Ignite 基于发现技术可以自我感知地建立集群,同时实现了 MapReduce 范式,这两项技术再加上分布式缓存技术,为传统的企业级批量业务处理提供了新的更优雅、性能更好、综合成本更低的解决方案,本文将对这部分进行简单的整体性介绍,方便读者入门,如果读者想了解更详细的信息,可以参考相关的手册。
1. 传统的方案
在各行各业中,批量业务处理都是常规需求,非常常见。它的特点是,离线处理、运行时间长、计算密集。传统的解决方式是,或者使用多线程技术,或者使用数据库计算,比如调用数据库的存储过程技术实现等等。
在以 Hadoop 为首的分布式计算技术出现后,情况有了很大的变化,MapReduce 范式为大规模离线数据处理提供了新的思路,性能得到了很大的提升,也提供了很好的线性扩展解决方案。
2. 面临的问题
多线程或者类似于存储过程这样的技术,共有的缺陷是,扩展性差,性能依赖于单一硬件性能,大幅提升性能困难,无法实现分布式计算。
而以 Hadoop 为首的大数据处理解决方案,近段时间发展迅速,性能指标也在不断地提升,但是设计的目标,或者说适用的场景,主要还是在互联网的大规模非结构化数据的分析业务上,虽然也可以用于传统的批量业务处理,但是一方面批量业务处理并不需要那么多的功能,杀鸡用了牛刀;另一方面,这些新一代的计算平台属于异构系统,需要在具体应用之外单独部署,如果要实现高可用,整体的架构也会变得非常复杂,整体的运维成本也会上升,增加了对应的服务器之后,如果计算不多,资源利用率也会下降,采用这样技术的投入产出比,是需要考虑的。
3.Ignite 计算网格
Ignite 计算网格实现了分布式的闭包和 ExecutorService,同时它还提供了一个轻量级的 MapReduce(或 ForkJoin) 实现。
本文重点讲一下轻量级 MapReduce,其它的可以参照相关的手册。
3.1.MapReduce 和 ForkJoin
ComputeTask接口是 Ignite 的简化版内存 MapReduce 的抽象,它也非常接近于 ForkJoin 范式。这个接口可以对作业到节点的映射做细粒度的控制以及定制故障转移的策略,如果不需要这些,可以使用更简单的分布式闭包实现,代码将会更加精炼。
3.1.1.ComputeTask
ComputeTask定义了要在集群内执行的作业以及这些作业到节点的映射,它还定义了如何处理作业的返回值 (Reduce)。所有的IgniteCompute.execute(...)方法都会在集群上执行给定的任务,应用只需要实现ComputeTask接口的map(...)和reduce(...)方法即可, 其中:
map(...)方法负责将作业实例化然后将它们映射到工作节点,这个过程通过ComputeTaskSplitAdapter,还可以进一步简化;result(...)方法在每次作业在集群节点上执行时都会被调用,它接收计算作业返回的结果,以及迄今为止收到的作业结果的列表,该方法会返回一个ComputeJobResultPolicy的实例,说明下一步要做什么;- 当所有作业完成后,
reduce(...)方法在 Reduce 阶段被调用。该方法接收到所有计算结果的一个列表然后返回一个最终的计算结果。
3.1.2. 更简单的适配器 ComputeTaskSplitAdapter
定义计算时每次都实现ComputeTask的所有三个方法并不是必须的,通过 Ignite 提供的适配器,可以进一步简化开发,我着重介绍下ComputeTaskSplitAdapter,它增加了将作业自动分配给节点的功能。它隐藏了map(...)方法然后增加了一个新的split(...)方法,使得开发者只需要提供一个待执行的作业集合即可,这非常适用于批量业务处理。这个适配器对于所有节点都适于执行作业的同质化环境是非常有用的,这样的话映射阶段就可以隐式地完成。
3.1.3.ComputeJob
任务触发的所有作业都要实现ComputeJob接口,这个接口的execute()方法定义了作业的逻辑然后返回一个作业的结果。
3.1.4. 简单示例
下面这段代码,作为一个简单示例,显示了如何计算一段话中的字母的总数量:
IgniteCompute compute = ignite.compute();
// 在集群上执行任务。
int cnt = grid.compute().execute(CharacterCountTask.class, "Hello Grid Enabled World!");
private static class CharacterCountTask extends ComputeTaskSplitAdapter<String, Integer> {
// 1. 将收到的字符串拆分为字符串数组
// 2. 为每个单词创建一个作业
// 3. 将每个作业发送给工作节点进行处理
@Override
public List<ClusterNode> split(List<ClusterNode> subgrid, String arg) {
String[] words = arg.split(" ");
List<ComputeJob> jobs = new ArrayList<>(words.length);
for (final String word : arg.split(" ")) {
jobs.add(new ComputeJobAdapter() {
@Override public Object execute() {
return word.length();
}
});
}
return jobs;
}
@Override
public Integer reduce(List<ComputeJobResult> results) {
int sum = 0;
for (ComputeJobResult res : results)
sum += res.<Integer>getData();
return sum;
}
}
<span></span>是不是非常简单?
