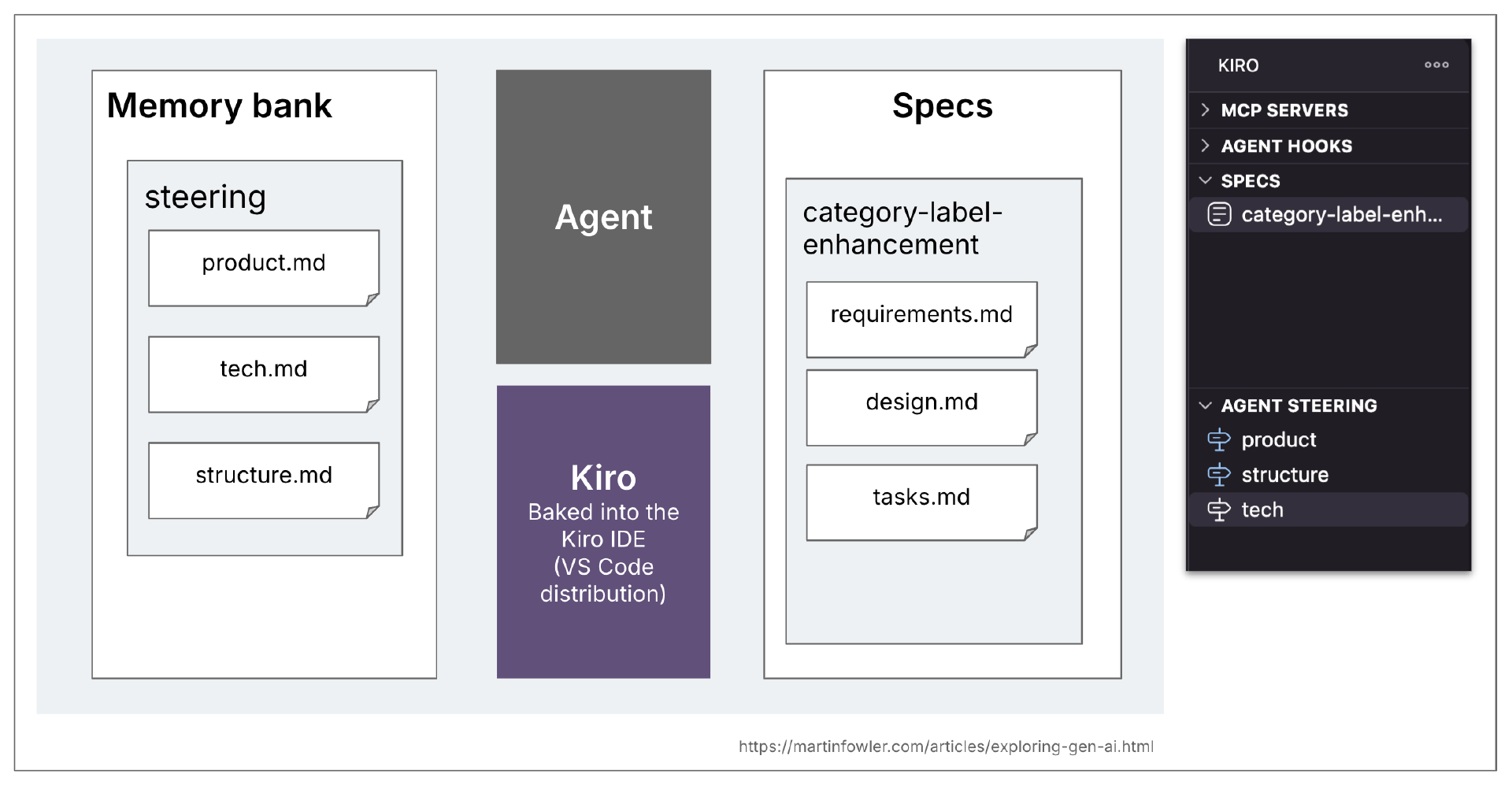
Spec-kit
Spec-kit 是 GitHub 的 SDD 版本。它作为一个 CLI 分发,可以为广泛的常见编程助手创建工作区设置。一旦设置好这个结构,你可以通过编程助手中的斜杠命令与 spec-kit 交互。因为所有的工件都直接放入你的工作区,这是这里讨论的三个工具中最可定制的。
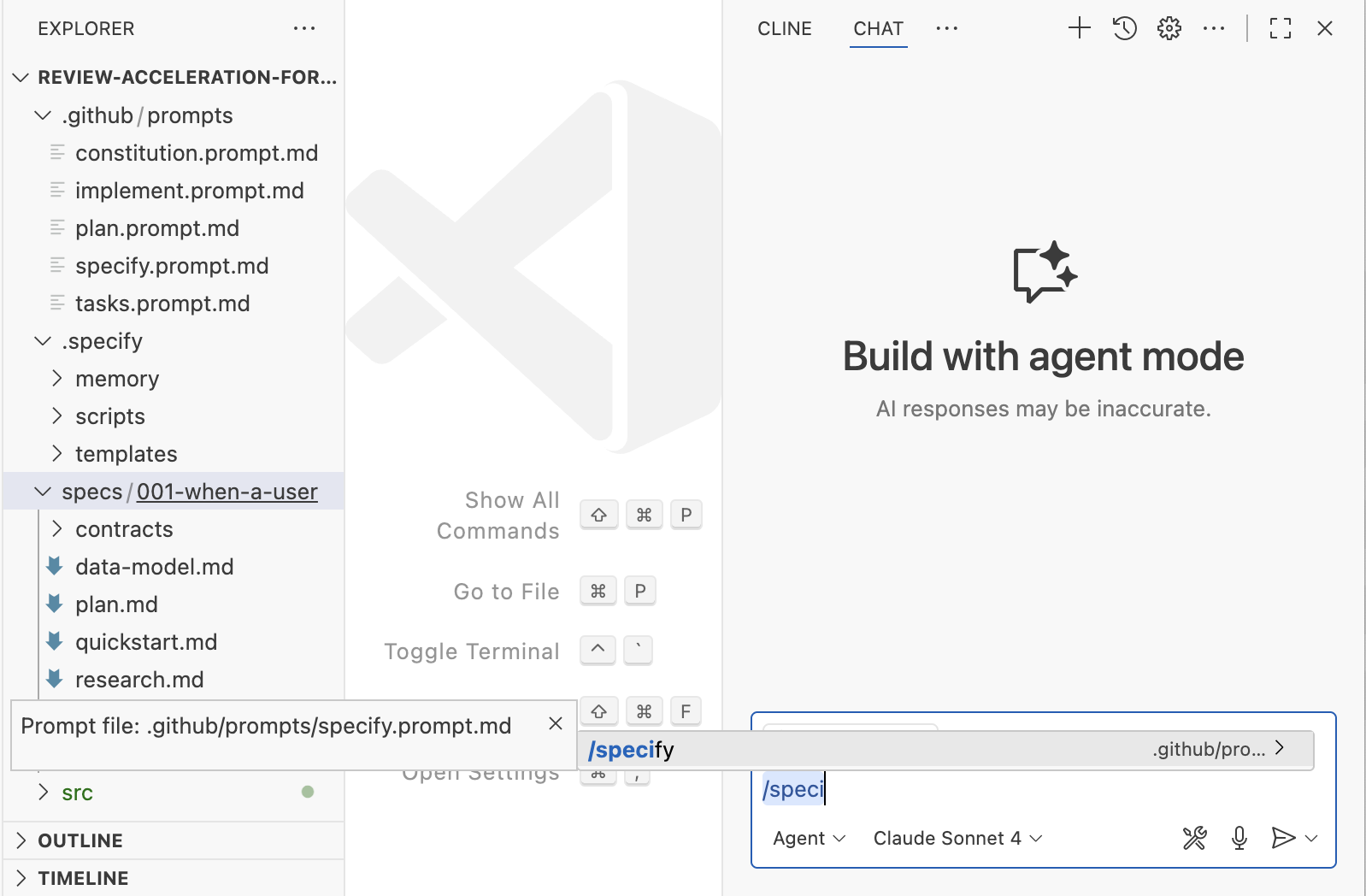
工作流:宪法 → 𝄆 指定 → 计划 → 任务 𝄇
Spec-kit 的记忆库概念是规范驱动方法的先决条件。他们称之为宪法。宪法应该包含“不可变”的高层原则,应该始终应用于每个更改。它基本上是一个非常强大的规则文件,被工作流大量使用。
