
北京时间 4 月 19 日,Meta 官宣发布了其最先进开源大型语言模型的下一代产品——Llama 3。
据悉,Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据,提供了 80 亿和 700 亿的预训练和指令微调版本。
Meta 在官方博客中表示,“得益于预训练和后训练的改进,我们的预训练和指令微调模型是目前 80 亿 和 700 亿 参数尺度下最好的模型。”
最大 4000 亿参数,性能直逼 GPT-4
值得注意的是,此次的大模型通过后期训练程序上的改进很大程度上降低了 Llama 3 的错误拒绝率,提高了对齐度,并增加了模型响应的多样性。Meta 研发团队还发现,推理、代码生成和指令跟随等能力也有了很大提高,这使得 Llama 3 的可操控性更强。
80 亿参数模型与 Gemma 7B 和 Mistral 7B Instruct 等模型相比在 MMLU、GPQA、HumanEval 等多项基准上均有更好表现。而 700 亿参数模型则超越了闭源超级明星大模型 Claude 3 Sonnet,且与谷歌的 Gemini Pro 1.5 在性能上不相上下。

此外,Meta 也测试了 Llama 3 在真实世界场景中的性能。他们专门开发了一个新的高质量人类评估集,该评估集包含 1800 个提示,涵盖 12 种关键用例(征求建议、头脑风暴、分类、封闭式问题解答、编码、创意写作、提取、角色/人物角色、开放式问题解答、推理、改写和总结)。
在与 Claude Sonnet、Mistral Medium 和 GPT-3.5 的对比中, Llama 3 同样有着更好的表现。
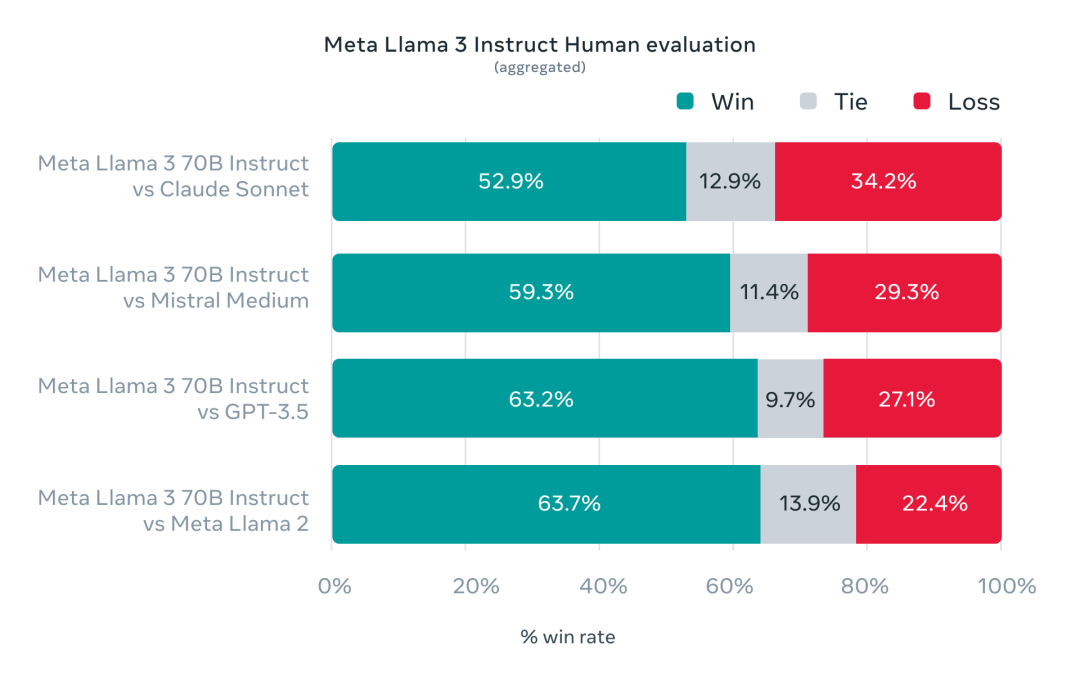
人类标注者根据该评估集进行的偏好排名,数据显示,Llama 3 700 亿参数指令跟随模型与真实世界中同等规模的竞争模型相比的强大性能。
Llama 3 的预训练模型还为这类规模的 LLM 模型建立了新的 SOTA。
Meta 表示,它希望最强大的 Llama 3 模型能够实现多模式,这意味着它们可以接收文本、图像甚至视频,然后生成所有这些不同格式的输出。他们还致力于使模型能够支持多种语言。它们还具有更大的“上下文窗口”,这意味着它们可以输入大量数据进行分析或总结。 (更大的上下文窗口也被证明可以降低模型的幻觉率,或者降低模型响应提示而输出不准确信息的频率。)据 Meta 称,它们还拥有改进的推理和编码能力。
值得一提的是,在 Meta 官方博客中显示,Meta 还在训练一款超过 4000 亿参数的版本,直接赶超 Claude 3。
四大关键要素成就了如今的 Llama 3
那么,如此强大的开源大模型是如何炼成的?
