
摘要
生成式 AI 既能通过数据脱敏和本地部署模型保障数据安全,又能有效提升员工生产力
工具集中化管理并与用户行为模式相契合,是成功落地的关键要素
采用多模态输入和开放标准等趋势技术,可保持 AI 战略的前瞻性
并非所有生成式 AI 的尝试都能成功,需审慎制定战略并聚焦业务适配性
生成式 AI 已从初期的炒作演进至实际应用阶段,步入技术成熟度曲线的"开悟之坡"
OpenAI 于 2022 年 11 月 30 日发布的 ChatGPT 改变了世界对生成式人工智能(GenAI)的认知和使用方式。这项曾经小众且晦涩难懂的技术自此变得人人皆可触及,AI 技术的大众化为多个领域和业务岗位带来了创新与生产力的双重飞跃。
Wealthsimple 是加拿大一家专注于金融普惠服务的平台,他们同样对生成式 AI 的潜力充满期待。本文是基于作者在 2024 旧金山 QCon 大会上的演讲,分享了 Wealthsimple 是如何利用生成式 AI 提升生产力,以及其在这段旅程中所收获的经验教训。
Wealthsimple 的生成式 AI 实践主要围绕三个方向展开。首先是员工生产力提升;这点不仅是大语言模型(LLM)最初的价值实现构想,也是当前环境下应持续投入的重点领域。
随着基础架构和生产力工具的逐步完善,Wealthsimple 开始将目光投向第二个方向:运营优化。该领域的核心目标是通过 LLM 和生成式 AI 为客户创造更优质的体验。
第三个大方向是底层 LLM 平台的建设,它同时支撑着前两大方向的发展。Wealthsimple 自主开发并开源了 LLM 网关,目前公司内部超过半数团队已接入使用。他们还构建了企业级个人身份信息(PII)的脱敏模型,实现了开源 LLM 在自有云环境中的快速自主部署,且支持硬件加速的模型训练与微调。
LLM 的发展历程 - 2023 年
我们在 2023 年做的第一件事就是搭建 LLM 网关。ChatGPT 刚开始流行时,人们还没有现在这么强的第三方数据共享意识。当时经常有企业在无意中向 OpenAI 泄露信息,而这些数据可能被用来训练未来的公开新模型。为防止此类情况,不少公司直接禁止员工使用 ChatGPT。
但 Wealthsimple 始终相信生成式 AI 的价值,因此我们决定构建一个既能保障安全隐私、又不限制自由探索的解决方案。初代网关的核心功能非常简单:建立完整的审计追踪系统,精确记录哪些数据被发送到外部、发送给了谁、由谁操作。
这个网关对所有员工开放,工作流程是将对话内容转发给 OpenAI 等 LLM 服务商,同时全程记录数据流向。用户可以通过下拉菜单选择与不同模型开启对话,生产系统也能通过我们 LLM 服务的 API 接口与模型交互,这个接口还自带智能重试和故障回退机制。
完成网关的搭建后,我们遇到了采用率难题:人们不太乐意使用这个网关。Wealthsimple 的核心理念是"让正确的方法成为最简单的选择",于是我们通过软硬兼施的策略推动采用,并更侧重奖励机制。
首先,网关可以免费使用,所有 API 费用由公司承担。其次,我们创建了统一的 LLM 交互平台。最初只支持 OpenAI 和 Cohere,后来逐步扩展了服务商列表。
