
9 月 16 日,OpenAI 正式推出一款新模型 GPT-5-Codex ,这是一个经过微调的 GPT-5 变体,专门为其各种 AI 辅助编程工具而设计。该公司表示,新模型 GPT-5-Codex 的“思考”时间比之前的模型更加动态,完成一项编码任务所需的时间从几秒到七个小时不等。因此,它在代理编码基准测试中表现更佳。
GPT-5-Codex 的发布,为近来“编码代理”(Coding Agents)领域或许最剧烈的一波氛围转折画上了句号。
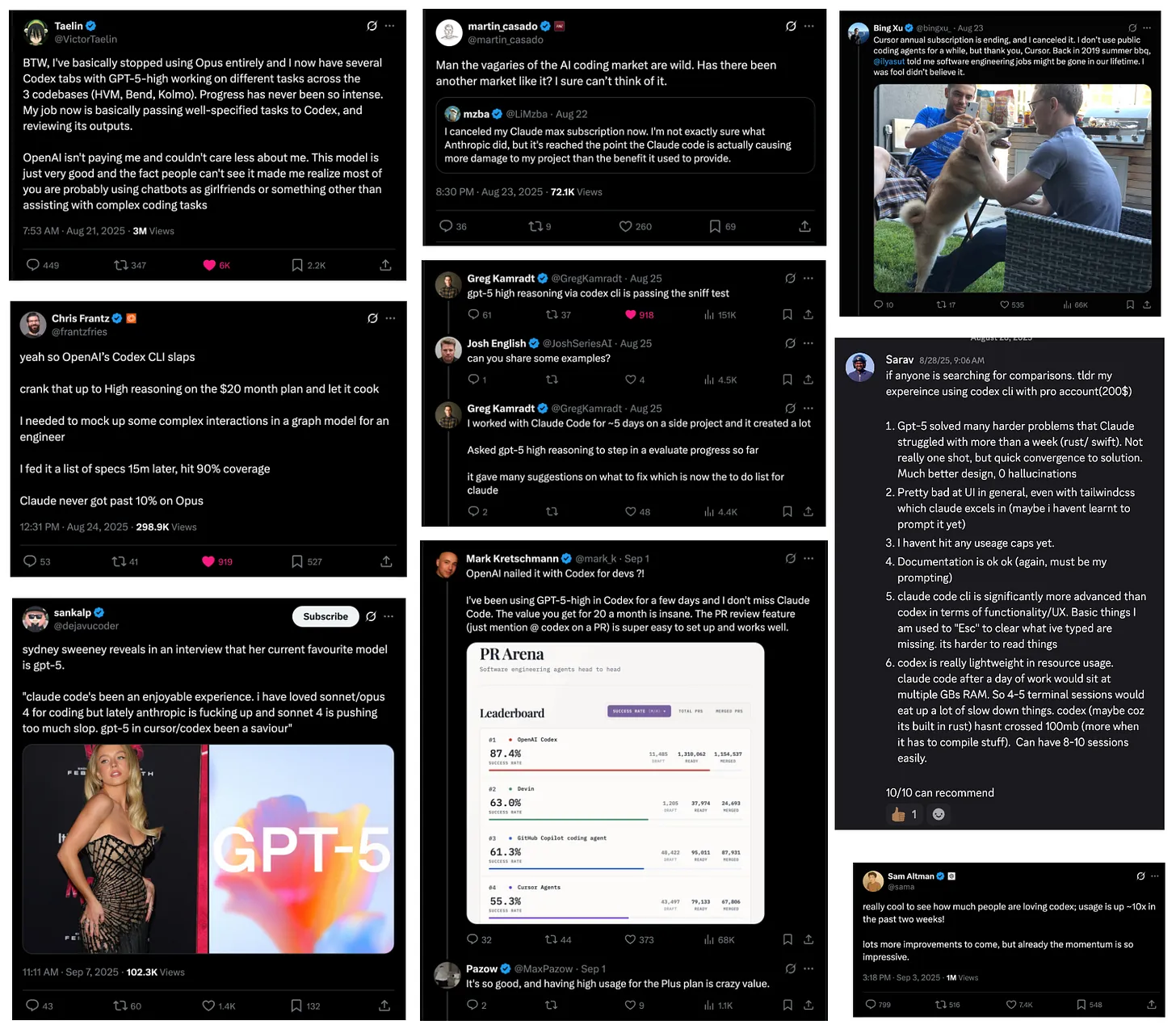
过去一年多里,从去年 6 月的 Claude 3.5 Sonnet、到 2 月的 3.7 Sonnet 与 Claude Code,再到 5 月的 Claude 4,Anthropic 在编码场景几乎是一骑绝尘,牢牢占据主导地位。期间公司营收一路飙升至 50 亿美元(其中 10% 来自 Claude Code),市值冲到 1830 亿美元,单单增加了 1220 亿美元市值。
这一切显然点燃了 OpenAI 的斗志。要知道,早在 2021 年,OpenAI 就发布了最初的 Codex,催生了 GitHub Copilot——全球第一个 AI 编程工具(如今仍有 182 位开发者在持续贡献);GPT-3 还启发了 Debuild,预示了后来所有的 vibe coding 创业潮。此后,OpenAI 也在 o1 和 GPT-4.1 中重新把编码能力放回优先级。
GPT-5-Codex 在 SWE-bench 上的得分是 74.5%,几乎与 GPT-5 thinking 在 477 子集上的 74.9% 持平。那么,是什么让 GPT-5 的整体口碑迎来大逆转?
