
在云计算环境中,Kubernetes(K8s)集群与容器化部署已成为行业标准化实践,但同时也对运维体系及可观测性提出了显著挑战:一方面,主流监控工具(如 Node Exporter、cAdvisor 和 Datadog)虽能提供系统级与容器级的基础指标,却难以覆盖操作系统深层次问题(如调度延迟、内存回收延迟、TCP 重传率等),而引入增强型指标又面临操作系统知识门槛高、分析复杂度大的难题;另一方面,传统监控体系在告警触发或问题发生时往往缺乏完整的上下文数据,导致根因定位困难,需依赖问题多次复现才能排查。此外,指标与问题之间的关联复杂——单一指标变化可能由多个问题引发,同一问题也可能影响多个指标,而集群、节点、Pod 的分层架构虽为资源管理提供了逻辑划分,但业务问题与节点的承载关系常因维度割裂未能有效关联,进一步加剧了运维复杂性。
为应对以上挑战,阿里云操作系统控制台(以下简称“操作系统控制台”)依托于大量操作系统问题案例沉淀及知识总结,结合 AIOps 等相关技术,提出了从智能异常检测到智能根因分析,再到智能修复建议的全链路一站式运维解决方案。从中提炼出如系统 OOM、系统内存黑洞、调度延时、负载(load)高、IO Burst、网络延时、丢包等典型的操作系统问题场景,沉淀出对应的端到端的解决方案。如图 1 所示,通过全链路闭环流程高效管理与解决上述业务挑战。
