

自 2018 年 google 发布开源预训练模型 BERT 之后,一时席卷业内十余项任务的 state-of-art,引得无数 NLPer 聚焦于此。对于自然语言处理领域而言,BERT 的出现,彻底改变了预训练词向量与下游具体 NLP 任务的关系,因此 BERT 被称为改变了 NLP 游戏规则的工作。然而,究竟如何最好的使用 BERT 呢?
一种自然的方法当然是改变 BERT 的预训练过程,从而造出更好的预训练语言模型。这种方法可以简单的引入更多的语料、采用不同的预训练任务、采用多任务学习、采用在特定领域的语料上进行 fine-tune 等等。然而,从头训练甚至 fine-tune BERT 均需要大量的算力才可实现。那么另一种自然而然的想法是,我们是否可以将已有模型(LSTM 或者 CNN)接入到 BERT 之上,从而发挥二者各自的优势呢?这是本文介绍的重点。
BERT 的基础使用方式
本文以是否 fine-tune 预训练模型和是否对上层模型进行训练作为两个参考指标,将 BERT 的应用方法大致划分为三类,如下表所示:
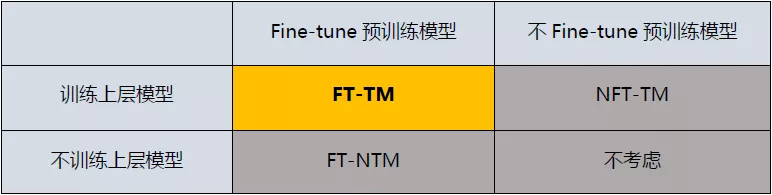
其中,方法 NFT-TM 是指在 BERT 模型的上层添加复杂的网络结构,在训练时,固定 BERT 的参数,仅单独训练上层任务模型网络。方法 FT-NTM 是指在在 BERT 模型后接一个简单的特定任务层(如全连接网络),在训练时,根据任务的训练样本集对 BERT 进行 fine-tune 即可。
就以上 NFT-TM、FT-NTM 两种方法,美国 Allen 人工智能研究所的 Matthew Peter 等人分别在 ELMo 及 BERT 两种预训练模型上对比了效果,希望能够得出到底哪个方式更适合下游任务,他们针对 7 项 NLP 任务给出实验结果。对于 ELMo 而言,使用上层网络进行特征提取效果更好,对于 BERT 而言,fine-tune 效果略胜一筹。最终该文得出结论,对于预训练模型,fine-tune 方法(即 FT-NTM)能够更好的将其应用于特定任务。
BERT 的高级使用方式
以上两种方法看上去有些片面,如果把特征抽取和 fine-tune 结合起来成为第三种模式,效果会怎样呢?在 BERT 出现之前,就有人在训练好语言模型之后,用后续网络(如 CNN,LSTM 等)对词嵌入进行微调的方法了。如果把预训练模型看作是一个词嵌入的强化版,那么在 BERT 时代,我们在追求其应用模式革新上也应该考虑到此方法,于是百分点认知智能实验室提出融合特征抽取及 fine-tune 的方法 FT-TM,其步骤如下:
在底层通过一个预训练模型,先训练一个可用的语言模型(视情况可停止训练);
针对具体下游任务设计神经网络结构,将其接在预训练模型之后;
联合训练包括预训练模型在内的整个神经网络,以此模式尝试进一步改善任务结果。
基于以上内容,我们对各种 BERT 应用方式选取了三个 NLP 典型任务进行实验,并通过实践证明,该方法在特定任务上均表现出色。
实验一:针对序列标注任务,我们选择了其子任务之一的命名实体识别任务(NER),并在 NER 的开源数据集 CoNLL03 上进行实验。该实验以仅对 BERT 进行 fine-tune(即方法 FT-NTM)的结果为 baseline,对比了在 BERT 基础上增加一个传统用于 NER 任务的 Bi-LSTM 网络(即方法 FT-TM)的效果,其实验结果如下图所示:

由图可得,结合 BERT 的 fine-tune 和上层神经网络的 FT-TM 方法在该任务上的 F1 值较 baseline 提升了近 7 个百分点。
实验二:针对文本分类任务,本次实验选取雅虎问答分类数据集,以原始 BERT 结果作为 baseline,对比了在其基础上分别连接了 HighwayLSTM 和 DenseNet 网络,并对其进行模型融合后的结果。实验结果由下图所示:
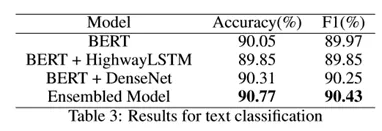
由实验看出,虽然模型融合后的效果并不十分明显,但也有一定的效果提升。
实验三:针对语义等价性任务,本实验选取包含了 40 万个问题对的“Quora-Question-Pair“数据集,根据句子对进行相似度的计算。本次实验将仅对 BERT 进行 fine-tune 的方法 FT-NTM 为 baseline,对比了在 BERT 之后接 BIMPM 网络的效果。同时以方法 NFT-TM 为 baseline,对比了两种改进 BIMPM 之后模型结构的效果(移除 BIMPM 中的第一层 Bi-LSTM 模型和将 BIMPM 的 matching 层与 transformer 相结合的模型)。注意,在模型训练时有个重要的 trick,考虑到预训练模型本身的效果和其与顶层模型的融合问题,在训练模型时,需要分两步进行:先固定预训练模型的参数,仅训练其上层特定任务网络,第二步再将整个网络联合训练。
该任务的实验结果如下图所示:

由实验结果可得,Bert+Sim-Transformer 结合 fine-tune Bert 的效果相较仅对 BERT 进行 fine-tune 的方法 FT-NTM,准确率提升了近 5 个百分点。
因此,从上面一系列的实验结果可以看出,我们提出的结合上层复杂模型和 fine-tune 的方法 FT-TM 是有效的,并且在某些任务中优于 fine-tune 的方式。同时在 BERT 预训练模型上面集成的神经网络模型好坏也会影响到最终的任务效果。
参考材料:
[1]Matthew Peters, Sebastian Ruder, and Noah A Smith. To tune or not to tune?adapting pretrained representations to diverse tasks. arXiv preprintarXiv:1903.05987, 2019.
论文地址:https://arxiv.org/abs/1907.05338
本文转载自公众号百分点(ID:baifendian_com)。
原文链接:
https://mp.weixin.qq.com/s/1OajAJx9vP81AQ7WCf4OFA

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论