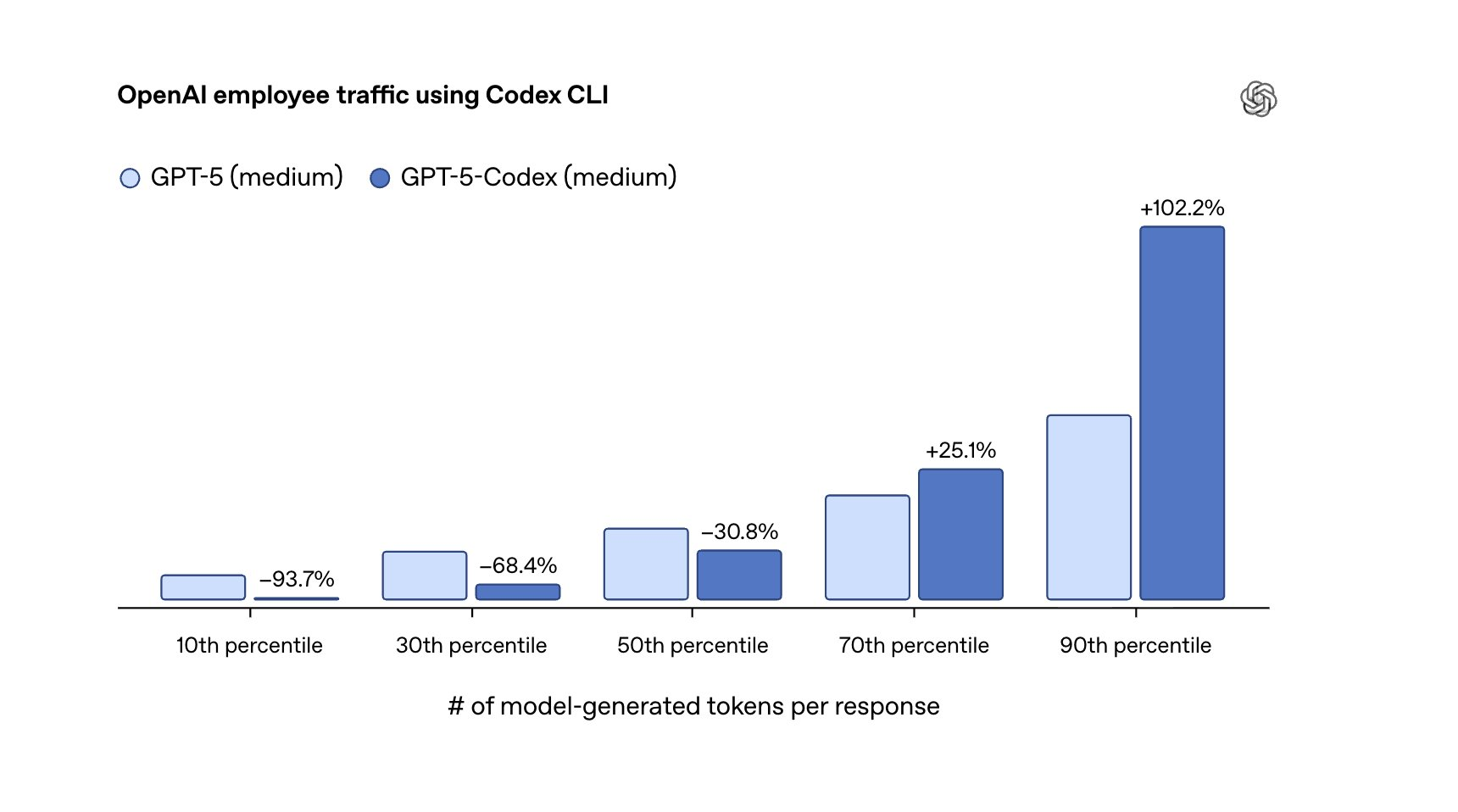
原因之一是:Codex 团队真的“在猛干活”。
其一是“多面统一”的代理。Greg 在今天的一个播客中提到:
“年初我们设定了一个公司目标:年底前做出一个代理式软件工程师。要弄清楚这到底意味着什么,如何实现,如何整合所有机会与算力,这是 OpenAI 许多人一起承担的一项巨大任务。”
最初的代理式 SWE 外壳叫做 10X,运行在终端里。如今,随着新 Codex CLI、“ChatGPT Codex”(现改名 Codex Cloud)、IDE 扩展(2.5 周安装量突破 80 万),以及 GitHub 代码审查机器人,OpenAI 已经形成了一整套覆盖各种需求的交互界面。
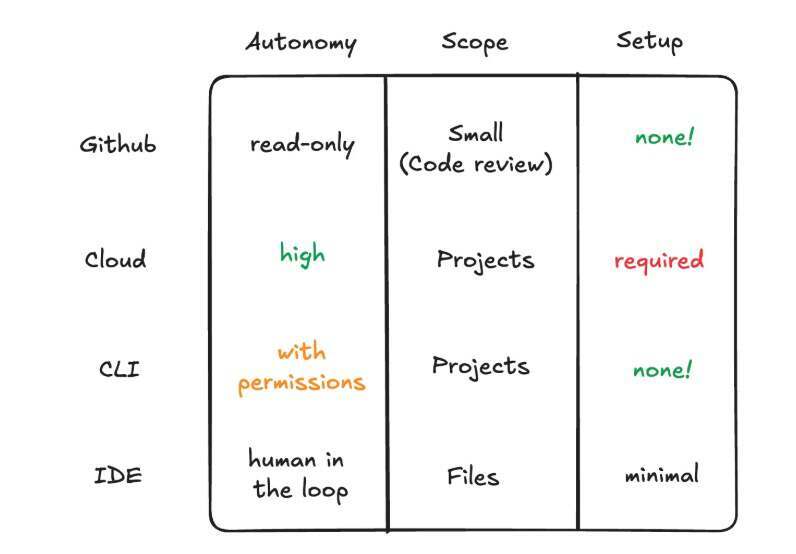
其二是更优的后训练特性。OpenAI 一贯强调研究与产品的紧密结合。今天的播客里也提到了几个重要特性,最重要的莫过于“长时间运行的代理任务”上的重大改进。

Thibault Sottiaux 说:
“这个模型展现出一种能力:能坚持更久,具备复杂重构任务所需的‘韧劲’。
但同时,对于简单任务,它响应得非常快,不用多想就能给出答案。这让它成为一个很好的合作者——你可以提问、定位代码、规划方案;而一旦放手,它就能长时间连续工作。
我们在内部见过它连续工作 7 小时完成复杂重构,这是此前从未有过的。我们也在代码质量上投入了巨大精力,它正是针对 Codex 用户的实际需求进行了优化。”
这种经过巧妙运用的“韧劲”,正是让 GPT-5-Codex 成为一个更全面、更实用的代理式编程模型的关键。它不只是针对最难的问题进行优化,然后逼得用户在较简单任务上切换到“更笨”的模型。


我们翻译了本次播客访谈的完整内容,带你深入了解 OpenAI 团队如何打造 GPT-5-Codex,以及它背后的技术与故事。
为何编程是 AGI 研究的特殊例外
Andrew Mayne:今天我们要聊 Codex。我其实从最早版本开始就用过它,那时候我还在这里工作。现在你们有了新版本,我整个周末都在玩,非常震撼,真的没想到短短几年内这项技术能进步到这个程度。我很想知道当初的起源故事:一开始怎么会想到用语言模型来写代码的?
