

作者使用 macOS 系统的页大小就是
4KB,当然在不同的计算机上得到不同的结果是完全有可能的。
当我们需要在数据库中查询数据时,CPU 会发现当前数据位于磁盘而不是内存中,这时就会触发 I/O 操作将数据加载到内存中进行访问,数据的加载都是以页的维度进行加载的,然而将数据从磁盘读取到内存中所需要的成本是非常大的,普通磁盘(非 SSD)加载数据需要经过队列、寻道、旋转以及传输的这些过程,大概要花费 10ms 左右的时间。

我们在估算 MySQL 的查询时就可以使用 10ms 这个数量级对随机 I/O 占用的时间进行估算,这里想要说的是随机 I/O 对于 MySQL 的查询性能影响会非常大,而顺序读取磁盘中的数据时速度可以达到 40MB/s,这两者的性能差距有几个数量级,由此我们也应该尽量减少随机 I/O 的次数,这样才能提高性能。
B 树与 B+ 树的最大区别就是,B 树可以在非叶结点中存储数据,但是 B+ 树的所有数据其实都存储在叶子节点中,当一个表底层的数据结构是 B 树时,假设我们需要访问所有『大于 4,并且小于 9 的数据』:
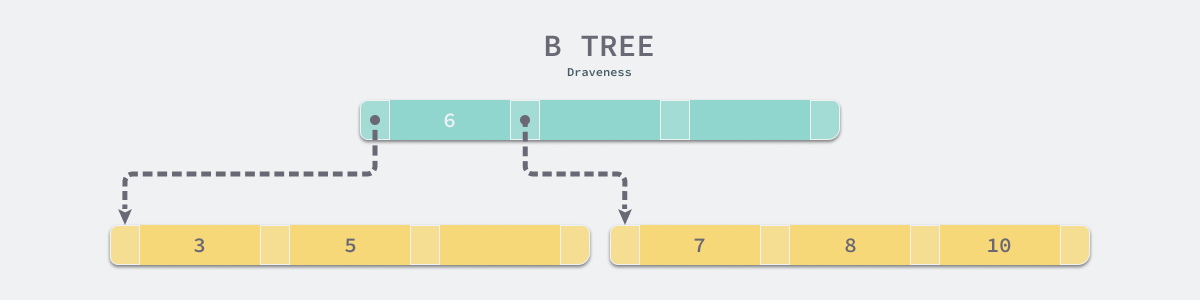
如果不考虑任何优化,在上面的简单 B 树中我们需要进行 4 次磁盘的随机 I/O 才能找到所有满足条件的数据行:
加载根节点所在的页,发现根节点的第一个元素是 6,大于 4;
通过根节点的指针加载左子节点所在的页,遍历页面中的数据,找到 5;
重新加载根节点所在的页,发现根节点不包含第二个元素;
通过根节点的指针加载右子节点所在的页,遍历页面中的数据,找到 7 和 8;
当然我们可以通过各种方式来对上述的过程进行优化,不过 B 树能做的优化 B+ 树基本都可以,所以我们不需要考虑优化 B 树而带来的收益,直接来看看什么样的优化 B+ 树可以做,而 B 树不行。
由于所有的节点都可能包含目标数据,我们总是要从根节点向下遍历子树查找满足条件的数据行,这个特点带来了大量的随机 I/O,也是 B 树最大的性能问题。
B+ 树中就不存在这个问题了,因为所有的数据行都存储在叶节点中,而这些叶节点可以通过『指针』依次按顺序连接,当我们在如下所示的 B+ 树遍历数据时可以直接在多个子节点之间进行跳转,这样能够节省大量的磁盘 I/O 时间,也不需要在不同层级的节点之间对数据进行拼接和排序;通过一个 B+ 树最左侧的叶子节点,我们可以像链表一样遍历整个树中的全部数据,我们也可以引入双向链表保证倒序遍历时的性能。