针对问题场景,提取相关指标,结合领域专家经验设定的阈值规则以及智能化异常检测算法,构建多维度的异常发现机制,从而实现对潜在问题的精准识别与实时检测。
对于实时检测到的异常事件,为了分析异常响应及根因,需进一步采取以下措施:
现场信息采集与根因诊断:通过自动化工具对异常发生时的运行环境进行全面的信息采集,从而进一步定位问题的根本原因,并生成针对性的解决方案或修复建议。
告警通知与分发:将异常事件及其诊断结果通过多渠道(如邮件、短信、即时通讯工具等)推送至相关运维团队或责任人,确保问题能够被及时响应与处理。
健康评分动态更新:基于异常事件的影响范围与严重程度,实时更新集群、节点及 Pod 的健康评分,为资源调度、容量规划及故障预测提供量化依据,同时支持全局视角下的系统状态评估与决策优化。
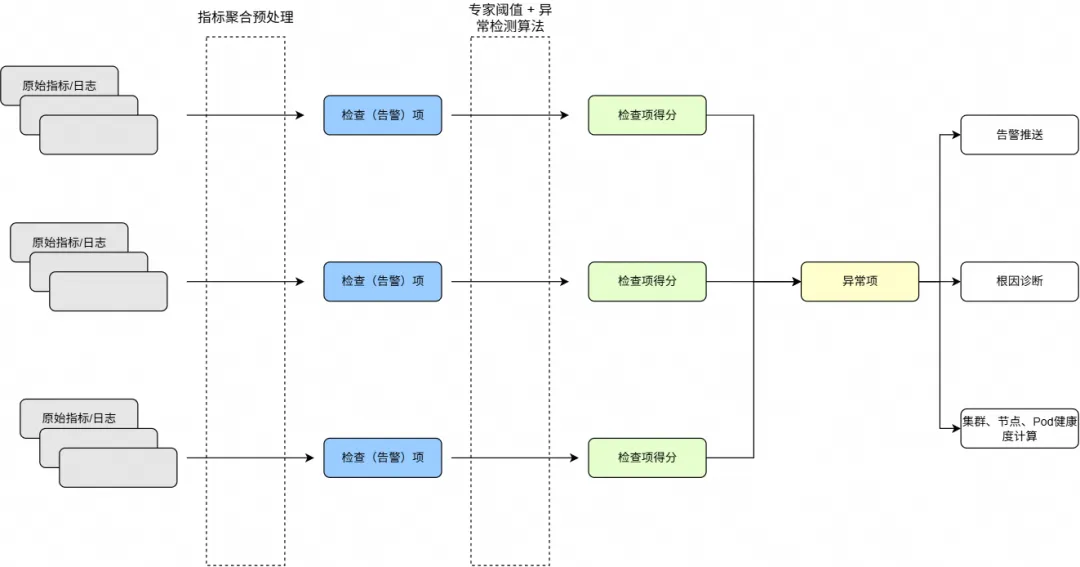
下面我们具体介绍上述链路中较为关键的异常检测、信息采集与根因诊断和集群、节点、Pod 健康度计算这三个功能。
异常检测