Greg Brockman:我记得在 GPT-3 时代,第一次看到这种迹象:给一个 docstring,或者一个 Python 函数的定义,模型就能把代码补全。当你第一次看到这个的时候,就知道这东西一定能成,而且会很大。当时我们还谈过一些理想化的目标,比如说想象一下,如果语言模型能写出一千行连贯的代码,那就太惊人了。这就是我们当时的大目标。而现在,这个目标早已被实现并超越了。其实我们现在已经习惯了,都不觉得稀奇。但在研发过程中,你往往只看到模型的漏洞和缺陷。偶尔退一步去看,就会发现技术真的走了很远。
Thibault Sottiaux:是啊,令人难以置信的是我们人类多么习惯于这种持续的改进,它很快就变成了日常工具。每天都在用,然后回想一下,一个月前还根本不可能做到的事情,现在却已经习以为常。这真的挺令人着迷,人类对新事物的适应速度是如此之快。
Greg Brockman:不过我们一直有个困境,就是到底要不要在某个领域深耕。因为我们的使命是 AGI,通用智能。所以从直觉上说,我们是想把所有能力一视同仁地提升。但编程一直是个例外。
我们针对编程有完全不同的研究计划,专注在编程数据、代码指标,以及模型在代码任务上的表现。后来我们也开始在其他领域尝试这种方法。但对编程来说,我们一直都给予了特别的关注。
比如 GPT-4,我们最终推出了一个全能型的大模型,但其实我们也训练过 Codex 模型,还做过偏向 Python 的模型。在 2021 年左右,我们真的很努力地想把代码能力推到极限。当时我们做的 Codex 演示,或许就是今天所谓 Vibe coding 的最早雏形。
我还记得当时构建的交互界面让我突然意识到:普通语言模型的交互非常简单,就是补全一句话,或者接个对话。但代码不同,代码是要“活”的,要执行,要和工具连接。这时你就会发现,所谓的“交互外壳”(harness)本身,和智能模型本身一样重要,它决定了模型能不能真正用得起来。从那一刻起我们就明白了这一点。
今年我们用上了更强的模型,就不仅仅是去参加编程比赛、追求原始能力,而是要让它真的好用。于是我们在训练中引入多样化的环境,把模型和真实开发场景接起来,再配合合适的交互外壳。这也是 Thibault 和他的团队特别努力推进的方向。
Andrew Mayne:你能不能把 “harness” 用更简单的方式解释一下?
Thibault Sottiaux:其实很简单。模型本身只是一个输入—输出系统。所谓 harness,就是把它和其他基础设施集成起来,让它能真正作用于环境。这包括工具、循环方式,比如我们说的“agent loop”(代理循环)。单看起来其实很简单,但当你把这些部分真正端到端地结合起来训练时,你会看到一些很神奇的行为——模型能替你行动、创造,成为真正的合作者。你可以把它类比成:大脑是模型,而 harness 就是身体。
Andrew Mayne:没错,很有意思。想想 GPT-3 的时代,我们还得写带注释的代码,比如在 Python 函数前加 # 注释,告诉模型这函数是干什么的。而现在的模型已经能很自然、直觉地写代码了。你刚才提到过通用模型和编程专用模型的区别——这是因为用户需求很大,还是你们自己想要这样去用?
Greg Brockman:两者都有。比如在 2022 年,我们和 GitHub 合作推出了 Copilot。当时第一次真正感受到了 AI 进入编程工作流的感觉:它能加速你。但那时也有很多问题,比如界面设计该怎么做:要不要像 Ghost text 一样自动补全,还是要提供一个下拉菜单给不同选项?不过有一点很明确:延迟本身就是产品特性。自动补全的延迟门槛是 1500 毫秒,超过这个时间就没人愿意等了,再聪明也没用。所以当时的共识就是:在延迟限制内,用上最聪明的模型。但后来有了 GPT-4,它更聪明,但无法满足延迟要求。这时候怎么办?我们发现答案是:换 harness,换界面。你必须让交互方式和模型能力共同演化。
速度快又聪明的模型当然好,但就算是更聪明却慢一些的模型,也绝对值得,因为智能带来的回报在长期一定会显现。
Andrew Mayne:当年做 GitHub Copilot 的时候,我确实没能理解这个点。那时觉得只要模型能补全就行了,没意识到 harness 和工具的作用能带来这么大的差别。现在有了 CLI,比如 Codex CLI,我可以在命令行里用它,还有 VS Code 插件,甚至可以直接部署到网页上。我当时并不完全理解这些价值。你们自己是怎么用这些东西的?在哪些地方感觉最有用?
