

非关系型
我们在上面其实已经多次提到了 MongoDB 是非关系型的文档数据库,它完全抛弃了关系型数据库那一套体系之后,在设计和实现上就非常自由,它不再需要遵循 SQL 和关系型数据库的体系,可以更自由对特定场景进行优化,而在 MongoDB 假设的场景中遍历数据并不是常见的需求。

MySQL 中使用 B+ 树是因为 B+ 树只有叶节点会存储数据,将树中的每一个叶节点通过指针连接起来就能实现顺序遍历,而遍历数据在关系型数据库中非常常见,所以这么选择是完全没有问题的7。
MongoDB 和 MySQL 在多个不同数据结构之间选择的最终目的就是减少查询需要的随机 IO 次数,MySQL 认为遍历数据的查询是常见的,所以它选择 B+ 树作为底层数据结构,而舍弃了通过非叶节点存储数据这一特性,但是 MongoDB 面对的问题就不太一样了:

虽然遍历数据的查询是相对常见的,但是 MongoDB 认为查询单个数据记录远比遍历数据更加常见,由于 B 树的非叶结点也可以存储数据,所以查询一条数据所需要的平均随机 IO 次数会比 B+ 树少,使用 B 树的 MongoDB 在类似场景中的查询速度就会比 MySQL 快。这里并不是说 MongoDB 并不能对数据进行遍历,我们在 MongoDB 中也可以使用范围来查询一批满足对应条件的记录,只是需要的时间会比 MySQL 长一些。
SQL
很多人看到遍历数据的查询想到的可能都是如上所示的范围查询,然而在关系型数据库中更常见的其实是如下所示的 SQL —— 查询外键或者某字段等于某一个值的全部记录:
SQL
上述查询其实并不是范围查询,它没有使用 >、< 等表达式,但是它却会在 comments 表中查询一系列的记录,如果 comments 表上有索引 post_id,那么这个查询可能就会在索引中遍历相应索引,找到满足条件的 comment,这种查询也会受益于 MySQL B+ 树相互连接的叶节点,因为它能减少磁盘的随机 IO 次数。
MongoDB 作为非关系型的数据库,它从集合的设计上就使用了完全不同的方法,如果我们仍然使用传统的关系型数据库的表设计思路来思考 MongoDB 中集合的设计,写出类似如上所示的查询会带来相对比较差的性能:
JavaScript
因为 B 树的所有节点都能存储数据,各个连续的节点之间没有很好的办法通过指针相连,所以上述查询在 B 树中性能会比 B+ 树差很多,但是这并不是一个 MongoDB 中推荐的设计方法,更合适的做法其实是使用嵌入文档,将 post 和属于它的所有 comments 都存储到一起:
JSON
使用上述方式对数据进行存储时就不会遇到 db.comments.find( { post_id: 1 } ) 这样的查询了,我们只需要将 post 取出来就会获得相关的全部评论,这种区别于传统关系型数据库的设计方式是需要所有使用 MongoDB 的开发者重新思考的,这也是很多人使用 MongoDB 后却发现性能不如 MySQL 的最大原因 —— 使用的姿势不对。
有些读者到这里可能会有疑问了,既然 MongoDB 认为查询单个数据记录远比遍历数据的查询更加常见,那为什么不使用哈希作为底层的数据结构呢?
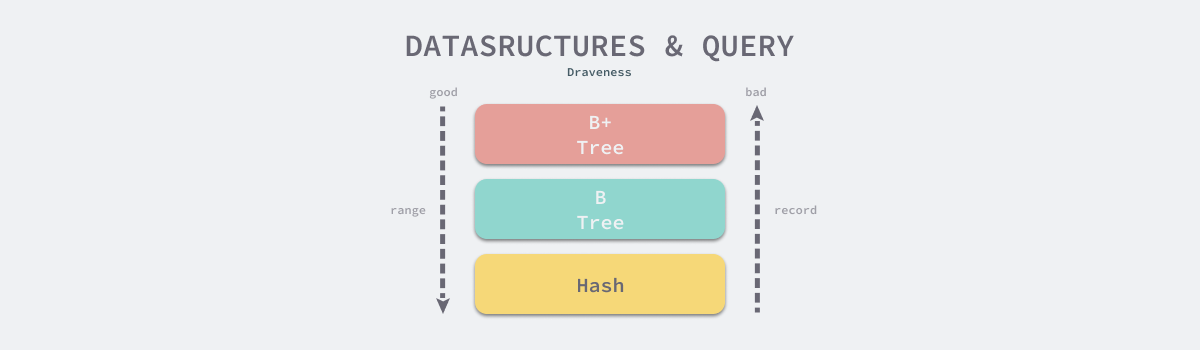
如果我们使用哈希,那么对于所有单条记录查询的复杂度都会是 O(1),但是遍历数据的复杂度就是 O(n);如果使用 B+ 树,那么单条记录查询的复杂度是 O(log n),遍历数据的复杂度就是 O(log n) + X,这两种不同的数据结构一种提供了最好的单记录查询性能,一种提供了最好的遍历数据的性能,但是这都不能满足 MongoDB 面对的场景 —— 单记录查询非常常见,但是对于遍历数据也需要有相对较好的性能支持,哈希这种性能表现较为极端的数据结构往往只能在简单、极端的场景下使用。
本文转载自 Draveness 技术博客。
原文链接:https://draveness.me/whys-the-design-mongodb-b-tree

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论