

深度强化学习(Deep reinforcement learning)利用奖励来推动软件政策朝着目标发展。该技术已被用于模拟社会规范的影响,创造出特别擅长玩游戏的人工智能,并为机器人编写程序,使其能够从恶劣的溢出中恢复过来。尽管强化学习功能多样,它也有一个明显的缺点:效率低下。训练策略需要在模拟的或真实的环境中进行大量的交互——远远超过普通人学习任务的需要。
为了在视频游戏领域有所弥补,谷歌的研究人员最近提出了一种新的算法——模拟策略学习,简称 SimPLe,该算法通过游戏模型学习用于选择动作的质量策略。谷歌在一篇新发表的预印本论文(“Atari 基于模型的强化学习”)和随开源代码一起发布的文档中对此进行了描述。
论文链接:https://arxiv.org/abs/1903.00374
开源代码:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/rl/README.md
根据谷歌官方的介绍:
在高层次上,SimPLe 背后的想法是在学习游戏行为的 world 模型和在模拟游戏环境中使用该模型优化策略(使用无模型强化学习)之间进行交替。该算法的基本原理已经很好地建立起来,并应用于许多最近的基于模型的强化学习方法中。
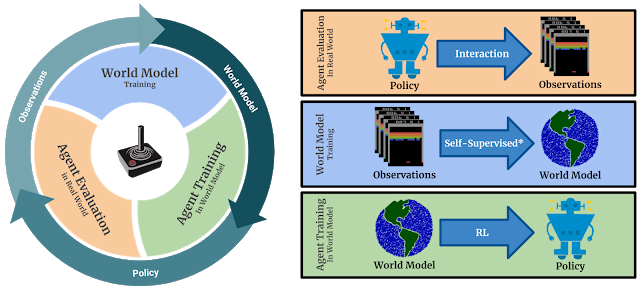
SimPLe 的主循环。1)代理开始与真实环境交互;2)收集的观测结果用于更新当前的 world 模型;3)代理通过在 world 模型内学习来更新策略。
如果成功地训练这样一个模型(如视频预测),一个本质上学会了模拟器的游戏环境,可以用来生成轨迹训练游戏代理的好策略,即选择一个操作序列,这样可以使代理的长期回报最大化。
在每次迭代中,在 world 模型被训练之后,就可以使用这个学习的模拟器来生成滚动(即动作、观察和结果的样本序列),这些滚动被用来使用近似策略优化(PPO)算法来改进游戏策略。滚动的采样从实际的数据集帧开始。由于预测错误通常会随着时间的推移而增加,使长期预测变得非常困难,SimPLe 只使用中等长度的滚动。幸运的是,PPO 算法也可以从其内部价值函数中学习动作和奖励之间的长期效果,因此有限长度的滚动对于像《highway》这样奖励稀疏的游戏来说也是足够的。
从效率方面来说,衡量成功的一个标准是证明该模型是高效的。为此,谷歌的研发人员在与环境进行了 10 万次交互之后评估了策略的输出,将 SimPLe 与两种最先进的无模型 RL 方法 Rainbow 和 PPO 进行了比较。在大多数情况下,SimPLe 的样本效率比其他方法高出两倍以上。
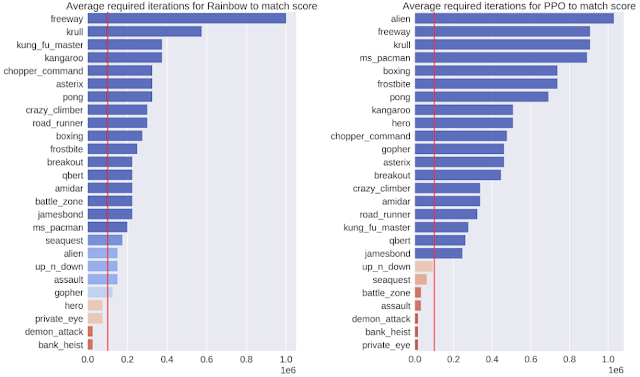
相应的无模型算法(左 - Rainbow;右 - PPO)所需的交互次数与 SimPLe 训练方法获得的得分相匹配。红线表示 SimPLe 使用的交互次数。
然而,SimPLe 并不总是完美的。最常见的故障是:world 模型不能准确地捕获或预测体积很小但相关度很高的对象。比如某些训练中,由于游戏中子弹的体积太小以至于几乎很难被模型捕捉到。
谷歌的研究人员认为:“基于模型的强化学习方法的主要前景是在交互成本高、速度慢或需要人工标记的环境中,例如许多机器人任务中。在这样的环境下,学习的模拟器可以更好地理解代理的环境,并可以为更多的任务强化学习提供新的,更好的和更快的方法。虽然 SimPLe 还没有达到标准无模型 RL 方法的性能,但它的效率要高得多,我们期望未来的工作能够进一步提高基于模型的性能。”
原文链接:
https://ai.googleblog.com/2019/03/simulated-policy-learning-in-video.html

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论