Thibault Sottiaux:回到一开始的观察:很多开发者在用 ChatGPT 调试非常复杂的问题。他们会不断尝试把更多上下文塞进去:代码片段、堆栈追踪,然后贴给模型求助。随着交互越来越复杂,我们突然意识到:与其让用户主导交互,不如让模型自己去找上下文、自己推理和调试,这样用户就能坐看模型干活。这个思路的转变,让我们开始更认真地思考 harness,并赋予模型自主行动的能力。
CLI、IDE 与终端:不同工具的适用场景
Greg Brockman:我们当时也在尝试不同的形态。年初时我们做过几种不同实现:比如异步的 agent harness,也做过本地体验。
Thibault Sottiaux:我们还在终端里跑过原型。后来觉得这还不够“AGI 味儿”,我们想让它能规模化、远程运行。你合上笔记本,它还能继续干活,你甚至可以用手机远程跟进。这感觉太酷了,所以我们就往那方向推进。但其实在终端里的版本是完全能用的,OpenAI 内部很多人也在高效使用。那个工具当时叫 “10X”,因为它真的让生产力提升了 10 倍。但最后我们没把它作为产品发布,因为感觉还不够打磨完善。
于是我们尝试更多形态,先重点做异步。现在我们又回过头,把 agent 带回到终端和 IDE。最终的目标是把它变成你身边的一个协作者,并且嵌入到你已经在用的开发工具里。
Greg Brockman:我们还做过其他尝试,比如远程守护进程连接本地 agent,这样能两者兼得。其实我们发现,这里几乎是一个“形态矩阵”,可以异步、可以本地同步、也可以混合。问题在于我们到底该把重心放在什么地方:是做成通用的、能适配各种环境的外部化工具,还是先专注在内部环境,把内部工程师的体验做到极致?我们当然都想做。但如果自己都用不好,又怎么可能让全世界都用得好呢?这就是我们的挑战,要找准聚焦点,让工程努力产生最大价值。
今年我们确立的一个公司目标就是:年底前做出一个“代理式软件工程师”。这意味着什么?怎么实现?怎么把资源和算力投入其中?这是一个庞大的工程,很多人都在为此努力。
Andrew Mayne:你刚提到 “10X” 这个内部工具,它看起来非常有用,但你们最终没有对外发布。这类决策一定很难吧?什么时候应该公开,什么时候不该?像云端代码现在非常强大,我猜也是类似的故事——先内部使用,然后再对外部署。那接下来你们是怎么判断重点放在哪里的?比如能在云端跑、能做类 agent 的任务,我走开它就继续干。但对我来说,这种新形态太新了,很难完全理解。有时这些东西需要先沉淀一段时间,人们才会慢慢发现价值。你们内部有人有类似的“啊哈时刻”吗?
Greg Brockman:当然有。我觉得我们已经能大致勾勒未来的样子了:未来你肯定会想要一个拥有自己电脑的 AI,它能调用一批代理并行完成任务。你早上起来,喝着咖啡,顺手给它点反馈,比如“这个结果不对”或者“流程需要这样改”。但模型还没聪明到让这种交互成为日常。所以现在,模型依然需要在你的终端、在你的编辑器里,贴近你原本的工作方式来帮忙。这就是当下。
对我们来说,现在和未来是交织的:一方面要把 AI 带入代码审查、主动帮你生成有用的内容;另一方面,更多的 PR 也带来新挑战,比如你要如何筛选出真正值得合并的?这些机会都摆在眼前,我们也看到 OpenAI 内部的开发模式、代码库结构都开始因而发生变化。
Thibault Sottiaux:是的,背后有两个关键点。第一,基础设施真的很难。我们当然希望所有代码、任务、包都能完美容器化,这样就能规模化运行。但现实是,很多人都有复杂的环境配置,只能在他们自己的笔记本上跑。
我们希望能够利用(用户现有的环境),在用户所在之处与他们“会合”,这样他们就不必为了 Codex 去做特定配置。这样就能给大家一个非常容易上手的入口,让你直接体验到一个强大的编码代理能为你做什么。
同时,这也让我们可以去试验“正确的交互界面”应该是什么样子的。六个月前,我们还没在玩这些类型的工具。一切都非常新,而且在快速演进。
我们必须持续在这方面迭代和创新——到底什么是合适的界面、怎样才是和这些代理协作的正确方式。老实说,我们还没觉得已经把它打磨到位了,这还会继续演进。但把它做成零配置、开箱即用、极易上手,就能让更多人从中受益、愿意去尝试。对我们来说,这还能带来反馈,帮助我们持续创新——这非常重要。
Greg Brockman:我记得年初我和我们的一位工程师聊天,他非常出色。他说,ChatGPT 有一个集成,可以自动看到终端里的上下文。他说这是颠覆性的,因为他不再需要复制粘贴错误信息了。他可以立刻问:“嘿,问题出在哪?”然后它就能告诉他,效果非常好。你会意识到,这是我们做的一个集成本身带来的巨大改变,并不只是因为模型更聪明。
我觉得很容易被其中某一个维度吸引,只盯着它,问“到底哪个更重要?”但答案是:两者都重要。回想我们在 2020 年最初发布 API 时,我一直是这么想的:一个 AI 的“可取性”有两个维度。一是智能,可以把它看作一个轴向;二是便利性,你可以把它理解为延迟、成本,或者它可用的集成能力。
这两者之间存在一个“可接受区域”。比如说,如果一个模型非常非常聪明,但要运行一个月才能出结果——你可能还是会用,如果它能产出极其有价值的代码,或者某种疾病的解药之类的成果,那也值得。相反,如果模型并不那么智能、能力有限,那你可能只想用它做自动补全。这时它就必须极其方便——几乎不给你带来任何认知负担地给出建议,类似这种。
而我们现在所处的位置,当然是在这个谱系上的某个点。我们有更聪明的模型,它们没有自动补全那么方便,但又比“等一个月才出答案”要方便得多。所以我们的挑战之一,就是搞清楚:什么时候该投资把“便利性”往左拉(更低延迟、更低成本、更好集成),什么时候该投资把“智能”往上推。这是一个巨大的设计空间,也正是它有趣的地方。
Andrew Mayne:是啊。我不知道你还记不记得,我在 2020 年做了一个在发布会上上过推荐的应用,叫 AI Channels。当时的挑战是,GPT-3 应用的能力很强,但我得写六百字的提示词才能让它干活。以每千 token 六美分的价格、再加上延迟,我当时觉得:这还不是适合它的世界。后来有了 GPT-3.5 和 GPT-4,你就一下子看到了那些能力。我很难说清楚为什么,但你能感受到一切都配合起来了。你刚刚也提到过,让模型能在你工作的地方看见上下文这件事。我记得我当时把内容从 ChatGPT 里复制粘贴到工作区,就像走进超市却拒绝拿购物车,抱着所有东西走到收银台——极其低效。一旦你把东西放到带轮子的车上,就顺畅多了。我觉得我们现在正看到各种这样的“解锁”。
而我现在面临的问题是:我坐下来要干活时,我该进 CLI 吗?用 VS Code 插件?还是用 Cursor?抑或是别的工具?你们是怎么做选择的?