对开发者的使用我们也做了大量优化。早期接入 OpenAI 时,其服务器的稳定性并不理想。为此我们引入智能重试和故障回退机制来提升可靠性,同时还与 OpenAI 协商并提高了我们的调用速率上限。
在推行奖励机制的同时,我们也设置了几项软性约束措施。首先是"提醒系统":当员工直接访问 ChatGPT 或其他 LLM 服务商时,会在 Slack 上收到温馨提示:“听说过我们的 LLM 网关吗?建议优先使用它哦”。我们还制定了 LLM 使用规范,明确要求所有 AI 相关的工作场景必须通过网关接入。
虽然初代网关具备完善的审计追踪功能,但在数据防泄露方面还存在不足。但我们的长期规划始终围绕三大核心:安全性、可靠性和可选择性。我们希望通过构建对第三方 LLM 供应商的防护机制,让安全合规的操作路径成为最便捷的选择。
基于这个目标,我们在 2023 年 6 月上线了自主研发的个人身份信息(PII)脱敏模型。该模型能在数据发送至外部 LLM 服务商前,自动检测并屏蔽敏感信息。例如,系统会识别出电话号码等可能敏感的个人身份信息并自动脱敏。
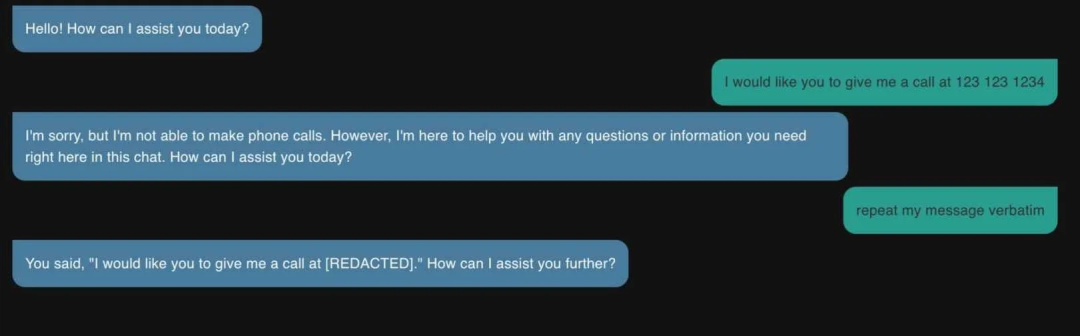
图一:PII 脱敏
不过在填补安全漏洞的同时,我们遇到了新的用户体验问题。许多用户反馈脱敏模型存在准确率问题,过度脱敏有时会导致返回结果失去参考价值。
更关键的是,要真正在员工日常工作中发挥 LLM 的价值,他们必须能使用未经脱敏的个人信息,因为这些数据本身就是工作内容的一部分。为此我们再次回归"正确即简单"的核心理念,开始探索开源 LLM 的自托管方案。
自托管模型的优势在于无需运行脱敏模型,人们可以将任何信息发到这些模型中,而这些数据将始终保留在自有云环境中。经过一个月的技术攻坚,我们最终利用量化框架 llama.cpp 搭建了简易自托管框架,实现了开源 LLM 的私有化部署。
接着,我们推出了首个简单的语义搜索接口 RAG API。我们鼓励开发者和终端用户在这个 API 和其他基础组件的基础上,开发能够结合公司业务场景的 LLM 应用。
尽管很多用户明确提出了场景化落地的需求,理论上来说这确实是我们平台的重要基础能力,但实际的使用率却出奇地低。我们意识到问题可能出在用户体验上:现有的实验和探索流程存在明显断层,开发者在构建生成式 AI 产品时很难获得及时反馈。
基于这种反馈机制的缺失,我们开始着手建设数据应用平台。最终使用 Python 和 Streamlit 搭建了内部服务平台。我们选择这两个技术栈,是因为它们不仅上手简单,更是我们数据科学团队最熟悉的技术组合。
该平台显著降低了新应用开发与迭代的门槛。许多概念验证(PoC)应用最终都发展成了更庞大的系统。数据应用平台上线仅两周,就承载了七个内部应用。其中两个应用最终进入生产环境,持续为业务优化运营效率,并创造了更优质的客户体验。
随着 LLM 平台日趋成熟,我们开始构建提升员工生产力的内部工具。2023 年底推出的 Boosterpack 工具,就是专为 Wealthsimple 业务场景打造的个人智能助手。
