开源,是当下大模型领域的热门趋势。但大多数开源模型只是开源了模型权重和一部分代码,不提供完整的训练数据和过程细节。这使得社区无法完全了解和复现模型构建的技术,只能在已有模型上微调,难以进行更底层的技术创新。
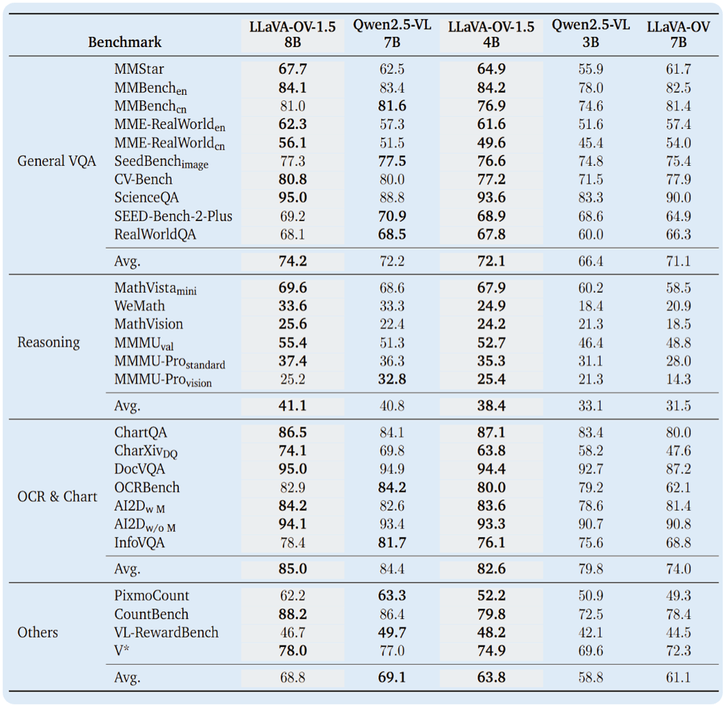
想解决这些问题,需要更大程度上的开源。近期,灵感实验室联合 LMMs-Lab 发布多模态大模型 LLaVA-OneVision-1.5,将训练数据、代码和模型权重全链路开源。从模型效果来看,LLaVA-OneVision-1.5 在多项公开多模态基准上表现优于同等规模的 Qwen2.5-VL。
从「开源」到「全开源」,从 toy 级到商用级,LLaVA-OneVision-1.5 是如何构建起来的?
全开源,「全」在哪?
区别于一般开源模型的开放程度,LLaVA-OneVision-1.5 的全链路开源涵盖:数据、训练与打包工具链、配置脚本、日志与可复现评测命令及其构建与执行细节,确保社区复现路径清晰,无需复杂调参即可跑通。
在训练数据方面,团队推出完整开放的 85M 预训练数据集(LLaVA-OV-1.5-Mid-Training-85M)与精筛 22M 指令数据集(LLaVA-OV-1.5-Instruct-22M),并且做到“概念均衡”——团队构建了一个 50 万的词表,利用图像特征与词表特征碰撞,并控制每个词碰到的图片数,制作出一个不同于随机采样的概念均衡训练集。
除了数据集以外,LLaVA-OneVision-1.5 技术报告、代码、模型也已开源:

技术报告:https://arxiv.org/abs/2509.23661
代码:https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
模型:https://huggingface.co/lmms-lab/LLaVA-OneVision-1.5-8B-Instruct
Demo:https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
数据集:
Pretrain Data:https://huggingface.co/datasets/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
Instruct Data:https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-1.5-Insturct-Data
低成本手搓一个「同款 Qwen2.5‑VL」
在全开源的同时,LLaVA-OneVision-1.5 突破了单纯的学术探讨,效果可以实现甚至优于同等规模 Qwen2.5-VL,达到商用级别。

这依托于技术方法上的创新。团队对「视觉编码器+投影层+大语言模型」的 LLaVA 架构进行模块升级:视觉编码器从 CLIP 替换为格灵深瞳自研的 Glint-ViT v1.5(RICE),大语言模型从 Qwen2 替换为 Qwen3。
在训练流程上,团队遵循了以下三个阶段:
Stage1:图文配准,使用 LLaVA-1.5 558K 训练投影层,将图文匹配到统一表达空间;
Stage1.5:高质量图文知识学习,使用 LLaVA-OneVision-1.5-Mid-Traning 85M 数据集提升模型图文认知能力;
Stage2:图文指令学习,使用 LLaVA-OneVision-1.5-Instruct 22M 数据集,引导模型图文指令跟随能力。
以上三个阶段结合多模态数据高效拼接,8B 规模 VLM 预训练可大约 4 天完成,预算控制在 1.6 万美元。
LLaVA-OneVision-1.5 的全开源意味着,在相同或更低 token 预算下,通过扩大高质量数据规模并结合“概念均衡”采样,模型可在多模态理解、指令泛化等核心指标上获得可复现的性能提升。




