写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 cvat 频道下的 9 篇内容

减轻数据注释器和数据科学家的负担

Amazon SageMaker可以帮助开发人员和数据科学家快速准备构建、训练和部署机器学习(Amazon ML)模型的完全托管的云服务。

创建计算机视觉数据库的5个最好用的标注工具

数据标注行业流淌这么一句话:“有多少智能,就有多少人工”。金字塔的基础。Net,涵盖了通用场景。但在实际的业务通常碰到某些细分领域没有开放数据集,比如服装的类型和风格,这就要求自己构建训练数据集,或自力更生,或临时雇用外包人员(自己提供工具),甚至全权委托给专业标注公司(无需提供标注工具,成本高)。

编者按:随着大语言模型在自然语言处理领域的广泛应用,如何从人类反馈进行强化学习(RLHF)已成为一个重要的技术挑战。并且RLHF需要大量高质量的人工数据标注,这是一个非常费力的过程。
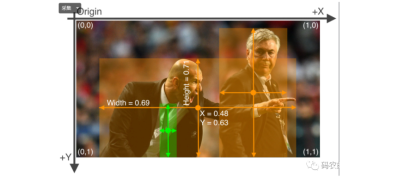
在深度学习中,数据是非常重要的,而自己制作训练数据集是模型训练的第一步,之前给大家介绍过目标检测和语义分割中打标签工具labelimg和labelme两个工具的使用教程。


本文主要介绍 One-YOLOv5 使用的数据集格式以及如何制作一个可以获得更好训练效果的数据集。本节教程的数据集标准部分翻译了 Ultralytics/YOLOv5 wiki 中对数据集相关的描述(https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results) 。
基于视觉模型的目标检测技术在自动化测试中具有广泛的应用潜力,尤其是在需要模拟人类视觉判断的场景中。目标检测技术可以自动识别、定位和分类图像或视频中的目标对象,从而提升测试效率、准确性和覆盖范围。以下是其在自动化测试中的具体应用场景和优势:


KubeAI是得物AI平台,是我们在容器化过程中,逐步收集和挖掘公司各业务域在AI模型研究和生产迭代过程中的需求,逐步建设而成的一个云原生AI平台。KubeAI以模型为主线提供了从模型开发,到模型训练,再到推理(模型)服务管理,以及模型版本持续迭代的整个生命周
 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质