多种多样的操作系统相关的监控指标,在不同场景中,这些指标呈现的规律也不尽相同,如何能有效,准确地识别出监控指标中的异常也是一种挑战。
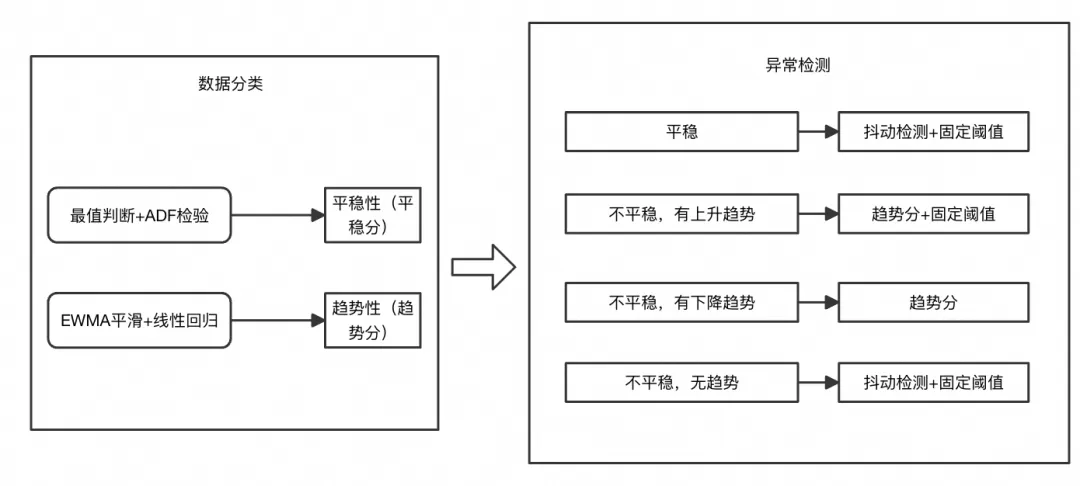
为了尽可能地适应不同场景的指标异常发现,操作系统控制台采用一种通用的监控指标处理算法和多模型集成的通用异常检测算法,该算法如图 2 所示:
多种不同类型的监控指标输入后先进行分类,如整体平稳的、呈一定变化趋势的、和无规则波动
分类的指标由无监督的多模型结合的异常检测算法进行检测,结合专家阈值和多种模型联合判决有效提高了检测准确率,同时根据系统指标的特征进行优化,在处理监控指标之前进行预处理,进一步提升效率。
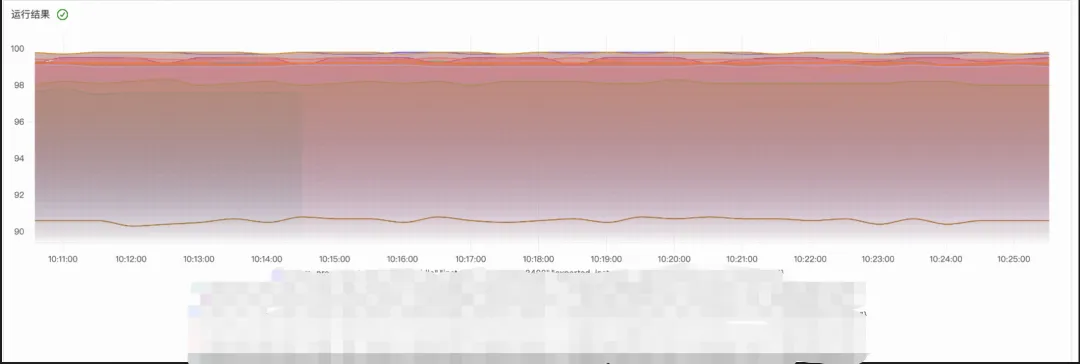
下面通过一些典型的指标类型,来举例简单说明异常检测的预期效果:
平稳性高水位指标:对于 CPU 利用率,内存利用率等指标可能持续处于一个非常高的水位,虽然对系统健康有一定影响,但是是预期内的,检测水位阈值和其平稳性,最终会识别为一个潜在的异常。
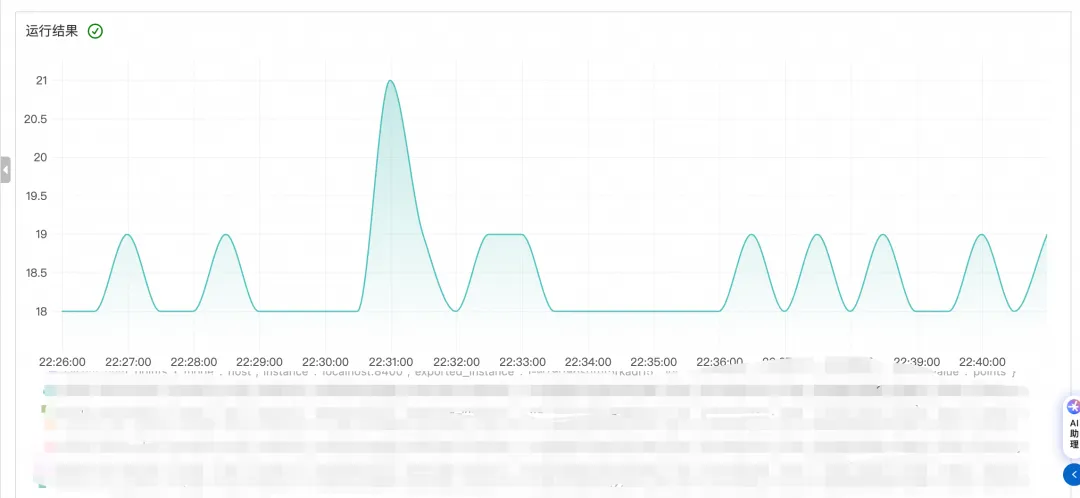
毛刺、波动型指标:对于毛刺,波动型指标,我们结合专家阈值和抖动检测算法,根据指标的波动大小,以及其离我们设置的最小,对大阈值的具体,综合评估出当前指标的异常程度。
信息采集与根因诊断
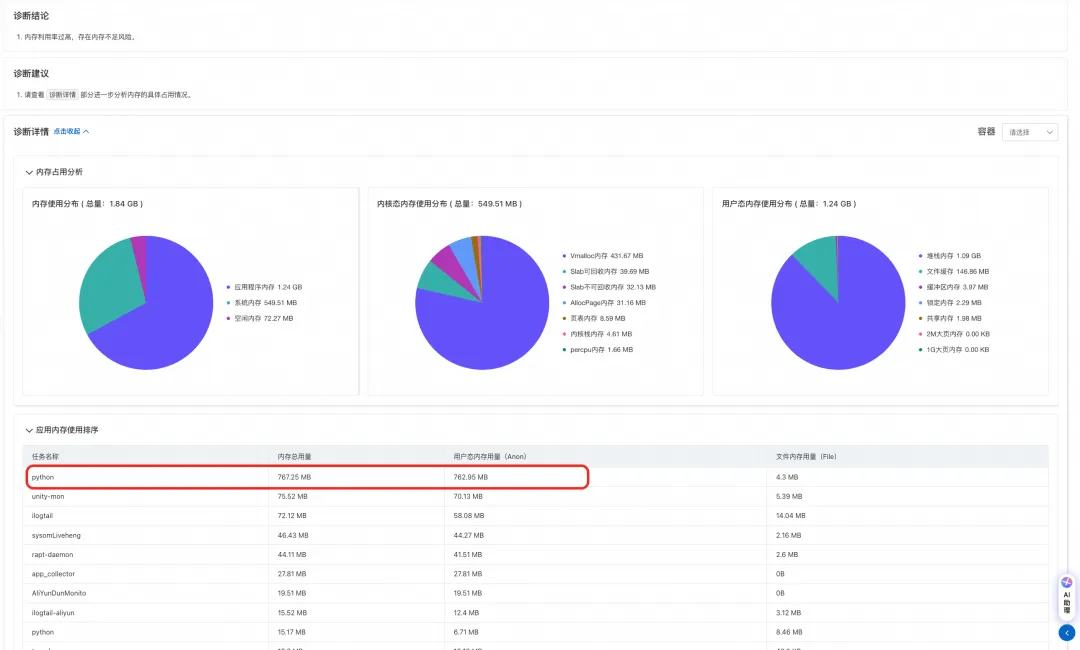
为了避免现场丢失导致后续问题定位困难。在捕获异常的同时,操作系统控制台会根据对应的策略结合其提供的相应的诊断功能,在异常现场对识别出的异常进行信息采集和根因诊断。如下图所示:当内存高异常被捕获后,操作系统控制台通过对异常现场进行诊断,最终得出当前内存高异常是由 python 应用内存占用导致。
集群、节点、Pod 健康综合评价
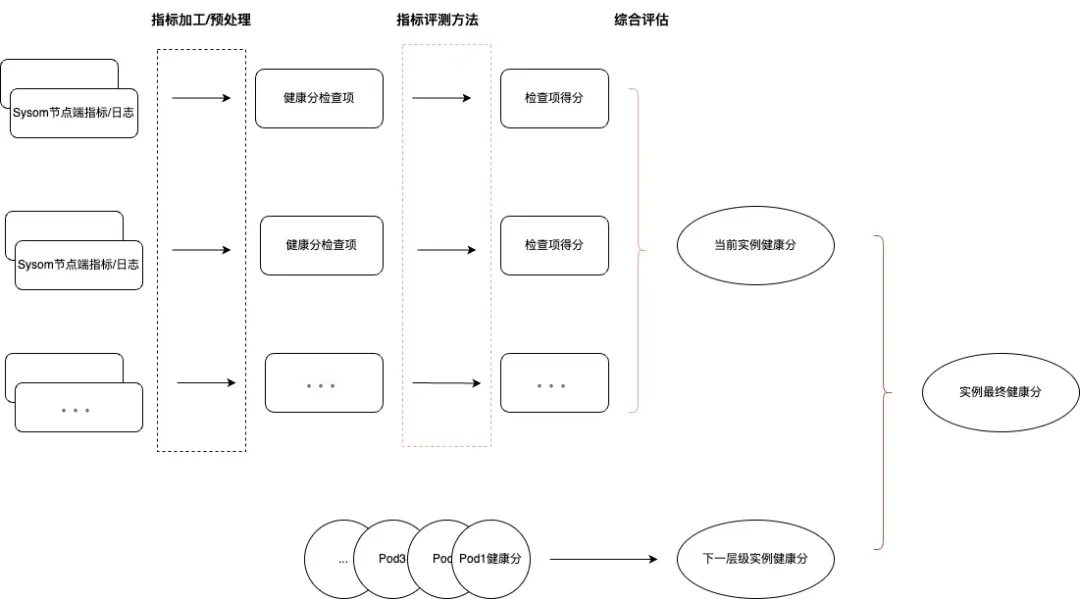
为了方便用户能快速识别集群或节点中的风险, 操作系统控制台在系统概述页面提供了整个集群的健康概论,在这背后,我们采用了一套多维度的综合评估算法,希望将 pod,节点的风险层层递进,反映到集群的健康风险中,如图 5 所示,以节点健康度为例:
节点健康由节点的异常项(图中为当前实例健康分)和节点中 pod(如有)的健康(图中为下一层级实例健康分)综合影响,其中:
当前实例健康分通过为各检查项设立相应的权重通过综合评估方法计算得出。
下一层级实例健康分通过分级木桶原理的方式,根据处于不同健康等级的 pod 数量计算得出。