3.2. 容错
Ignite 支持作业的自动故障转移,当一个节点故障时,作业会被转移到其它可用节点再次执行。故障转移是通过FailoverSpi实现的,FailoverSpi负责选择一个新的节点来执行失败的作业。它会检查发生故障的作业以及该作业可以尝试执行的所有可用的网格节点的列表。它会确保该作业不会再次映射到出现故障的同一个节点。故障转移是在ComputeTask.result(...)方法返回ComputeJobResultPolicy.FAILOVER策略时触发的。Ignite 内置了一些故障转移 SPI 的实现,开发者也可以进行定制。另外,Ignite 保证,只要有一个节点是有效的,作业就不会丢失。
3.3. 负载平衡
Ignite 中的负载平衡是通过LoadBalancingSpi实现的。它控制所有节点的负载以及确保集群中的每个节点负载水平均衡。对于同质化环境中的同质化的任务,负载平衡采用的是随机或者循环的策略。然而在很多其它场景中,特别是在一些不均匀的负载下,就需要更复杂的自适应负载平衡策略。Ignite 内置了若干中负载平衡实现,比如循环式负载平衡RoundRobinLoadBalancingSpi以及随机或者加权负载平衡WeightedRandomLoadBalancingSpi, 这部分开发者也可以定制开发,满足个性化需求。
3.4. 作业调度
Ignite 中,作业是在客户端侧的任务拆分初始化或者闭包执行阶段被映射到集群节点上的,但是一旦作业到达被分配的节点,就会有序地执行。默认情况下,作业会被提交到一个线程池然后随机地执行,如果要对作业执行顺序进行细粒度控制的话,需要启用CollisionSpi, 比如,可以按照 FIFO 排序或者按照优先级排序。
3.5. 事务
在企业级批量业务处理中,通常要对数据库进行频繁的更新操作,在分布式计算环境下,将整个任务配置为一个事务显然是不合适的。最佳实践是将每个作业配置成一个事务,这样如果某个作业失败,只是该作业回滚,其它成功的作业还是正常提交的,然后故障转移机制会使该失败的作业再次执行,直到成功提交。
3.6. 其它
Ignite 的内存 MapReduce 实现还支持会话,这个机制可以在任务和作业之间共享一些数据,还支持节点局部状态共享,这个其实是节点的局部变量,它可以用于任务在不同的执行过程中共享状态。还有,通过计算和缓存数据的并置,可以极大地提高性能,它还支持检查点,可以在一个长时间执行的作业中保存一些中间状态,这个机制在重启一个故障节点后,作业可以从保存的检查点载入然后从故障处继续执行。等等,在这里就不一一介绍了。
4.Ignite 的优势
在之前的关于 Ignite 的集群部署的文章中我对 Ignite 的集群特性做了简要的介绍,该文中推荐了一种混合式的集群部署方案,如下图:
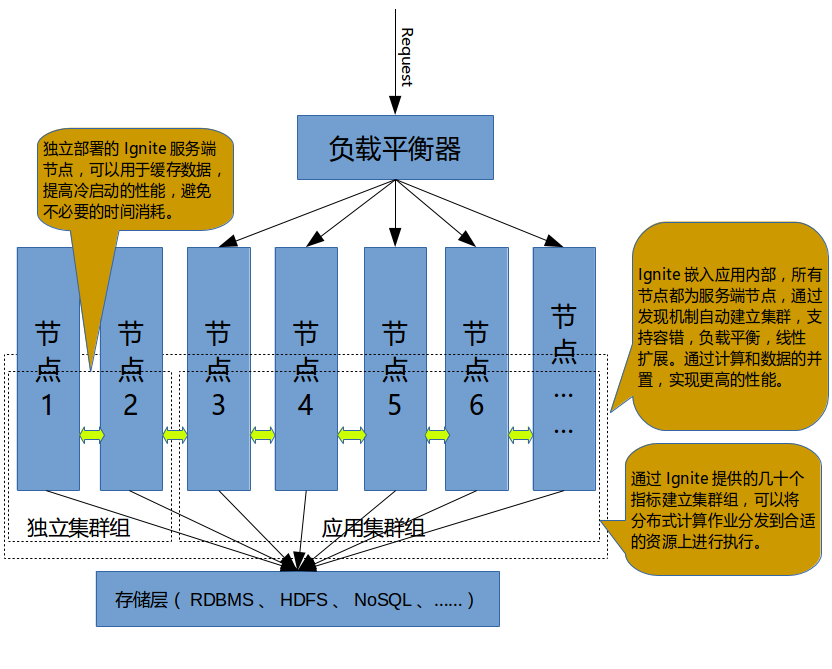
在这个架构中,如果能够在应用集群组中进行分布式计算来实现批量业务处理,那么这会是一个很优雅的解决方案,幸运的是,Ignite 真的实现了,这个解决方案整体上来讲,具有如下的优势:
- 开发简单:很简单的几段代码就实现了 MapReduce,入门门槛极低,经过很短时间的学习,就可以把注意力放在复杂业务的处理上;
- 调试简单: Ignite 单机就可以启动一个只有一个节点的集群,可以在 IDE 中直接单步调试,不需要为了开发调试构建任何复杂的环境;
- 部署简单:只要将 Ignite 的几个 jar 包嵌入应用内部,就可以利用 Ignite 的发现机制自动建立集群,实现分布式计算,而其它分布式计算平台,基本都需要部署单独的计算服务器,整个部署架构也变得复杂,运维成本也会上升;
- 资源利用率高:通常批量业务处理都是在夜间系统空闲时,如果还是在这些设备上进行分布式计算,可以充分利用计算资源,如果采用需要单独增加服务器的计算方案,因为大部分时间设备闲置,整体设备成本上升,资源利用效率也会大幅下降。




