我围绕一个模拟的加密货币数据集构建了我的第一个 dbt 项目,而且故意让它变得混乱。为什么?因为分析工程并不是关于完美的数据,而是将不可靠的输入转化为值得信赖的内容。
我没有清理随机的公共数据,而是设计了这个数据集,使其反映出与工作相关的挑战,比如重复数据、不一致的标记和冲突的类别——这些都是分析工程师每天需要解决的问题。
然后,我使用 Snowflake 对原始数据进行概况分析,利用 dbt 进行建模、标准化和测试——构建了一个看起来和实际生产环境中分析工程师所面临的情况相似的数据管道。
为什么数据概况很重要
混乱的数据不仅仅是带来小小的烦恼,它还会:
当值无法转换为正确类型时,导致查询失败。
当类别没有标准化时,造成冲突的度量。
当重复数据或空值出现在报告中时,破坏信任。
尽管我的数据集是模拟的,但我遇到了分析工程师在生产环境中常常面临的同样问题。
这是我在原始交易表中发现的内容:
重复数据 → 大约有 50 个 TRANSACTION_ID 出现了多次,有时仅在大小写上有所不同(t0001118 vs T0001118)。
空值 → USD_FX_RATE 有 2,541 个空值;其他关键列如 USER_ID 和 PRODUCT_ID 则没有。
类别不一致 →
数据类型错误 → 所有列在摄取时都变成了 VARCHAR(16777216)。
缺乏约束 → 数据仓库层面没有强制执行唯一性或外键约束。
换句话说:这就是一个完美的练习场,帮助我解决真实的数据质量问题。
我如何在 Snowflake 中对数据进行概况分析
我编写了一个 SQL 脚本(tx_profiling.sql),在 Snowflake 中运行系统性的检查。
模式和数据类型
desc table FINANCING_PRODUCTS.PUBLIC.raw_transactions; ✔ 确认所有列都是 VARCHAR(16777216) ✔ 验证没有键或约束
重复数据和唯一性检查
select transaction_id, count(*) from FINANCING_PRODUCTS.PUBLIC.raw_transactionsgroup by transaction_idhaving count(*) > 1; ✔ 发现大约 50 个重复的 transaction_id
空值分析
select sum(case when usd_fx_rate is null then 1 else 0 end) as null_fx_rate, sum(case when asset_amount is null then 1 else 0 end) as null_asset_amountfrom FINANCING_PRODUCTS.PUBLIC.raw_transactions; ✔ USD_FX_RATE 中有 2541 个空值 ✔ 关键字段中没有空值
值范围
select min(asset_amount), max(asset_amount), min(usd_fx_rate), max(usd_fx_rate)from FINANCING_PRODUCTS.PUBLIC.raw_transactions; ✔ 发现 NaN 和负资产金额 ✔ 外汇汇率从 0.8001 到 1.4998,符合实际,但不完整
域名检查
select distinct transaction_action from FINANCING_PRODUCTS.PUBLIC.raw_transactions; ✔ 13 个不一致的 transaction_action 值
我对 Snowflake 的一些发现
由于我的数据集规模较小且是模拟数据,数据概况查询运行顺利。这是一个优势——它让我能集中精力在工作流上,而不是等待查询完成。
即使在这个规模下,我也能练习真实团队在处理数 TB 数据时使用的相同步骤:
使用 DESCRIBE 检查模式和数据类型。
使用 TRY_TO_NUMBER 和 TRY_TO_TIMESTAMP_NTZ 安全地进行类型转换。
使用 ROW_NUMBER() OVER (PARTITION BY …) 进行去重。
让 dbt 将暂存模型作为 Snowflake 中的视图进行物化。
教训是什么?工作流是可以扩展的。那些在我模拟数据上有效的 SQL 模式,正是公司在生产环境中依赖的方式——Snowflake 只是处理了数据量的问题。
从数据概况到建模
数据概况不仅仅是打勾那么简单,它为我在 dbt 中的暂存模型提供了蓝图:
将 ASSET_AMOUNT 和 USD_FX_RATE 转换为数字类型。
将 EVENT_TIME 和 INGESTION_TS 转换为时间戳类型。
在 TRANSACTION_ID 上进行去重,保留最新的一行数据。
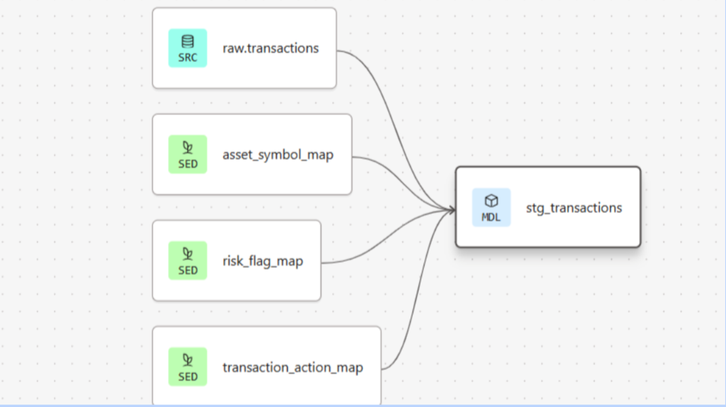
使用种子映射(如 asset_symbol_map、risk_flag_map、transaction_action_map)对分类字段进行标准化。
使用 dbt 测试强制执行相同的规则(唯一性、非空、接受的值)。
简而言之:数据概况转化为转换逻辑,而转换逻辑转化为测试。
心得体会
这个项目让我学到:数据概况是分析工程的起点。
为我提供了一个平滑的环境,可以检查和查询原始数据。dbt 给了我建模、测试和文档化修复的框架。它们结合在一起,形成了一个管道,将不可靠的模拟加密货币数据转化为值得信赖的数据。
数据可能很小,但工作流是分析工程师在大规模应用中使用的相同流程:从数据概况开始,带着明确目标进行建模,并通过测试强制执行数据质量。