在每个工作流步骤(指定、计划、任务)中,spec-kit 通过 bash 脚本和一些模板的帮助实例化一组文件和提示。然后工作流在文件中大量使用清单,以跟踪必要的用户澄清、宪法违规、研究任务等。它们就像每个工作流步骤的“完成定义”(尽管由 AI 解释,所以没有 100%的保证它们会被尊重)。
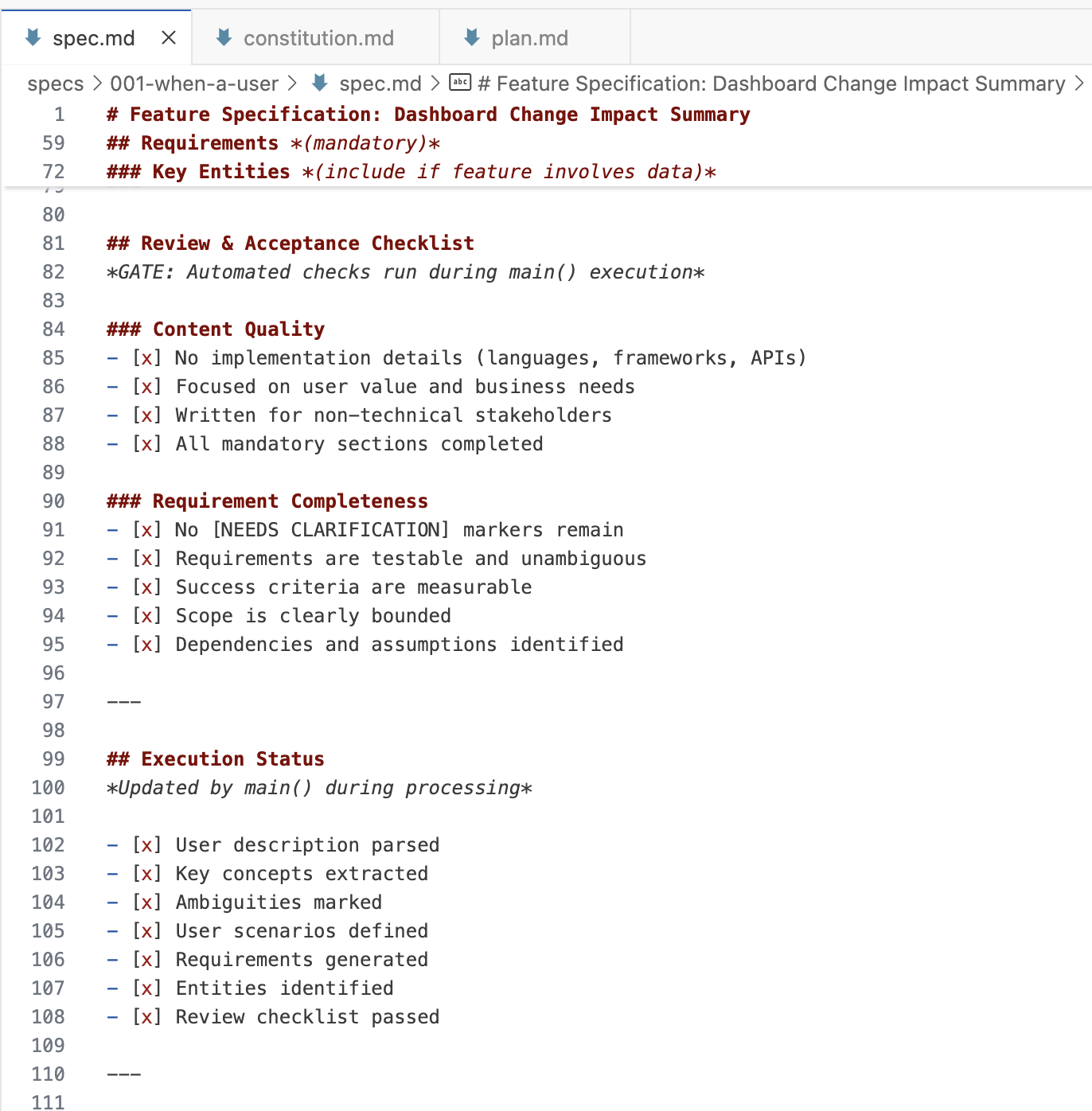
下面是一个概述,说明了我在 spec-kit 中看到的文件拓扑结构。注意一个规范由许多文件组成。
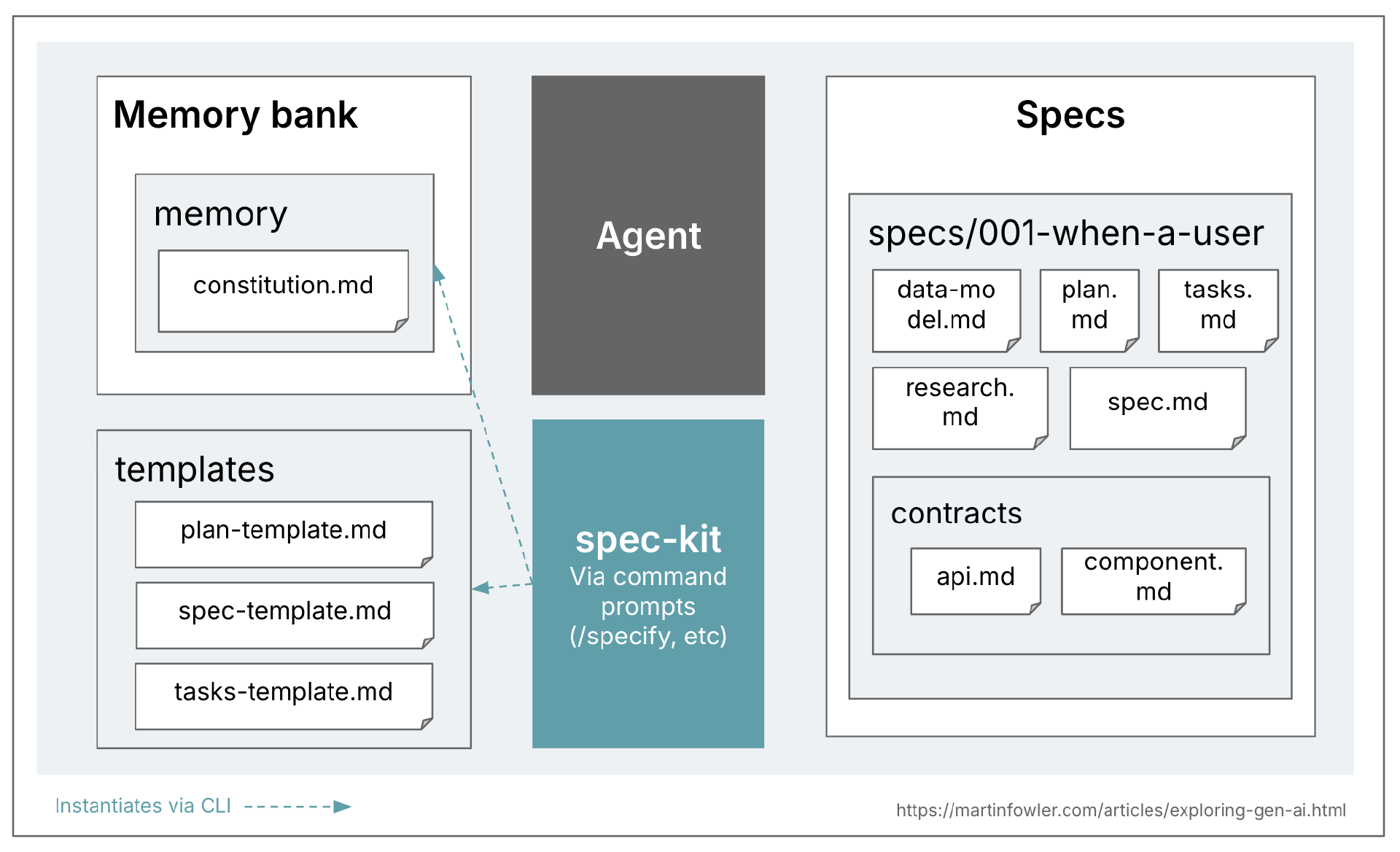