Meta 在其博客中表示,Llama 3 之所以能成为最强开源大模型,主要得益于四大关键要素:模型架构、预训练数据、扩大预训练规模和指令微调。
首先是模型架构。Llama 3 采用了相对标准的纯解码器 Transformer 架构。与 Llama 2 相比,Llama 3 得到了几项关键改进。Llama 3 使用了一个 128K token 的 tokenizer,它能更有效地编码语言,从而大幅提高模型性能。为了提高 Llama 3 模型的推理效率,Meta 在 80 亿和 700 亿参数大小的模型中都采用了分组查询关注(grouped query attention,GQA)。他们在 8192 个 token 的序列上对模型进行了训练,并使用掩码来确保自注意力不会跨越文档边界。
其次是训练数据。Meta 表示,要训练出最佳的语言模型,最重要的是策划一个大型、高质量的训练数据集。
据介绍,Llama 3 在超过 15T 的 token 上进行了预训练,训练数据集是 Llama 2 的七倍,包含的代码数量也是 Llama 2 的四倍。
为了应对多语言使用情况,Llama 3 的预训练数据集中有超过 5% 的高质量非英语数据,涵盖 30 多种语言。
为了确保 Llama 3 在最高质量的数据上进行训练,Meta 开发了一系列数据过滤管道。这些管道包括使用启发式过滤器、NSFW 过滤器、语义重复数据删除方法和文本分类器来预测数据质量。他们发现,前几代 Llama 在识别高质量数据方面的表现令人惊讶,因此使用 Llama 2 为文本质量分类器生成训练数据。
此外,为评估在最终预训练数据集中混合不同来源数据的最佳方法,他们还进行了大量实验,使得他们能够选择一种数据组合,确保 Llama 3 在各种使用情况下都能表现出色,包括琐事问题、STEM、编码、历史知识等。
第三是扩大预训练规模。为了在 Llama 3 模型中有效利用预训练数据,Meta 为下游基准评估制定了一系列详细的 scaling laws,这些 scaling laws 使他们能够选择最佳的数据组合,并就如何更好地使用训练计算做出最佳决定。
重要的是,在实际训练模型之前,scaling laws 允许他们预测最大模型在关键任务上的性能(例如,在 HumanEval 基准上评估的代码生成)。这有助于 Llama 3 在各种用例和功能中都能发挥强大的性能。
在开发 Llama 3 的过程中,他们对 scaling 行为进行了一些新的观察。例如,虽然 80 亿参数模型的 Chinchilla 最佳训练计算量相当于 200B token,但他们发现,即使模型在多两个数量级的数据上进行训练后,其性能仍在不断提高。Llama 3 80 亿参数和 700 亿参数模型在经过多达 15T token 的训练后,其性能仍呈对数线性增长。
为了训练最大的 Llama 3 模型,Meta 结合了三种并行化方式:数据并行化、模型并行化和管道并行化。当同时在 16K GPU 上进行训练时,他们最高效的实现实现了每 GPU 超过 400 TFLOPS 的计算利用率。他们在两个定制的 24K GPU 集群上进行了训练运行。为了最大限度地延长 GPU 的正常运行时间,Meta 研发团队还开发了一种新的训练堆栈,可以自动检测、处理和维护错误。此外,他们还大大改进了硬件可靠性和无声数据损坏检测机制,并开发了新的可扩展存储系统,减少了检查点和回滚的开销。这些改进使总体有效训练时间缩短了 95% 以上,与 Llama 2 相比,将 Llama 3 的训练效率提高了约三倍。
最后是指令微调。为了在聊天用例中充分释放预训练模型的潜力,Meta 还对指令微调方法进行了创新。他们的后期训练方法结合了监督微调(SFT)、拒绝采样、近似策略优化(PPO)和直接策略优化(DPO)。在 SFT 中使用的提示以及在 PPO 和 DPO 中使用的偏好排序的质量,对排列模型的性能有着极大的影响。
另外,通过 PPO 和 DPO 学习偏好排名也大大提高了 Llama 3 在推理和编码任务中的性能。他们发现,如果向模型提出一个它难以回答的推理问题,模型有时会生成正确的推理轨迹:模型知道如何得出正确答案,但不知道如何选择答案。对偏好排序的训练能让模型学会如何选择答案
目前,Llama 3 两种参数量的基础和 Instruct 版本都已上线 Hugging Face 可供下载。此外,微软 Azure、谷歌云、亚马逊 AWS、英伟达 NIM 等云服务平台也将陆续上线 Llama 3。
同时,Meta 还表示 Llama 3 会得到英特尔、英伟达、AMD、高通等多家厂商提供的硬件平台支持。
Hugging Face 地址:https://github.com/meta-llama/llama3
Meta 正在重塑 AIGC 新格局
从最初 Meta 推出免费 的 Llama 系列模型起,该模型一直是市场上最受欢迎的开源模型之一,随着 Meta 首次推出 Llama 3 模型,当今的生成式 AI 格局已然不同。
但 Meta 也面临着来自其他开源竞争者和提供付费封闭访问模型的公司的日益激烈的竞争。这套新模型的发布代表了 Meta 试图与 OpenAI、Anthropic 和 Google 等竞争对手在其最新模型中提供的一些功能相匹配,但到目前为止,这些功能仅在封闭的付费专有服务中提供。
正如许多行业观察人士所预期的那样,该公司最初发布了 Llama 3 的两个较小版本,并在新闻稿中表示“这是同类产品中最好的开源模型”,并将很快出现在 AWS、谷歌云、Databricks、微软 Azure 和 Hugging Face 上。但这些型号的功能不如市场上一些性能最高的专有型号。
Llama 3 的更大版本 (拥有超过 4000 亿个参数)模型目前仍在训练中,该公司表示将在未来几个月内进行安全测试后决定是否以及如何发布它。
但 Meta 负责 Llama 的产品副总裁拉加万·斯里尼瓦桑 (Ragavan Srinivasan)在接受媒体采访时表示,这个更大的版本“正在与当今市场上看到的一些一流的专有型号相媲美”,并补充说将具有“融入其中”的附加功能。这些功能将匹配或超过 Claude 3、Gemini 或 GPT-4 等型号当前提供的功能。
Meta 正在将 Llama 3 引入生成式 AI 领域,该领域与其前身 Llama 2 去年夏天首次亮相时的情况截然不同。从那时起,开源人工智能呈爆炸式增长,尽管关于允许用户开放访问源代码和模型权重的人工智能模型的安全性和安全性的争论不断。
总部位于巴黎的 Mistral AI 于 2023 年 6 月崭露头角,由前 Meta 研究人员共同创立,该公司发布了多种广受好评的开源模型,而就在本周,据报道该公司正在寻求 50 亿美元的估值。两个月前,谷歌发布了 Gemma,这是一种采用与其专有 Gemini 相同的研究和技术构建的开放模型。
与此同时,OpenAI、Google 和 Anthropic 开发的专有模型的功能不断进步,但由于训练它们所需的大量计算,成本也越来越高。事实上,Meta 是在训练和运行模型方面支出的大型科技领导者之一:1 月份,马克·扎克伯格表示 Meta 正在 NVIDIA AI 芯片上花费数十亿美元,并表示到 2024 年底,该公司的计算基础设施将包括 350,000 辆 H100。但 Meta 还致力于将其模型作为开源产品免费提供,希望能够控制其他人正在构建的平台,并最终找到一种方法来将这一地位货币化。这是一种昂贵的策略,并且短期内没有确定的盈利途径。
人工智能人才争夺战持续升温,顶级研究人员和许多前大型科技工程师纷纷跳槽创办自己的初创公司,竞争非常激烈。正如《财富》杂志最近报道的那样,Meta 最近发现了自己的人工智能人才流失,包括生成人工智能高级总监在内的几位高层离职。这对扎克伯格正在进行的生成式人工智能竞赛产生了影响:如果 Meta 想要保持领先地位,它需要确保能够留住最有资格构建这些模型的顶尖人工智能人才。相反,构建最佳模型有助于吸引顶尖人才,而他们通常会被最雄心勃勃的人工智能实验室所吸引。
AI 是 Meta 的首要任务
人工智能已经成为 Meta 的首要任务,取代了该公司之前对元宇宙的重视,因此它明确计划采取一切措施在拥挤的领域中脱颖而出。去年 10 月,扎克伯格表示,“人工智能将是我们 2024 年最大的投资领域,无论是在工程还是计算机资源方面。”作为今天 Llama 公告的一部分,他加倍强调了这一主题,表示“我们正在大量投资来构建领先的人工智能。”
Meta 也是开源研究的长期拥护者。它围绕 Pytorch 框架创建了一个开源生态系统,并于最近庆祝了 FAIR(基础人工智能研究)成立 10 周年,其创建的目的是“通过开放研究推进人工智能的发展水平,造福所有人”,并已由 Meta 首席科学家 Yann LeCun 领导。
LeCun 推动 Llama 2 发布商业许可以及模型权重。 “我在内部提倡这一点,”他在 2023 年 9 月的AI Native会议上说道。“我认为这是不可避免的,因为大型语言模型将成为每个人都会使用的基础设施,它必须是开放的。 ”
人工智能组织 Meta 副总裁 Mahohar Paluri 向《财富》杂志表示,当今激烈的开源人工智能竞争让该公司感到“我们加速创新并以开放方式进行创新的使命得到了支持和验证,以便我们能够构建更安全、更高效的模型”每次迭代都会变得越来越好。”相互构建的模型越多,包括 Llama,“我们在为最终用户提供更多用例方面取得进展的速度就越快。”
参考链接:
https://fortune.com/2024/04/18/meta-ai-llama-3-open-source-ai-increasing-competition/