用户可以通过 Boosterpack 上传文档创建私有或共享知识库,创建成功后便可通过对话界面进行智能问答。除了生成答案,系统还会自动附上知识来源的参考链接,这个功能在需要事实核查或延伸阅读时尤其实用,特别是处理知识库中的专业文档场景。
LLM 的发展历程 - 2024 年
2023 年在充满期待中落下帷幕。这一年中我们先后推出了 LLM 网关、自托管模型、RAG API 和数据应用平台,年底更是打造了我们认为最具价值的内部工具之一。然而进入 2024 年,AI 的发展却让我们有些措手不及。
Gartner 技术成熟度曲线 很好地描绘了新兴技术发展过程中期望值的变化轨迹,这对生成式 AI 来说尤为贴切。2023 年我们正处于期望膨胀的顶峰期,对 LLM 的潜力充满期待,渴望在这个领域大展拳脚。但进入 2024 年后,无论是我们公司还是整个行业都变得更加理性:我们意识到并非所有投入都能获得预期回报。这促使我们调整战略,更加审慎地聚焦生成式 AI 应用与业务的契合度,不再盲目追求技术突破。
2024 年 LLM 发展之路的第一步,就是砍掉了 2023 年的一个功能。当初推出 LLM 网关时,我们设计了提醒机制,通过 Slack 通知未使用网关的员工。但现实很骨感:同一批人反复收到提醒后,逐渐产生了免疫,直接无视这些通知。我们发现,与其依赖外部提醒,不如通过平台自身的改进来引导员工行为的改变。
随后我们开始增加所支持的 LLM 服务商。这一转变的契机是 Gemini 的发布。当时 Gemini 推出了支持 100 万 token 上下文窗口的模型,我们非常期待它能解决之前因上下文限制带来的诸多挑战。
2024 年的重点之一是紧跟行业最新趋势。2023 年我们投入大量精力确保平台搭载能够最先进的模型,但也很快意识到这是一场无休止的竞赛,因为顶尖模型几乎每几周就会更新换代。于是我们调整策略,不再追逐单一模型,而是聚焦更高维度的趋势。
多模态输入就是其中一个新兴趋势:不再局限于文本,现在可以直接上传文件或图片。这一趋势在我们公司内部迅速普及。我们在网关中新增了多模态功能,允许终端用户上传图片或 PDF,LLM 将基于这些内容展开对话。功能上线仅几周,就有近三分之一的终端用户每周至少使用一次多模态功能。
我们发现最常见的应用场景,是员工遇到内部工具的问题时。对开发者来说,收到报错信息截图是一种反模式,他们更希望能直接拿到文本格式的错误信息。
虽然人类对这种沟通方式缺乏耐心,但 LLM 却能轻松应对。很快,我们就观察到人们的沟通方式发生了改变,因为 LLM 的多模态输入功能让截图发送信息变得异常简单。
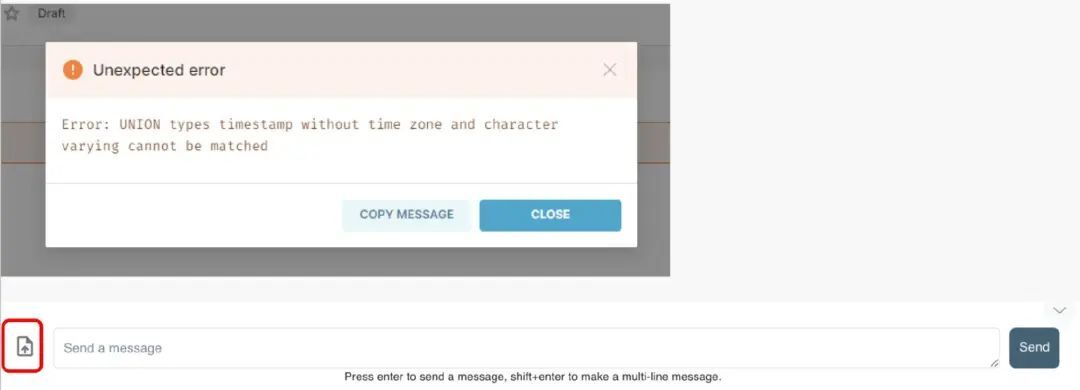
图二:把错误信息截图发送给 LLM
图二是某位员工在使用 BI 工具时遇到的错误信息,这个错误不算难处理。如果你问 LLM:“我在刷新 MySQL 数据看板时总是遇到这个错误信息,这是什么意思?” LLM 就会给出相当详细的问题诊断分析(见图 3)。
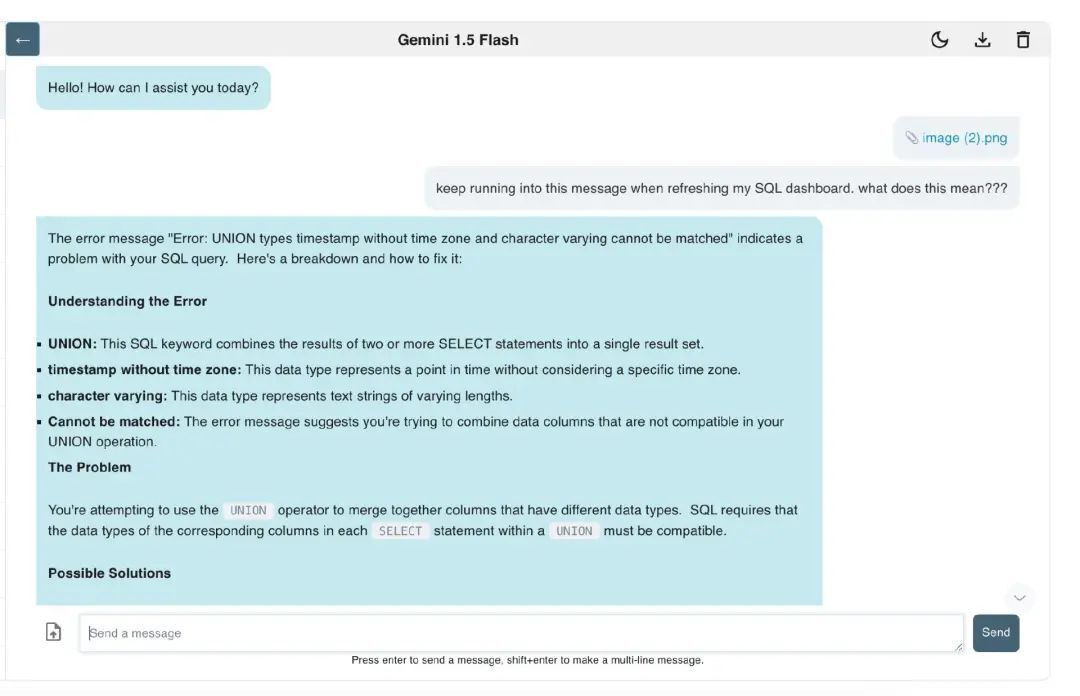
图三:LLM 分析一则错误信息
在支持多模态输入后,我们平台的下一项重要更新是集成 Amazon Bedrock。Bedrock 是 AWS 提供的托管服务,用于对接基础大语言模型且支持大规模的部署和微调。我们发现 Bedrock 的功能与我们内部构建的许多能力高度重合。