如何通过阿里云操作系统控制台一站式定位系统问题案例解析
案例一:通过操作系统控制台定位 IO 流量高问题
汽车行业某客户从监控中发现集群中总是偶发出现节点 IO 流量非预期打高的现象,由于出现的机率不高,且出现的节点随机,所以没有好的办法定位 IO 流量打高的具体原因。
针对上述场景,客户通过使用系统概览提供的异常识别诊断能力来监控和定位该问题。
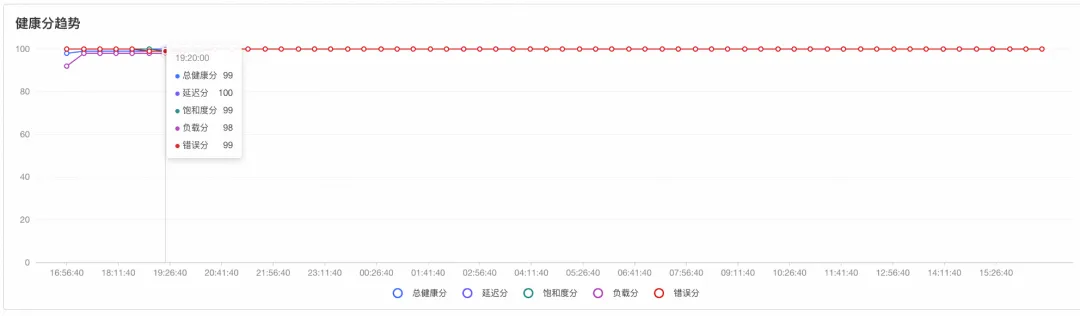
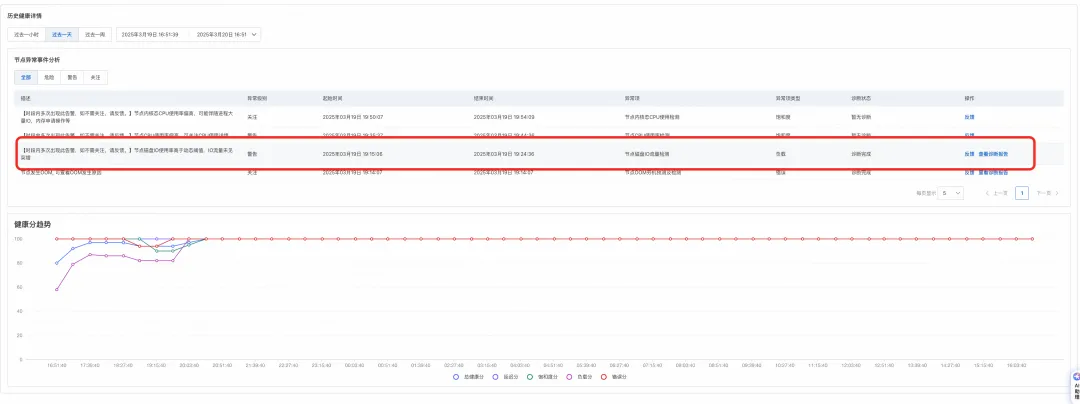
客户开通操作系统控制台后,首先通过集群的历史健康分趋势观察到某一时间集群分数(负载分)有下降。
通过节点健康列表可以进一步看到低分的实例:

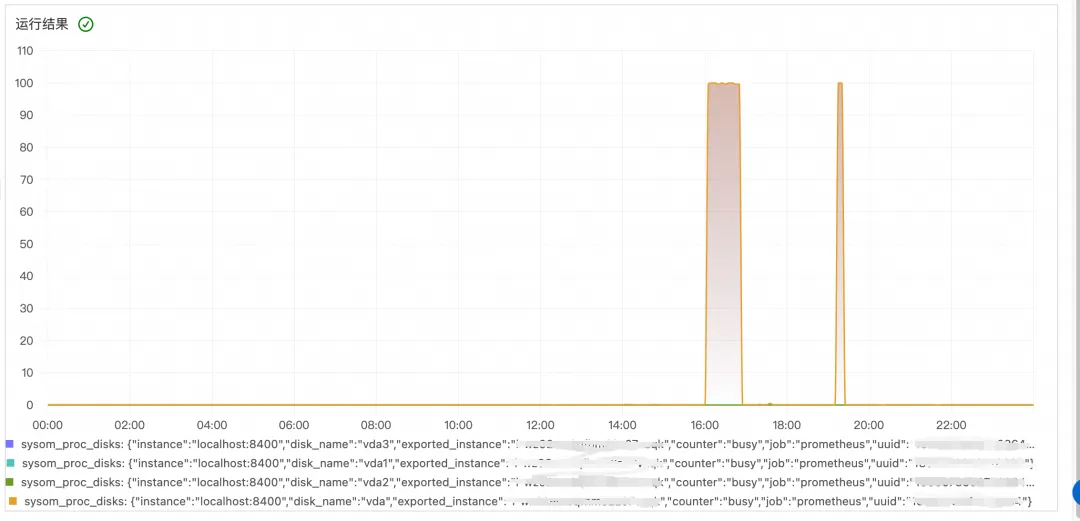
跳转至节点健康页面后,通过异常事件分析面板可以看到当天的某一时刻节点发生了 IO 流量突增的异常,并且已经生成了对应的诊断报告。
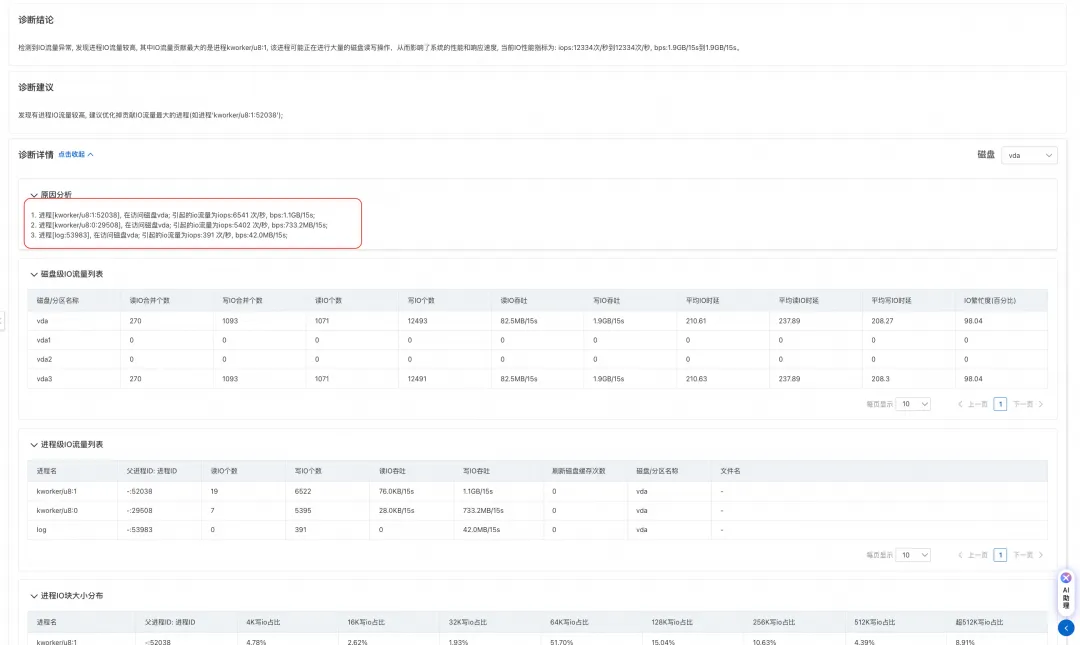
通过查看诊断报告,如下图所示,可以发现产生 IO 流量的主要是 kworker 内核线程和客户的日志转储进程。kworker 线程 IO 高通常来说意味着 kworker 正在进行刷脏(将文件脏页刷到磁盘中)操作。经过和正常机器的对比发现,问题机器的 vm.dirty_background_ratio 被设置的非常低,设置成 5%;这意味着当脏页数量达到系统内存的 5% 后就会触发内核线程进行脏页回写,导致 IO 打高。
客户通过将 vm.dirty_background_ratio 和 dirty_ratio 参数调大后,IO 流量规律恢复正常。
案例二:通过操作系统控制台定位 load 高问题
汽车行业某客户业务从节点切换至容器部署后发现节点 load 总是定期飙高,需要进一步定位根因。
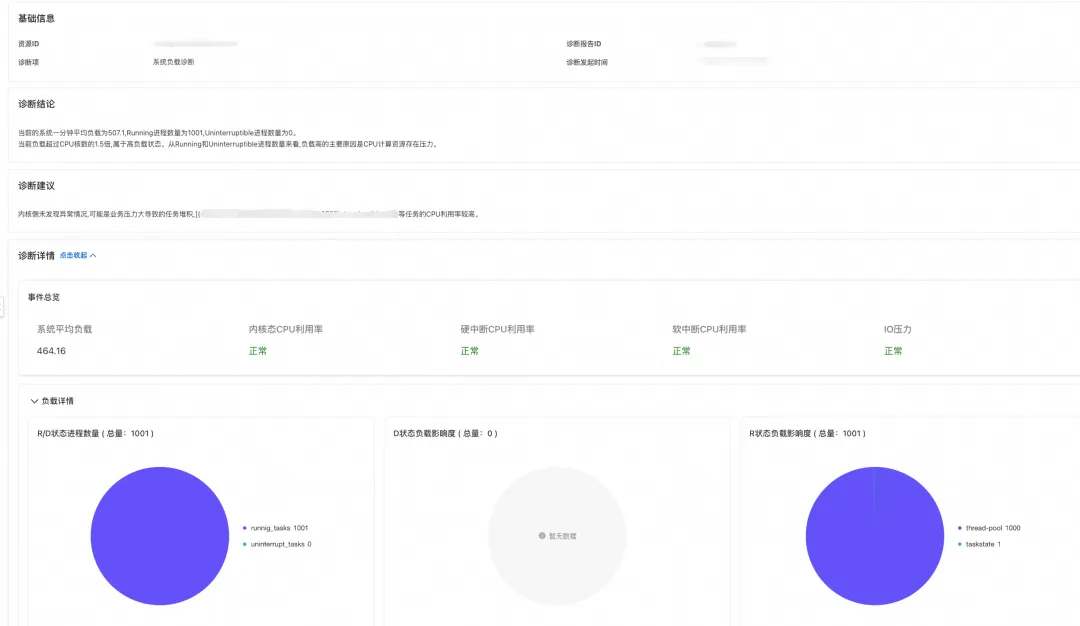
针对该问题,客户通过操作系统控制台纳管集群后,客户从系统概述页面观察到对应集群/节点健康分下降,异常事件中出现 load 高异常。

通过进一步查看诊断报告,可以发现在负载增加是由于大量 R 状态进程产生造成,客户通过确认后可以确定在 load 增高的时间点业务流量增加,业务会通过创建大量线程进行处理;结合同一时间 Pod 中产生连续的 Pod 限流异常,可以确定是由于容器的 cpu limit 设置过小,导致线程无法短时间内完成相关逻辑,从而进一步导致线程以 R 状态堆积在运行队列中,导致 load 飙高。
问题定位后,客户通过调整业务容器 cpu limit 后,load 恢复正常。
客户收益
通过操作系统控制台产品来快速定位集群系统问题,客户可以获得以下收益:
降低操作系统运维门槛:通过操作系统控制台为客户设立的异常检查项、异常识别规则以及配套的诊断工具。客户无需具有一定的操作系统知识储备即可对操作系统问题一站式解决。
简化运维流程和相关人力投入:通过操作系统控制台系统概述,客户可以快速识别出集群中的告警和风险,并找到问题的根源和解决方案,缩短故障的发现和排除时间。
总而言之,操作系统控制台给云计算和容器化运维带来新的可能,能够提高系统性能与运维效率,同时为企业减少了系统相关问题带来的困扰。
我们通过阿里云操作系统控制台系列文章,解析系统运维遇到的痛点问题。下一期文章中,我们将分享异常检测算法相关内容,敬请期待。
使用操作系统控制台的过程中,有任何疑问和建议,您可以扫描下方二维码或搜索群号:94405014449 加入钉钉群反馈,欢迎大家扫码加入交流。

阿里云操作系统控制台 PC 端链接:




