
Improbable 团队开源了Thanos,一组通过跨集群联合、跨集群无限存储和全局查询为Prometheus 增加高可用性的组件。
Improbable 部署了一个大型的 Prometheus 来监控他们的几十个 Kubernetes 集群。默认的 Prometheus 设置在查询历史数据、通过单个 API 调用进行跨分布式 Prometheus 服务器查询以及合并多个 Prometheus 数据方面存在困难。
高可用警报和联合部署是Prometheus 现有的高可用特性。在联合部署中,全局Prometheus 服务器可以在其他Prometheus 服务器上聚合数据,这些服务区可能分布在多个数据中心。每台服务器只能看到一部分度量指标。为了处理每个数据中心的负载,可以在一个数据中心内运行多台Prometheus 服务器,并进行水平分片。在分片设置中,从服务器获取数据的子集,并由主服务器对其进行聚合。在查询特定的服务器时,需要查询拼凑数据的特定从服务器。默认情况下,Prometheus 存储15 天的时间序列数据。为了无限期存储数据,Prometheus 提供了一个远程端点,用于将数据写入另一个数据存储区。不过,在使用这种方法时,数据除重是个问题。其他解决方案(如 Cortex )提供了一个远程写入端点和兼容的查询 API,实现可伸缩的长期存储。
Thanos 在每一台 Prometheus 服务器上运行一个边车组件,并提供了一个用于处理 PromQL 查询的中央 Querier 组件,因而在所有服务器之间引入了一个中央查询层。这些组件构成了一个 Thanos 部署,并基于 memberlist gossip 协议实现组件间通信。Querier 可以水平扩展,因为它是无状态的,并且可充当智能逆向代理,将请求转发给边车,汇总它们的响应,并对 PromQL 查询进行评估。
Thanos 通过使用后端的对象存储来解决数据保留问题。Prometheus 在将数据写入磁盘时,边车的 StoreAPI 组件会检测到,并将数据上传到对象存储器中。Store 组件还可以作为一个基于 gossip 协议的检索代理,让 Querier 组件与它进行通信以获取数据。
InfoQ 采访了 Improbable 的软件工程师 Bartłomiej Płotka,了解了更多关于 Thanos 如何执行查询的细节:
在 Thanos 中,查询的评估只在一个地方发生,也就是通过 HTTP 监听 PromQL 查询的地方。来自 Prometheus 2.2.1 的 PromQL 引擎用于评估查询,预测需要获取数据的时间序列和时间范围。我们使用基本的过滤器(基于时间范围和外部标签)过滤掉不会提供所需数据的 StoreAPI(叶子),然后执行剩余的查询。然后将来自不同来源的数据按照时间顺序追加的方式合并在一起。
Querier 组件可以基于用户规模自动调整密度(例如 5 分钟、1 小时或 24 小时)。Thanos 如何确定哪些 API 服务器持有所需的数据?Płotka 解释说:
StoreAPI 会对外公布外部标签及其持有数据的时间范围,所以我们可以对此进行基本过滤。但是,如果没有在查询中指定这些条件,Querier 就会同时查询所有的 StoreAPI 服务器。此外,边车和存储的数据之间可能会有重复的结果,这种情况可能不容易避免。
StoreAPI 组件了解 Prometheus 的数据格式,因此它可以优化查询执行计划,并缓存数据块的特定索引,以对用户查询做出足够快的响应,避免了缓存大量数据的必要。在使用 Thanos 边车的 Prometheus 高可用设置中,是否会有多个边车试图将相同的数据块上传到对象存储的问题?Płotka 回应道:
我们通过为所有 Prometheus+ 边车实例提供唯一的外部标签来解决这个问题。为了表明所有副本都存储相同的数据,它们只有标签是不一样的。例如:
First:
“cluster”: “prod1”
“replica”: “0”
Second:
“cluster”:“prod1”
“replica”: “1”
由于标签集是唯一的,所以不会有什么问题。不过,如果指定了副本,查询层可以在运行时通过“replica”标签进行除重操作。
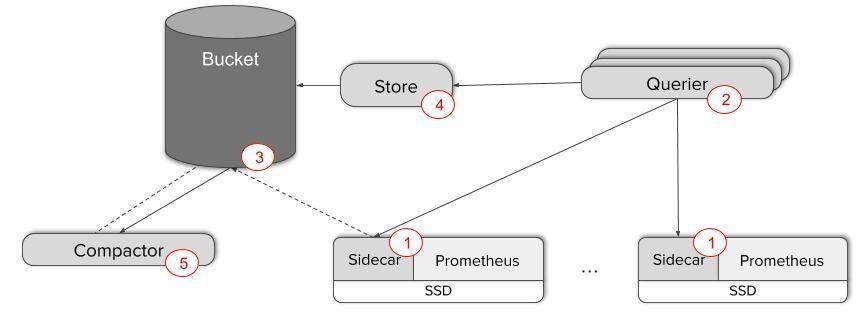
图片来源: https://improbable.io/games/blog/thanos-prometheus-at-scale
Thanos 还提供了时间序列数据的压缩和降采样(downsample)存储。Prometheus 提供了一个内置的压缩模型,现有较小的数据块被重写为较大的数据块,并进行结构重组以提高查询性能。Thanos 在Compactor 组件(作为批次作业运行)中使用了相同的机制,并压缩对象存储数据。Płotka 说,Compactor 也对数据进行降采样,“目前降采样时间间隔不可配置,不过我们选择了一些合理的时间间隔——5 分钟和1 小时”。压缩也是其他时间序列数据库(如 InfluxDB 和 OpenTSDB )的常见功能。
Thanos 采用 Go 开发,托管在 Github 上。我们可以继续在可视化工具(如 Grafana)上使用 Thanos,就像现有的 Prometheus 插件一样,因为 API 是相同的。
查看英文原文: Thanos - a Scalable Prometheus With Unlimited Storage

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论