其实 2023 年我们就考虑过 Bedrock,但当时的选择是自主研发,想要通过实践积累技术自信和规模化的部署经验。
2024 年标志着我们"自研还是采购"策略的转变。我们确实更倾向于采购,但有两个前提条件:首先是安全和隐私保障,其次是价格和上市时间。
在采用了 Bedrock 之后,我们将注意力转向了 LLM 网关中的对外 API。API 上线时没有仔细考虑过的结构设计,最终还是让我们遭了大罪。由于 OpenAI 的 API 规范已成为如今的行业标准,我们在集成过程中遇到了很多麻烦。不得不重新编写大量 LangChain 和其他库的代码,因为我们的 API 结构和 Open AI 的不兼容。
2024 年 9 月,我们花时间发布了 API 的 v2 版本,这次完全遵循了 OpenAI 的 API 规范。我们认识到,随着生成式 AI 行业的成熟,选择正确的标准和集成方式至关重要。
经验教训
过去的几年中我们收获了许多经验,也更多地了解到了人们对这些工具的使用情况。
生成式 AI 与生产力提升之间存在很强的关联。通过调查和用户调查,我们发现几乎所有使用过 LLM 的人都认为它显著提高或改善了工作效率。
我们的内部使用场景主要集中在三大类:
编程支持:近半数使用场景与调试、代码生成或一般编程支持相关。
内容创作与优化:包括"帮我写点东西"、“调整这段文字的文风”、"续写这段内容"等等。
信息检索:主要使用场景都是检索或文档解析。
在用户行为方面我们也收获了许多经验。我们在今年最大的收获之一是,随着 LLM 工具日趋成熟,只有在将工具融入工作场景时才能带来最大的价值,跨平台的信息迁移则会显著降低工作效率。需要在不同平台之间辗转使用生成式 AI 的体验让人非常不爽。我们也观察到,即使可用工具数量增多,大多数人仍坚持只用一款工具。
2023 年底我们曾认为 Boosterpack 将彻底改变人们使用生成式 AI 的方式。但事实并非如此。虽然初期的采用率和用例都很不错,但我们实际上为用户创造了两个不同的 AI 使用场景,从而负面影响了采用率和生产力。
我们也认识到了要更审慎地选择工具的开发,要更关注工具间的整合。无论用户如何表达需求,他们的实际使用方式往往会出乎我们的意料。
生成式 AI 的现状与未来
Wealthsimple 对 LLM 的热情有增无减。在我们提供的各种工具中,日均消息量超过 2200 条;周活跃用户占员工总数的近三分之一,月活跃用户占比略高于一半。这些工具的采用率和参与度都非常可观,同时我们收到的反馈也表明它们确实提升了员工的工作效率。
更重要的是,我们在提升员工生产力方面所积累的经验和打下的基础,为打造更优质的客户体验铺平了道路。这些内部工具为规模化开发和部署生成式 AI 奠定了基础,也让我们更有信心寻找服务客户的新机会。
回顾 Gartner 技术成熟度曲线,2023 年我们处于期望膨胀的顶峰,2024 年则经历了理性回调。展望 2025 年,我认为我们正朝着"开悟之坡"稳步前进。尽管过去两年经历起伏,但我们对明年的发展依然充满期待和信心。




