写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 聚类方法 频道下的 50 篇内容

为了保证系统、服务的可靠性和稳定性,监控系统日渐成为每个公司、企业的一个必不可少的系统。随着服务、机器等数量越来越多,如何分析海量时间序列KPI成为我们在智能运维领域首先需要解决的问题。
本文只是简单介绍了在实际项目中使用时间序列聚类算法时产生的疑惑和解决思路,期间很多方法可能还是尝试和实验阶段。由于时间的原因,可能还有很多细节方面考虑不是很周到,DTW算法比较可靠。目前我们还在通过其他一些对他的优化方法提升速度,后续会继续对电子商务用户生命周期时间序列的挖掘方法进行研究和提升,欢迎交流讨论。
Olivier Bachem等人在其NIPS 2016(Neural Information Processing Systems,神经信息处理系统大会,机器学习领域的顶级会议之一)的文章“Fast and Probably Good Seedings for k-Means”中提出了AFK-MC²算法,该算法改进了k-Means算法中初始种子点的生成方式,使其聚类速度相较于目前最好的k-Means++方式提高了好几个数量级。


说话人分类,即从包含多个说话人声音的音频流中,单独将每个人的音频划分到同一类别下的过程,是语音识别系统的重要部分。通过解决“谁在何时说话”的问题,说话人分类可以应用于许多重要场景,例如理解医疗对话、视频字幕等。


工业界现有的推荐系统都需要从一个超大规模的候选集中拉取item进行打分排序。

本文研究了一种基于自然语言理解的客服QA推荐系统,该系统目前已应用在百度云客服团队,在提升百度云用户体验、减轻客服压力等方面取得了不错的成效。
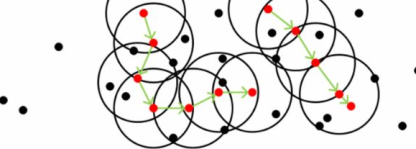
俗话说的:“物以类聚,人以群分”。聚类是一个把数据对象划分成子集的过程,每个子集是一个簇(cluster),使得簇中的对象彼此相似,但与其他簇中的对象不相似。聚类成为自动分类,聚类可以自动的发现这些分组,这是突出的优点。


本文系AIOps在美团的探索与实践的第一部分,如何自动发现故障问题,其中重点介绍了美团时序数据异常检测系统Horae的架构与设计。
云计算环境下,及时发现服务器集群中的性能问题至关重要。开发者经常会遇到这样一种情况,整个系统工作性能急剧下降,但简单的查找很难发现明显的漏洞,最终需要耗费大量的人力对所有服务器进行逐台排查。因此,开发者会寄希望于自动检测技术发现出现异常的服务器。针对这个问题,Netflix的工程师们通过构建了一个自动异常检测系统,做了很好的工作。

Facebook开发了一款名为Getafix的工具,可以自动查找出bug的修复方案,并提供给工程师审批,极大提高了工程师的工作效率和整体代码质量。
聚类是数据挖掘中的一个概念,是按照某个特定标准(如距离)把一个数据集分割成为不同的类或者簇,使得同一个类内的数据对象的相似性尽可能大,同时不在同一个类内的数据对象的差异性也尽可能得大。即聚类后的同一类数据尽可能聚集到一起,不同类的数据尽量分

无监督学习和聚类算法是人工智能领域中的重要分支,它们在没有明确标签的情况下,通过分析数据的内在结构和模式,实现信息的自动组织和分类。本文将深入讨论无监督学习的基本概念、聚类算法的原理及应用,以及在数据科学领域中的关键作用。

无监督图像分类问题是图像分类领域一项极具挑战的研究课题,本文介绍了无监督图像分类算法的发展现状,供参考学习。


在本案例中,我们使用人工智能技术的聚类算法去分析超市购物中心客户的一些基本数据,把客户分成不同的群体,供营销团队参考并相应地制定营销策略。
 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质