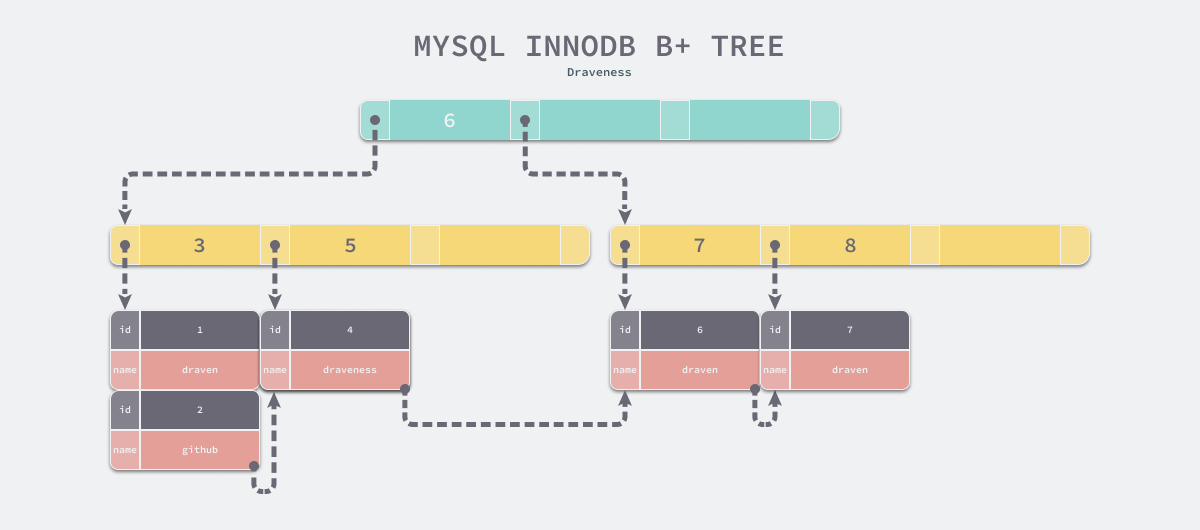
有些读者可能会认为使用 B+ 树这种数据结构会增加树的高度从而增加整体的耗时,然而高度为 3 的 B+ 树就能够存储千万级别的数据,实践中 B+ 树的高度最多也就 4 或者 5,所以这并不是影响性能的根本问题。
总结
任何不考虑应用场景的设计都不是最好的设计,当我们明确的定义了使用 MySQL 时的常见查询需求并理解场景之后,再对不同的数据结构进行选择就成了理所当然的事情,当然 B+ 树可能无法对所有 OLTP 场景下的查询都有着较好的性能,但是它能够解决大多数的问题。
我们在这里重新回顾一下 MySQL 默认的存储引擎选择 B+ 树而不是哈希或者 B 树的原因:
哈希虽然能够提供
O(1)的单数据行操作性能,但是对于范围查询和排序却无法很好地支持,最终导致全表扫描;B 树能够在非叶节点中存储数据,但是这也导致在查询连续数据时可能会带来更多的随机 I/O,而 B+ 树的所有叶节点可以通过指针相互连接,能够减少顺序遍历时产生的额外随机 I/O;
如果想要追求各方面的极致性能也不是没有可能,只是会带来更高的复杂度,我们可以为一张表同时建 B+ 树和哈希构成的存储结构,这样不同类型的查询就可以选择相对更快的数据结构,但是会导致更新和删除时需要操作多份数据。
从今天的角度来看,B+ 树可能不是 InnoDB 的最优选择,但是它一定是能够满足当时设计场景的需要,从 B+ 树作为数据库底层的存储结构到今天已经过了几十年的时间,我们不得不说优秀的工程设计确实有足够的生命力。而我们作为工程师,在选择数据库时也应该非常清楚地知道不同数据库适合的场景,因为软件工程中没有银弹。
到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:
常用于分析的 OLAP 数据库一般会使用什么样的数据结构存储数据?为什么?
Redis 是如何对数据进行持久化存储的?常见的数据结构都有什么?
如果对文章中的内容有疑问或者想要了解更多软件工程上一些设计决策背后的原因,可以在博客下面留言,作者会及时回复本文相关的疑问并选择其中合适的主题作为后续的内容。
Reference
相关文章
本文转载自 Draveness 技术博客。
原文链接:https://draveness.me/whys-the-design-mysql-b-plus-tree

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论