Thibault Sottiaux:就现在而言,我们仍处在实验阶段,尝试不同的方式让你去和代理互动,并把它带到你已经高效的地方。比如,Codex 现在已经进入了 GitHub。你可以 @Codex,它就会替你干活。如果你写“@Codex,修这个 bug”或“把测试挪到这里”,它就会跑起来,在我们数据中心自己的“小笔记本”(独立计算资源)上去执行这些任务,你不需要操心。
但如果你是在一个文件夹里和文件打交道,那你就会面临一个选择:是在 IDE 里干,还是在终端里干?
我们观察到,资深用户在终端里发展出了非常复杂的工作流;而当你实打实地处理某个文件或项目时,你更偏好在 IDE 里做,因为界面更精致:你可以撤销、更直观看到编辑,不会只是从屏幕上“刷刷地滚过去”。
同时,终端又是一个很棒的“vibe coding”工具:如果你并不那么在意产出的具体代码本身,你可以就地生成一个小应用。那更像是把关注点放在互动与结果上,而不是具体代码文本。总之这还是一个“看你要做什么”的问题,但现在确实还是实验阶段,我们在尝试不同的方式,我想这还会持续一段时间。
Greg Brockman:我完全同意。我也认为,我们未来的方向会是把这些东西做得更加一体化。大家本来就会用多种工具:终端、浏览器、GitHub 网页界面、本地机器上的仓库……每个工具都有大家“何时该用它”的经验法则。因为我们还在实验阶段,所以这些东西看起来会彼此割裂、差异很大,你好像得去学一套新技能,理解每个工具的“可供性”(affordances)。
在我们迭代时,重要的是要认真思考它们彼此之间如何契合。你已经能看出一些趋势了:比如 Codex 的 IDE 扩展可以运行远程的 Codex 任务。我想,我们最终的愿景是:应该有一个 AI,既能使用它自己的电脑、自己的集群,也能“看着你的肩膀”在本地帮你。这两者不该是割裂的。
Thibault Sottiaux:对,我们把它想成一个“单一的编码实体”,始终在那儿帮助你、和你协作。就像我和 Greg 合作——有时我们在 Slack 上聊,有时当面交流……有时我们通过 GitHub 评审互动。和其他人类合作者互动时,这一切都很自然。我们对 Codex 的设想也是这样:一个具有代理特性的实体,真正意义上在你实现目标时为你“加速”。
代理记忆的局限
Andrew Mayne:那我们来聊聊一些使用方式,比如 agents.md。你能解释一下吗?
Thibault Sottiaux:好的。agents.md 是一组你可以提供给 Codex 的指令文件,它和你的代码放在一起。这样 Codex 就能多一点上下文,知道怎样更好地在代码库里导航并完成任务。
我们发现有两类内容放在 agents.md 里特别有用:第一,类似“压缩”的东西——对于代理来说,直接读 codex.md(原文如此)会更高效一些,而不必把整个代码库都探索一遍;第二,是那些在代码库本身并不明确表达的“偏好”,例如:测试其实应该放到这里,或者“我喜欢以某种特定方式来做事”。这两类东西——偏好,以及如何高效在代码库中导航的说明——都是非常适合写进 agents.md 的。
Greg Brockman:这里有一个很根本的问题:你如何把“你想要什么、你的偏好是什么”传达给一个“无上下文”的代理,同时替它节省掉一些人类上手时需要的“热身”过程?我们对人是这么做的——写 readme.md。而 agents.md 只是一个约定俗成的文件名,告诉代理“应该去看它”。
但这也反映了一个“时间点上的现实”:当前的代理记忆能力并不好。比如你第十次运行代理,它真的从前九次给你解决难题的经历里获益了吗?所以我们确实有研究要做:怎样让它拥有记忆?怎样让一个代理真正去探索你的代码库、深刻理解它,然后把这些知识利用起来?这只是众多例子中的一个,但我们已经能看到在这些方向上有很多“触手可及”的研究成果在前方等着我们。
迁移与审查
Andrew Mayne:现在竞争格局非常激烈。曾经有一段时间,OpenAI 对很多人来说几乎是横空出世——突然就有了 GPT-3,然后是 GPT-4。现在 Anthropic 在做很棒的模型,谷歌的 Gemini 也很强。你们怎么看待这个版图?你们觉得自己的位置在哪里?