乍一看,GitHub 似乎希望做一个规范锚定的方法(“这就是为什么我们正在重新思考规范——不是作为静态文档,而是作为随着项目发展而演变的活生生的、可执行的工件。规范成为共享的真相来源。当某事没有意义时,你回到规范;当项目变得复杂时,你完善它;当任务感觉太大时,你将它们分解。”)。然而,spec-kit 为每个创建的规范创建一个分支,这似乎表明他们将规范视为一个变更请求的生命周期内的活生生的工件,而不是一个功能的生命周期。社区里的一个讨论帖正在讨论这种混淆。这让我想到 spec-kit 仍然是我所说的规范优先,而不是随时间规范锚定的做法。
Tessl 框架
(仍在非公开测试阶段)
像 spec-kit 一样,Tessl 框架以命令行界面(CLI)的形式分发,可以为各种编程助手创建所有工作区和配置结构。CLI 命令还充当 MCP 服务器。
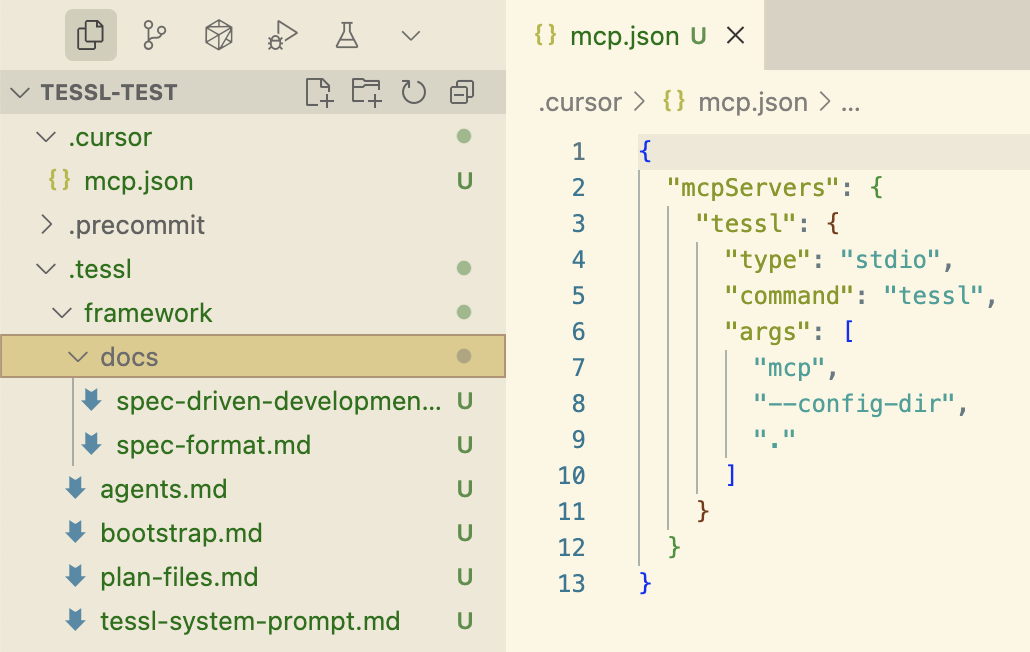
Tessl 是这三个工具中唯一明确追求以规范为锚的方法,甚至探索了规范即源的系统设计文档(SDD)级别。Tessl 规范可以作为被维护和编辑的主要工件,代码甚至在顶部用注释标记为//从规范生成 - 请勿编辑。目前规范和代码文件之间是 1:1 的映射,即一个规范转换为代码库中的一个文件。但 Tessl 仍在测试阶段,他们正在尝试不同版本,所以我可以想象这种方法也可以在规范映射到具有多个文件的代码组件的级别上采用。alpha 产品将支持哪些能力还有待观察。(Tessl 团队本身将他们的框架视为比他们当前的公共产品,Tessl 注册表,更未来的东西。)
这里有一个规范的例子,我让 Tessl CLI 逆向工程(tessl 文档 --code ...js)从一个现有代码库中的 JavaScript 文件:
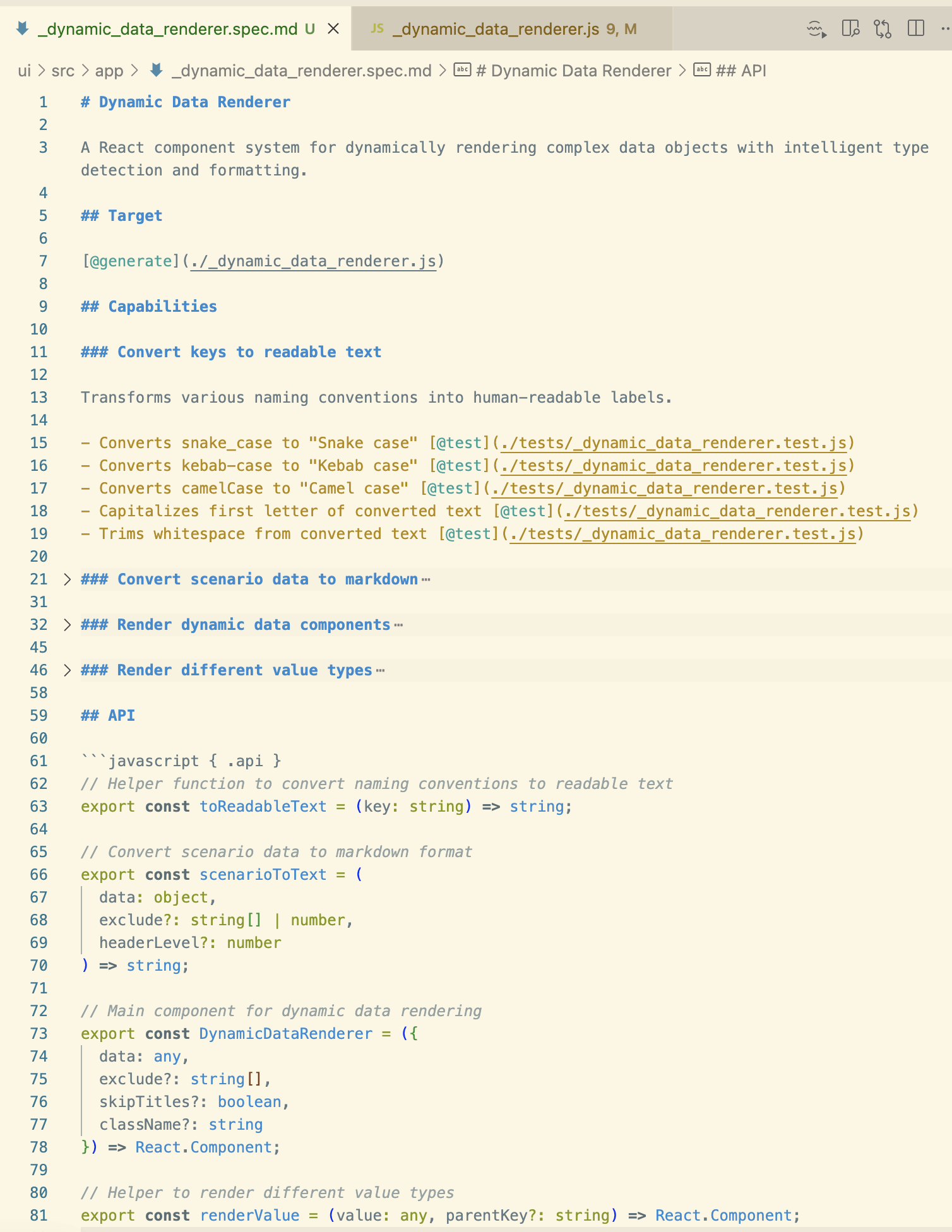
像 @generate 或 @test 这样的标签似乎告诉 Tessl 要生成什么。API 部分显示了在规范中定义至少暴露给代码库其他部分的接口的想法,大概是为了确保这些更关键的部分生成的组件完全在维护者的控制之下。运行 tessl build 为此规范生成相应的 JavaScript 代码文件。
将规范作为源代码放在相当低的抽象层次,也就是每个代码文件中,可能减少了大型语言模型(LLM)必须执行的步骤和解释,因此减少了错误的机会。即使在这个低抽象层次,我也看到了非确定性的影响——当我多次从同一个规范生成代码时就能看出来。迭代规范并使其越来越具体以增加代码生成的可重复性是一个有趣的练习。这个过程让我想起了编写一个明确和完整的规范的一些陷阱和挑战。
观察和问题
这三个工具都自称为规范驱动开发(SDD)的实现,但它们彼此之间相当不同。所以这是在谈论 SDD 时首先要记住的,它不仅仅是一件事。
一个适用于所有规模的工作流?
Kiro 和 spec-kit 各自提供了一个有偏见的工作流,但我相当确定它们都不适合大多数现实编程问题。特别是,我不太清楚它们将如何满足足够多的不同问题规模的需求,这样才能具有普遍适用性。
当我问 Kiro 修复一个小错误(这是我过去用来尝试 Codex 的同一个错误)时,很快就清楚了,这个工作流就像是用大锤砸坚果。需求文档将这个小错误变成了 4 个“用户故事”,总共有 16 个验收标准,包括像这样的“用户故事:作为一个开发者,我希望转换函数能够优雅地处理边缘情况,以便在引入新的类别格式时系统保持健壮。”
当我使用 spec-kit 时,我也遇到了类似的挑战,我不太确定应该用它来解决多大的问题。可用的教程通常讲的是从头开始创建应用程序的部分,因为这对于教程来说最容易。我最终尝试的一个用例是我过去团队中用过的 3-5 点故事。该功能依赖于已经存在的大量代码,它应该构建一个概述模态,总结了来自现有仪表板的大量数据。考虑到 spec-kit 所采取的步骤数量,以及它为我创建的 markdown 文件数量(以便我进行审查),对于问题的大小来说这还是感觉小题大做。这是一个比 Kiro 的问题更大的问题,但也是一个更复杂的工作流。我甚至没有完成完整的实现,但我认为在我运行和审查 spec-kit 结果的相同时间内,我可以使用“纯”AI 辅助编程实现该功能,我会感到更有控制感。
一个有效的 SDD 工具至少需要为不同大小和类型的变更提供几种不同核心工作流的灵活性。
审查 Markdown 而不是代码?
正如你在上述工具描述中看到的,spec-kit 为我创建了很多 Markdown 文件供我审查。它们彼此之间内容交错,还与已经存在的代码重复。有些甚至包含了代码。总的来说,它们只是非常冗长且乏味,难以审查。在 Kiro 中,这稍微容易一些,因为你只得到 3 个文件,而且更容易理解“需求>设计>任务”的心智模型。然而,正如前文提到的,Kiro 对于我要求它修复的小错误来说也太过冗长了。
老实说,我宁愿审查代码,而不是所有这些 Markdown 文件。一个有效的 SDD 工具必须提供非常好的规范审查体验。
控制的错觉?
即使有了所有这些文件、模板、提示、工作流和清单,我也经常看到 Agent 最终没有遵循所有指令。是的,上下文窗口现在更大了,这经常被提及为规范驱动开发的一种推动因素。但仅仅因为窗口更大,并不意味着 AI 会正确地捕捉到其中的所有内容。
例如:Spec-kit 在规划过程中的某个研究步骤里,它对现有代码和已有内容进行了很多研究,这很好,因为我要求它添加一个基于现有代码的功能。但最终,Agent 忽略了这些现有类的描述,它只是将它们视为新的规范,并再次生成它们,创建了重复项。我不仅看到了忽略指令的例子,我还看到 Agent 因为过于积极地遵循指令而做得过头(例如宪法条款之一)。
过去的经验已经表明,我们保持对正在构建的内容的控制的最佳方式是一系列小的、迭代的步骤,所以我非常怀疑大量的前期规范设计是否是个好主意,特别是当它过于冗长时。一个有效的 SDD 工具必须迎合迭代方法,但小的工作包几乎似乎与 SDD 的理念相悖。
如何有效地将功能规范与技术规范分开?
在 SDD 中,有意识地区分功能规范和技术实现是一个常见的想法。我猜背后的愿景是,最终,我们可以有 AI 填充所有的解决方案和细节,并在相同的规范下切换到不同的技术栈。
实际上,当我尝试 spec-kit 时,我经常对何时停留在功能层面,何时添加技术细节感到困惑。教程和文档在这方面也不太一致,似乎对“纯粹功能”的真正含义有不同的解释。当我回想起在我的职业生涯中读过的许多用户故事,它们没有正确地区分需求和实现,我不认为我们作为一个行业在这方面有很好的记录。
目标用户是谁?
许多规范驱动开发工具的演示和教程包括定义产品和功能目标,它们甚至包含了“用户故事”这样的术语。这里的想法可能是使用 AI 作为跨技能的推动者,让开发人员更多地参与需求分析?或者让开发人员在这种工作流中与产品人员配对?这些都没有明确说明,而是默认开发人员会进行所有这些分析。
在这种情况下,我会再次问自己,SDD 适用于哪种问题大小和类型?可能不是那些仍然非常模糊的大型功能?因为那肯定需要更多的专业产品和需求技能,以及研究和利益相关者参与等许多其他步骤。
规范锚定和规范作为源:我们是从过去学习吗?
虽然许多人将 SDD 与 TDD 或 BDD 类比,但我认为对于规范作为源来说,另一个重要的类比是 MDD(模型驱动开发)。在我的职业生涯初期,我参与了一些大量使用 MDD 的项目,当我尝试 Tessl 框架时,我不断地回想起这一点。MDD 中的模型基本上是规范,尽管不是自然语言,而是用例如自定义 UML 或文本 DSL 表达。我们构建了自定义代码生成器,将这些规范转换为代码。
我过去经验中的一个结构化、可解析规范 DSL 的例子,主要是从记忆中重建的。屏幕“写消息”实例化 InputScreen { … } 说明了诸如对领域模型字段的引用、从其他屏幕继承以重用模式、导航逻辑等。
最终,模型驱动开发(MDD)从未在商业应用中起飞,它处于一个尴尬的抽象层次,只是创造了太多的开销和限制。但是大型语言模型(LLMs)带走了 MDD 的一些开销和限制,因此有了新的希望,我们现在可以最终专注于编写规范,并从中生成代码。有了 LLMs,我们不再受预定义且可解析的规范语言的限制,我们也不必构建复杂的代码生成器。当然,为此付出的代价是 LLMs 的非确定性。而且可解析结构也有我们现在正在失去的优点:我们可以为规范作者提供大量的工具支持,以编写有效、完整和一致的规范。我想知道,规范即源代码,甚至规范锚定,是否最终会同时具有 MDD 和 LLMs 的缺点:不灵活和非确定性。
需要明确的是,我并不是怀念过去的 MDD 经历,并说“我们不妨把它带回来”。但我们应该回顾过去的从规范到代码的尝试,以便在今天探索规范驱动时从中学习。
结论
在我使用 AI 辅助编程的个人经验中,我也常常花时间精心制作某种形式的规范,并先提供给编程 Agent。因此,规范优先的一般原则在许多情况下绝对是有价值的,构建规范的不同方法非常受欢迎。它们是我目前从实践者那里听到的最常问的问题之一:“我如何构建我的记忆库?”,“我如何为 AI 编写一个好的规范和设计文档?”。
但是“规范驱动开发”这个术语还没有很好地定义,它在语义上已经扩散。我甚至最近听到人们基本上将“规范”用作“详细提示”的同义词。
关于我尝试过的工具,我在这里列出了关于它们在现实世界中的实用性的许多问题。我想知道它们中的一些是否试图过于字面地用我们现有的工作流来喂养 AI Agent,最终放大了现有的挑战,如审查过载和幻觉。特别是那些创建大量文件的更复杂的方法,我不禁想到德国复合词“Verschlimmbesserung”:我们是否在试图改进的过程中使事情变得更糟?
原文链接:https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html