Greg Brockman:我认为还有很多进步空间。我更少去关注竞争,而是更多去关注潜力。因为我们在 2015 年创办 OpenAI 时,就认为 AGI 会比人们预期更早到来。我们只是希望在这一进程中能发挥积极作用。而这意味着什么、如何把它落实到实际执行,一直是我们要思考的核心任务。
所以当我们开始摸索如何构建真正有用、能帮助人们的模型时,把它真正带到人们手中就成了至关重要的事。你可以看看我们一路上做出的选择,比如推出 ChatGPT,并且提供广泛的免费使用。这是出于我们的使命——我们希望 AI 是人人可得、能惠及所有人。
在我看来,最重要的是保持这种指数级的进步,并且不断思考如何以积极、有用的方式带给大家。比如现在,我们有了 GPT-4 这一类预训练模型,再叠加强化学习,使其更可靠、更智能。想象一下:如果你只是“读过互联网”,只是观察过人类思维的碎片,然后第一次尝试写代码,你可能会很糟糕。但如果你能亲手去解一些棘手的编程问题,有 Python 解释器,有和人类一样的工具,那么你就能变得更加健壮和精炼。
现在我们让这些部分组合在一起,但必须继续推向下一层级。很明显,比如大规模重构代码库——目前还没人真正攻克。但这没有什么根本上的障碍。一旦解决,我觉得这会是企业级的“杀手级应用”。
想象一下,如果代码迁移的成本降低一半,那么可能会让迁移的数量增加十倍。再比如 COBOL,如今仍有大量系统困在 COBOL 里,可是已经没有新的 COBOL 程序员在培养了。这只会成为全世界的风险与负担。唯一的出路就是构建能够真正应对这种问题的系统。这是一个巨大的开放空间。指数曲线会继续下去,而我们必须跟上。
Andrew Mayne:我今天最喜欢的一个小插曲,是看到 OpenAI 发了一条推文,教大家如何在 CLI 中把 completions API 切换到 responses API。
Thibault Sottiaux:这是一个非常好的用法。我预计未来会有更多类似的场景——你给 Codex 特别的指令,让它可靠地执行重构,然后它就自己跑完。这太棒了。迁移真的是最糟心的事之一。没人愿意做迁移。没人想从一个库切换到另一个库,还要保证一切正常。如果我们能把大部分工作自动化,那会是一项非常美妙的贡献。
Greg Brockman:我觉得还有很多其他方向。比如安全补丁,这会很快变得重要,我们现在也很重视。另外,AI 还能生成新工具。想想 Unix 工具集的重要性——如果 AI 能为你构建工具,甚至为自己构建工具,就能搭建起一个复杂度与实用性不断提升的阶梯,推动效率飞轮持续运转。未来的 AI 不仅能写代码,还能执行自己的代码,管理服务,甚至做 SRE(站点可靠性工程)类的工作。这些都在地平线上,已经在开始发生,但还没到我们理想中的状态。
Thibault Sottiaux:我们在 OpenAI 内部解决的一个大问题是代码审查。
我们发现,随着代码量增长,瓶颈在于团队要处理的审查任务太多。于是我们专门打造了一个高信号的 Codex 模式,能对 PR(合并请求)进行深入审查,理解开发者的设计意图,再去验证代码是否实现了这个意图。它还能逐层深入,检查依赖关系,思考契约逻辑,指出一些即使是最优秀的审查员也要花上数小时才能发现的问题。
我们先在内部上线,效果非常成功。当它挂掉时,大家甚至很不满,因为觉得失去了安全网。它极大加速了团队,包括 Codex 团队本身。就在我们发布 IDE 扩展的前一晚,我的一位顶尖工程师提交了 25 个 PR。我们自动发现了不少 bug——Codex 找出了许多问题。第二天我们发布的 IDE 扩展几乎没有 bug,速度快得惊人。
Greg Brockman:很有意思的是,关于代码审查工具,人们一开始都很紧张。因为过去我们试过的所有自动审查实验,结果都是“噪音”——你收到一封来自机器的邮件,只觉得烦人,然后选择忽略。但现在我们看到完全相反的结果。
这说明,当能力低于某个阈值时,它就是净负担;可一旦超过阈值,人们就会主动需要它,甚至失去了还会很不满。我们的观察是:如果某个 AI 功能现在只是“有点用”,那么一年后它就会变得极其可靠、成为任务关键。这正是代码审查的发展方向。
Thibault Sottiaux:代码审查还有个很有意思的地方,就是要把人类一起带上,让它成为合作者。我们思考了很多,怎样才能让审查结果让你愿意去读,甚至觉得有收获——哪怕它偶尔错了。你能理解它的推理逻辑。而事实上,它超过九成的情况是正确的。就算你是代码作者或审查者,也常常能从中学到东西。
Greg Brockman:回到我们之前说的“进步速度”。想想 GPT-3 和 GPT-4,当时我们还很关注“双倍确认”的问题:AI 说错了,你指出来,它却会和你争论。
Andrew Mayne:对,它会坚持说自己对。
Greg Brockman:是啊。但我们现在早已远离那个阶段了。当然,在极少数边缘情况里还会发生,就像人类也会。但令人惊叹的是,我们已经到了这样一个水平:即使它没有完全抓住重点,它也能指出有价值的东西,提出合理的思路。我每次看完这些代码审查,都会觉得:“嗯,这说得对,我应该考虑一下。”
GPT-5 Codex 的“七小时奇迹”
Andrew Mayne:说说我们为什么该为 GPT-5 Codex 感到兴奋?
Thibault Sottiaux:GPT-5 Codex 是 GPT-5 的一个版本,我们针对 Codex 做了优化。刚才我们提到过 harness(交互外壳),它就是针对 harness 优化的。我们把它视作一个紧密结合模型与工具的单一代理,因此更可靠。
其中一个显著特点是,它能坚持更长时间,具备处理复杂重构任务所需的“韧劲”。同时,对于简单任务,它响应得更快,不用深思熟虑就能直接答复。
它是一个很好的合作者:你可以问它关于代码的问题,让它帮你找出需要修改的部分,或者帮你理解与规划。而一旦你放手让它去做某个任务,它能长时间坚持。
我们在内部看到它最长连续工作 7 小时,完成非常复杂的重构,以前没见过其他模型做到这一点。我们也在代码质量上下了很大功夫。它就是为人们在 Codex 中的使用场景做了最优优化。
Andrew Mayne:当你说它能坚持七小时,不只是不断把上下文塞回去,而是它真的在做决策、判断重要性并往前推进?
Thibault Sottiaux:是的。想象一个特别棘手的重构。我们都经历过:代码库已经无法维护了,你必须做一些修改才能继续前进。这时你做个计划,然后交给 GPT-5 Codex,它就会一步步解决所有问题,让测试能跑通,最终完成整个重构。这就是我们看到它连续工作七小时完成的事例。
Greg Brockman:让我惊叹的是,这些模型的核心智能已经如此强大。三到六个月前,它们就已经比我更擅长在内部代码库里找到特定功能了。而这需要相当复杂的能力。
Andrew Mayne:那你是不是该“让位”了?比如说:“Greg,对不起了……”
Greg Brockman:(笑)但事实是,我能去做更多别的事。我想让人们认识我,不是因为我会在代码库里找功能点。这不是我定义自己工程价值的方式。我更想花时间去思考架构,去决定要跑多少个代理、分配到哪些任务。这就是我认为的核心价值:AI 能接管那些枯燥琐碎的部分,也能在有趣的部分成为合作伙伴。
我可以选择如何分配我的精力。我是个死忠 Emacs 用户,但我也用 VS Code、Cursor、Windsurf 这些工具,一方面是为了尝试,另一方面也是喜欢工具的多样性。但要把我从终端里拽出来很难。不过现在我们已经到了那个临界点:当我在重构时,我会想“我为什么要自己打这些东西?为什么要去回忆某个语法?”这都是机械的事情。我希望有个实习生帮我干,而现在我在终端里就有了这么个实习生。我觉得这真的很了不起。
Andrew Mayne:那我们来聊聊未来吧。你们怎么看?代理化的未来里,最让人兴奋的是什么?我们将如何使用这些系统?
Thibault Sottiaux:我们非常确信,未来的形态会是:在云端有大量代理组成的群体,由人类、团队、组织来监督和引导,创造巨大的经济价值。往后几年,这就是画面:数百万代理在公司和组织的数据中心里做有用的工作。
问题在于:我们如何一步步走到那里?如何找到合适的形态、正确的交互模式?其中一个必须解决的重大问题就是安全、保障和对齐。代理必须能做有用的工作,但必须以安全的方式。你始终要作为操作者、作为人类保持掌控。这就是为什么在 Codex CLI 里,代理默认在沙箱中运行,它不能随意修改你电脑上的文件。我们会持续投入很多努力,让环境安全,理解何时需要人类介入和批准某些操作,并逐步赋予更多权限。你的代理会有一组你允许它使用的权限,必要时还能在你的许可下“升级”,执行那些更高风险的操作。
Thibault Sottiaux:所以,要搞清楚整个系统,然后把它变成多代理(multi-agent),让个人、团队、组织都能去引导,并且与组织整体目标保持一致——这就是我认为的发展方向。虽然有点抽象,但我觉得非常令人兴奋。
Greg Brockman:是的,我完全同意。我觉得在更细的层面上,有很多技术问题需要解决。比如 Thibault 提到的“可扩展监督”问题——人类该如何管理那些不断产出大量代码的代理?你大概不会想去读每一行代码。事实上,现在大多数人也不会逐行看这些系统产出的代码。那么如何维持信任?如何确保 AI 产出的东西确实是正确的?
我认为这里有一些技术途径。我们从 2017 年起就在思考这些问题,当时我们首次发表了一些策略,探讨如何让人类或较弱的 AI 去监督更强的 AI,并通过这种方式逐步建立起信任和监督,确保即使在它们执行高难度、重要任务时,我们依然能掌握方向盘。这是一个非常重要的问题,而在开发更强大的编码代理时,它也有着非常实际的体现。
但我认为还有一些容易被忽略的维度。每到一个 AI 能力层级,人们就容易过拟合,觉得“啊,这就是 AI,将来也就是这样”。但我们还没有真正看到的是——AI 解决那些真正全新、困难的问题。现在大家想到的更多是“我需要重构代码”,你至少知道大致是什么样子,AI 会帮你完成很多工作,节省大量时间。但如果是那些根本无法用其他手段解决的问题呢?
我想到的不仅是编程领域,还包括医学,比如研发新药;材料科学,比如创造出具有全新特性的材料。我认为很快就会出现能够解锁这些应用的新能力。对我来说,一个重要的里程碑将是:当 AI 产出的成果本身极具价值和意义,不是因为它便宜,也不是因为它是 AI 产出的,而是因为它就是一项突破性的成果。即便不是 AI 独立完成,而是在人类协作下,AI 扮演了关键角色。
我们已经开始看到一些迹象。例如在生命科学领域,研究人员会让 o3 提出五个实验方案,他们尝试之后,四个失败,一个成功。而反馈是:结果大约相当于一个三、四年级博士生的水平,这简直令人惊讶——而这还是在 o3 时代。到了 GPT-5 和 GPT-5 Pro,我们看到的情况完全不同。科研人员会说:“好,这是真正在做新颖研究。”有时它并不是独立解决重大理论,而是与人类合作,把能力延伸到人类单独无法达到的地方。对我来说,这正是我们必须持续推进并做对的关键。
未来的软件工程
Andrew Mayne:我和人们谈未来时常遇到一个挑战:大家想象未来,总是把它看作是“披着闪亮外壳的现在”,比如有机器人,或者机器人写所有的代码。但你们刚刚提到,有些事是你喜欢做的,有些事是你不愿做的。那 2030 年会是什么样子?五年前是 GPT-3,那五年后呢?
Thibault Sottiaux:六个月前我们甚至都没有这些工具,所以要准确想象五年后的样子真的很难。但有一点很重要:那些作为关键基础设施、支撑整个社会运行的代码,我们需要持续去理解,并拥有工具去理解。这也是我们重视代码审查的原因——代码审查应当帮助你理解代码,成为一个队友,帮助你深入别人写的代码,甚至包括 AI 写的代码。
Greg Brockman:实际上我会说,我们已经存在一个问题:外面有很多代码并不安全。这种情况时常发生。我记得大约 12 年前的 Heartbleed 漏洞,那是互联网广泛使用的核心软件中的一个严重漏洞。而且你会意识到,这不是个别现象,类似的漏洞还有很多,只是没人发现。
Andrew Mayne:对啊,还有那么多 NPM 包,很多都被放着,可能有人往里塞了恶意代码。
Greg Brockman:没错。以往一直是攻防猫鼠游戏:攻击者越来越高级,防御者也越来越强。而有了 AI,你会想:到底哪一方会更有优势?可能它会加速这种猫鼠循环。但我觉得也有希望通过 AI 解锁全新的防御能力。比如形式化验证(formal verification),这可能就是防御的“终局”。让我兴奋的是:不只是延续这种无休止的竞赛,而是能带来更高的稳定性和可理解性。我认为在其他方面也会有类似机会,让我们以全新的方式理解系统。现在很多传统软件系统几乎已经逼近人类理解的边界了。
Thibault Sottiaux:我们构建 Codex 的原因之一,就是改善基础设施和现有代码,而不是单纯增加世界上的代码量。这一点非常重要。Codex 能帮助发现 bug,帮助重构,帮助找到更优雅、更高效的实现方式——达到同样的目标,甚至更通用,而不是制造出 1 亿行没人能看懂的代码。让我兴奋的是,Codex 能帮助团队和个人写出更好的代码,成为更优秀的软件工程师,最终创造出更简洁却能完成更多事情的系统。
Greg Brockman:我觉得 2030 年的一个重要图景是:我们将生活在一个“物质极大丰富”的世界。AI 会让创造任何你想要的东西,比你想象中容易得多——这可能不仅在数字世界,在物理世界里也会如此。
但同时,这将是一个“算力极度稀缺”的世界。我们在 OpenAI 内部已经感受到一点:不同研究项目为了算力争抢,研究成败常常取决于算力分配,这种情况的严重性难以言表。
我认为未来也会如此:你的创造力不仅受想象力限制,还会受限于算力。因此我们常常思考:怎样增加世界上的算力供应?我们既要提高智能水平,也要提升智能的可用性。而这归根到底是一个物理基础设施问题,而不仅仅是软件问题。
Thibault Sottiaux:我觉得 GPT-5 很惊人的是,我们能把它作为免费、Plus 以及 Pro 套餐的一部分提供。比如说,你订阅 Plus,就能用 Codex,也能用 GPT-5,就是大家用的同一个版本。而且它在这种方式下也非常高效。
Andrew Mayne:让我印象深刻的是:我觉得这个模型功能更强大,但价格和之前一样,甚至更低。这让我大吃一惊。
Greg Brockman:是的。我们在提升智能的同时,价格也在大幅下降。这其实很容易被忽略,但真的很疯狂。比如我们对 o3 做过 80% 的降价。回想 GPT-3 的时代,还是每千 token 六美分。
Andrew Mayne:对,最近有篇报道在抱怨,说“推理模型”更贵了。但他们没把推理模型和过去六七个月的新推理模型相比,也没看到它们效率提高了多少。
Greg Brockman:没错。而且这种趋势会持续。说到算力稀缺,我觉得有一个迹象很明显:现在大家在谈上百万 GPU 的集群。但未来可能很快就会变成:每个人都需要有一个专属 GPU 来运行他们的代理。这样算下来,我们可能需要接近 100 亿个 GPU。我们距离那个目标还差几个数量级。所以我们的工作之一,就是想办法增加算力供应,让它真实存在,同时在当前有限的算力下尽可能榨出最大价值。这既是效率问题,也是智能提升问题。但很明确,要把它真正实现出来,需要大量的工作与建设。
Thibault Sottiaux:还有一点有趣的是,代理与 GPU 的关系。如果 GPU 靠近用户会带来巨大好处。因为当代理执行时,它可能在几分钟里调用两百次工具,每一次都需要 GPU 和你的笔记本往返执行。如果 GPU 离你更近,延迟就会大幅降低,整个交互和运行过程都会更顺畅。
Andrew Mayne:我们时常被问到关于未来和劳动力的问题:学不学编程?
Thibault Sottiaux:我觉得现在是学习编程的绝佳时机。
Greg Brockman:我同意。一定要学编程,但更要学会使用 AI。这才是最重要的。
Thibault Sottiaux:用 Codex 学一门新语言非常有趣。我们团队里有不少人之前不懂 Rust,但我们决定用 Rust 来写核心 harness。结果他们借助 Codex 提问、探索陌生的代码库,很快就掌握了,还取得了很棒的成果。当然,我们也有经验丰富的 Rust 工程师来指导,确保质量。但总的来说,现在真的是学习编程的好时机。
Greg Brockman:我记得自己最初学编程时用的是 W3Schools 的教程,学 PHP、JavaScript、HTML、CSS。我当时在写第一个应用时,想实现数据序列化,但甚至不知道“序列化”这个词。我就自己设计了一种特殊字符序列作为分隔符。但如果数据里本身就包含这个序列呢?那就惨了(笑)。这种问题,教程里不会提醒你。但 Codex 在代码审查时就会告诉你:“嘿,有 JSON 序列化库,用这个就行。”所以我觉得编程的门槛会越来越低,你不用重新发明轮子,它还能替你提出你自己都没想到的问题,并给你答案。这就是为什么我觉得现在是最适合动手创造的时代。
Andrew Mayne:我也常常通过看它怎么解题学到很多,发现新的库、新的方法。我有时会给它很疯狂的任务,比如:只用一千行代码写一个语言模型,它会怎么做?有时它会失败,但你能看到它尝试的方向,然后会发现:“啊,原来还有这种办法。”
Thibault Sottiaux:我注意到,那些最会用 AI 编程的人,往往有坚实的软件工程基础。他们设计了合理的架构,搭好了代码框架,再让 AI 来帮忙,这样就能跑得更远。如果对代码本身一无所知,你就无法走到这一步。
Andrew Mayne:自从你们上线 GPT-5、能用 Codex 部署以来,使用情况如何?
Thibault Sottiaux:使用量爆炸式增长。总体增长超过 10 倍,原本就在用的用户也用得更多了,场景更复杂,时间更长。我们现在把它纳入 Plus 和 Pro 套餐里,额度也很大,这也推动了成功。
Greg Brockman:我觉得“氛围”也在转变。人们开始意识到,GPT-5 要怎么用才最合适。我们有自己一套交互外壳和工具的组合方式。一旦用户理解了这种方式,他们的效率就会极快提升。
Andrew Mayne:非常感谢两位今天来聊这些。最后还有什么想说的吗?
Greg Brockman:谢谢邀请!我们对接下来的发展非常兴奋。还有很多东西要去构建。指数级进步还在继续。而让这些工具变得人人可用、真正有用,正是我们的使命。
Thibault Sottiaux:是的,谢谢邀请!我也特别兴奋。Codex 不断进步,我们的研发速度也在加快,每天都在做更好的 Codex。就我个人而言,我现在花在和 Codex 对话上的时间可能比大多数人都多。这让我真切地感受到 AGI 的存在,也希望更多人能从中受益。
参考链接:




