

在 QCon 北京 2019 大会上,翟佳讲师做了《Pulsar 如何为批和流处理提供高效统一的数据存储》主题演讲,主要内容如下。
演讲简介:
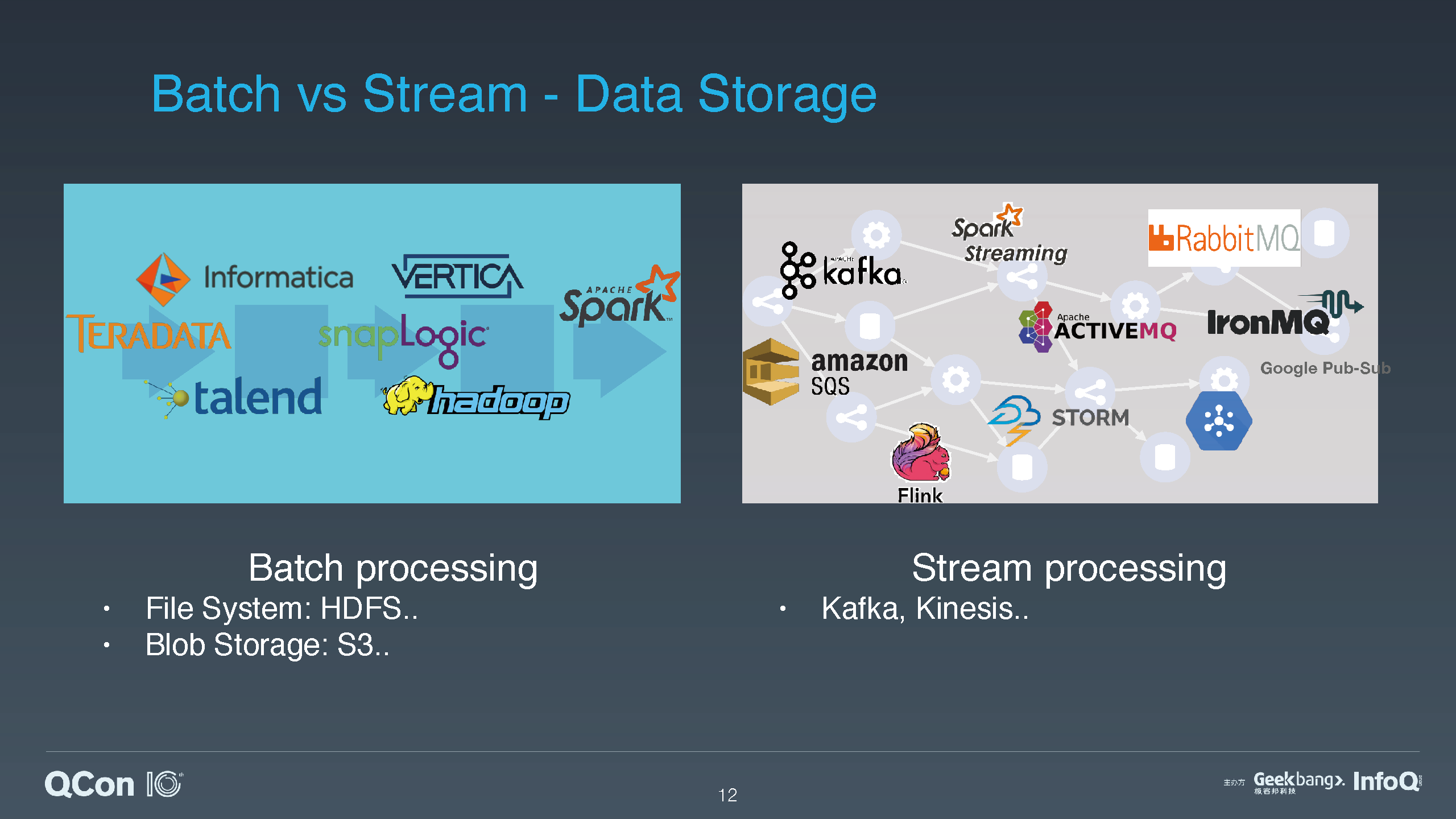
大数据的处理方式主要分为两类,一类是基于有边界的历史静态数据的批处理;另一类是基于无边界的 event 和流数据的实时处理。
由于具体业务和大数据技术发展历程的原因,在实际应用中,批处理和流处理的数据和技术还是被分隔成两个不同的部分。这其中的一个原因是两种数据类型存储方式的不同:近实时的流、事件数据通常使用消息队列、日志存储系统进行存储;而批处理所需要的静态数据,通常使用文件系统、对象存储进行存储。这就意味着,数据科学家还是需要编写两套不同的计算逻辑来访问存储在不同存储系统中的数据。
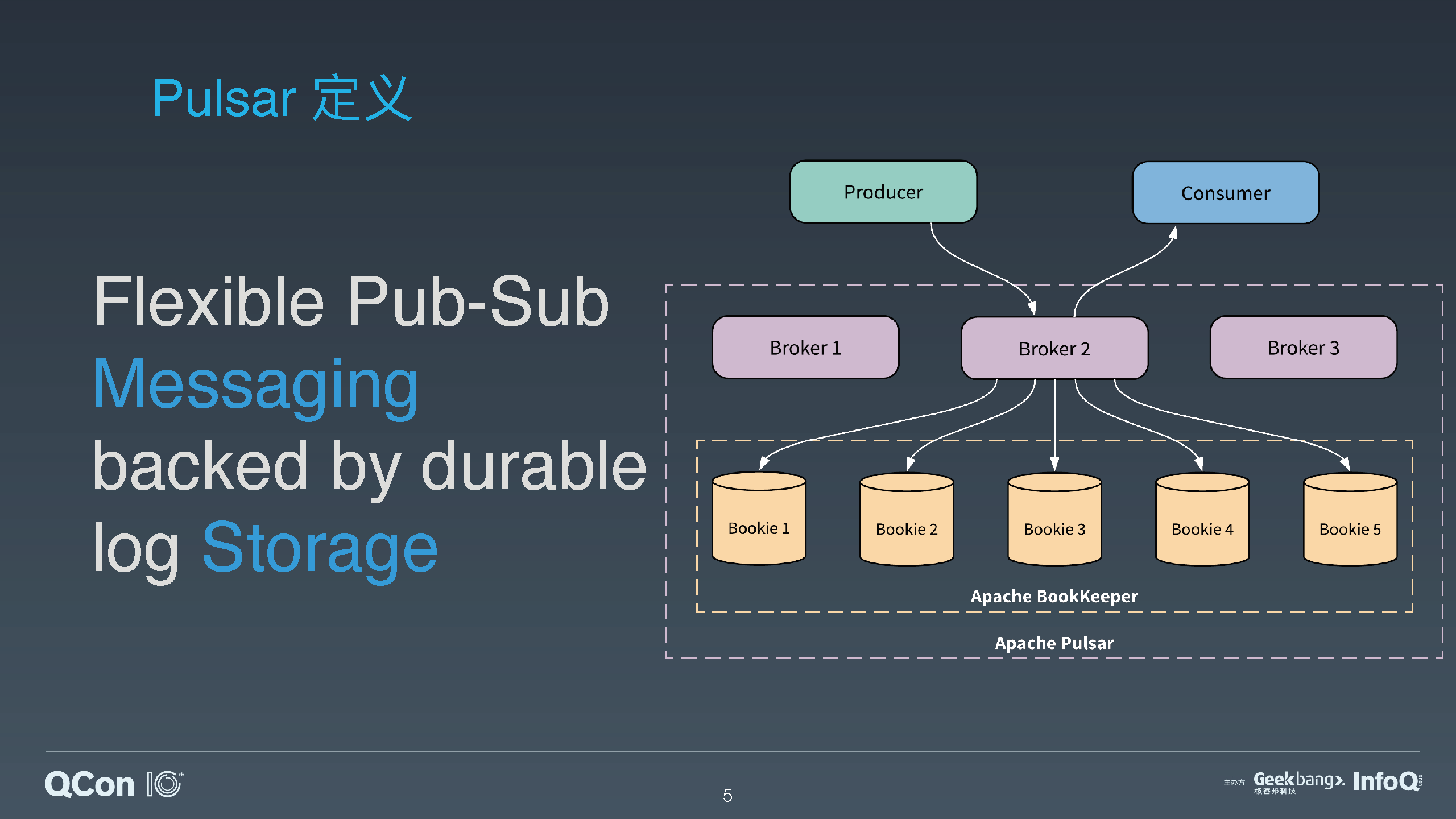
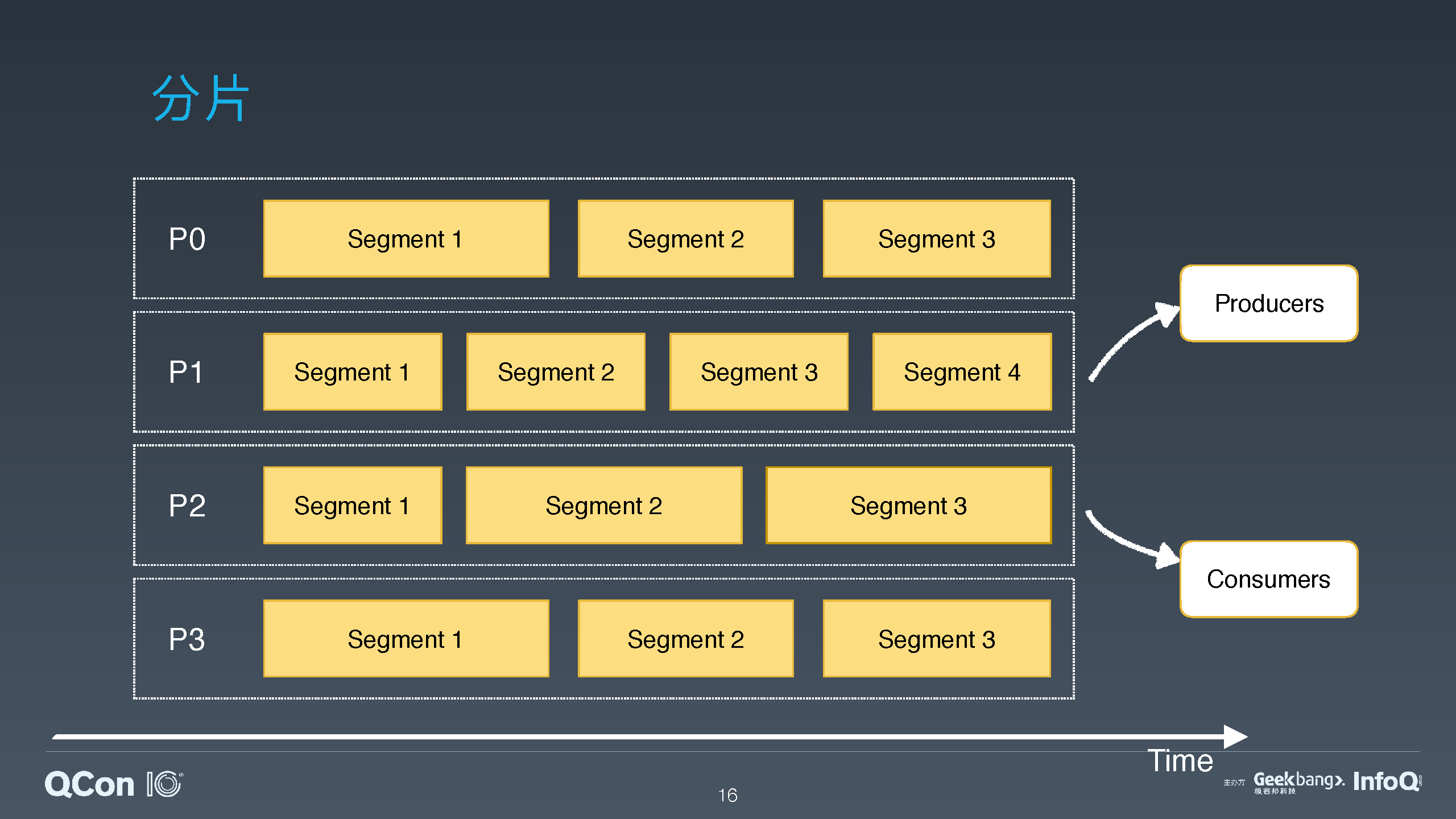
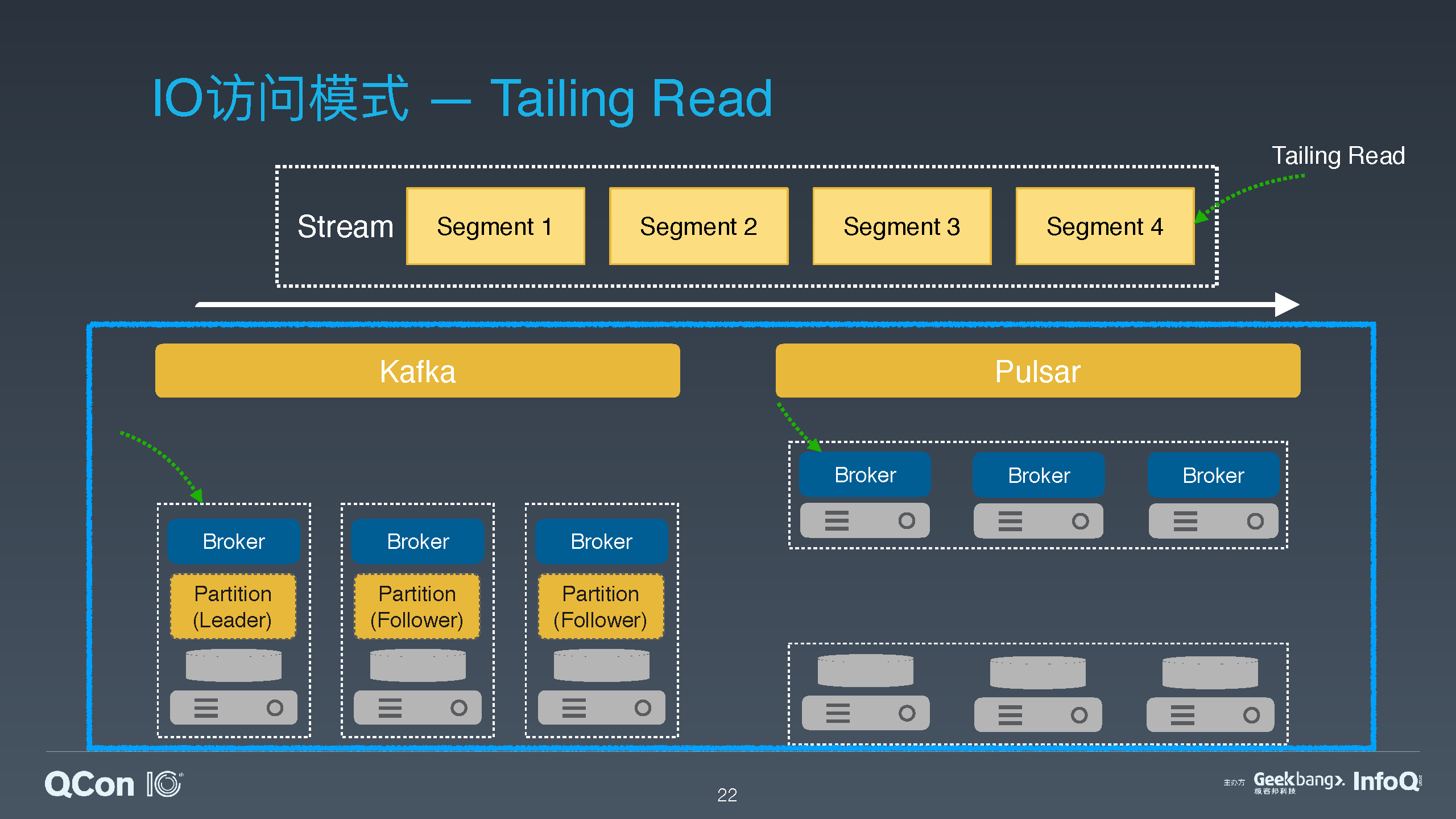
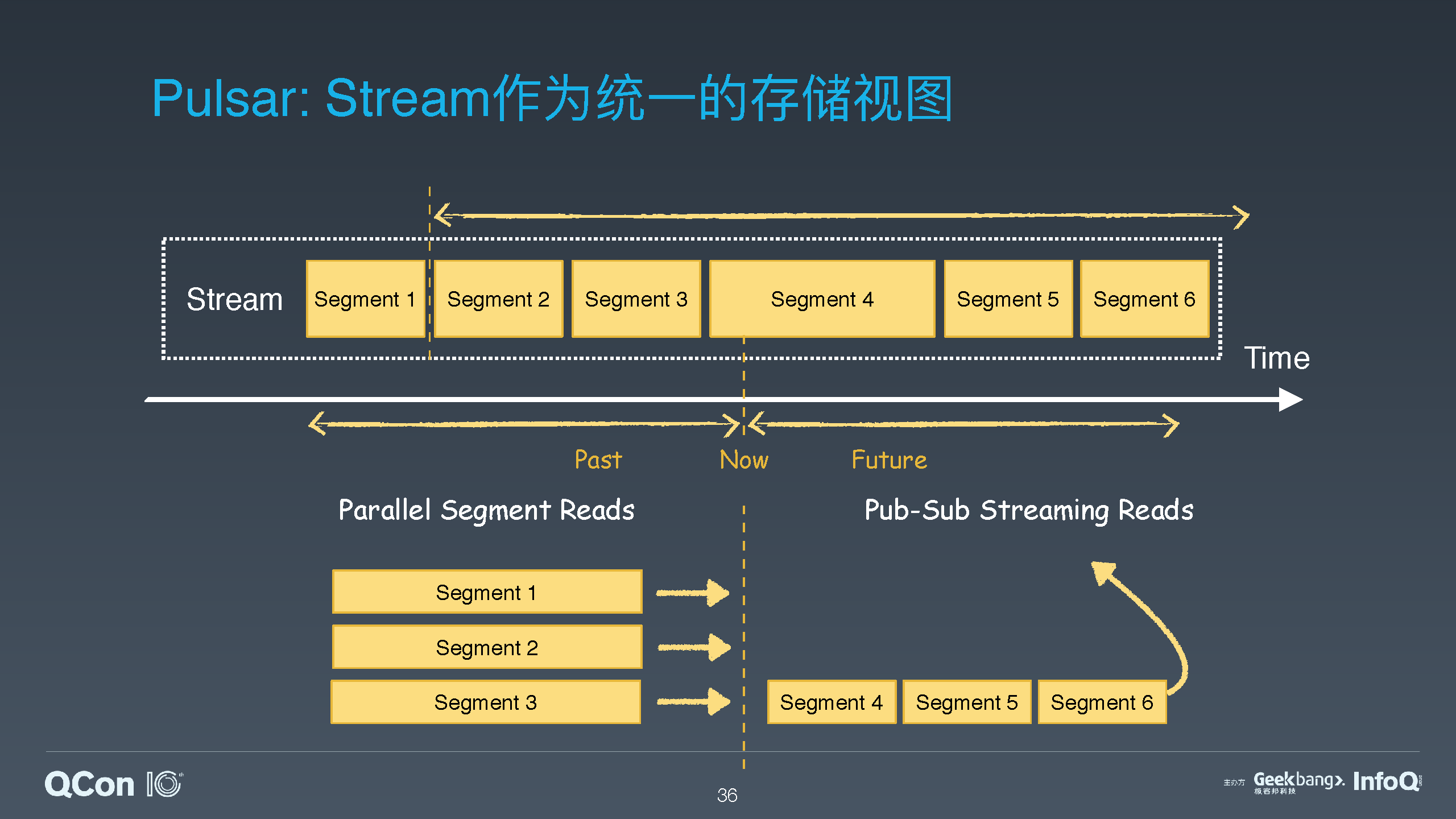
Apache Pulsar 是 Yahoo 开源的下一代分布式消息系统,在 2018 年 9 月从 Apache 软件基金会毕业成为顶级项目。Pulsar 特有的分层分片的架构,在保证大数据消息流系统的性能和吞吐量的同时,也提供了高可用性、高可扩展性和易维护性。Pulsar 的分片架构将消息流数据的存储粒度从分区拉低到了分片,并且 Pulsar 提供了层级化存储功能,可以支持近乎无限大小的流存储。另一方面 Pulsar 也可以基于分片提供对有边界的静态数据的存储。这使得 Pulsar 可以完美地匹配和适配大数据计算框架中的批流一体的存储需求。
主要内容
什么是 Pulsar;
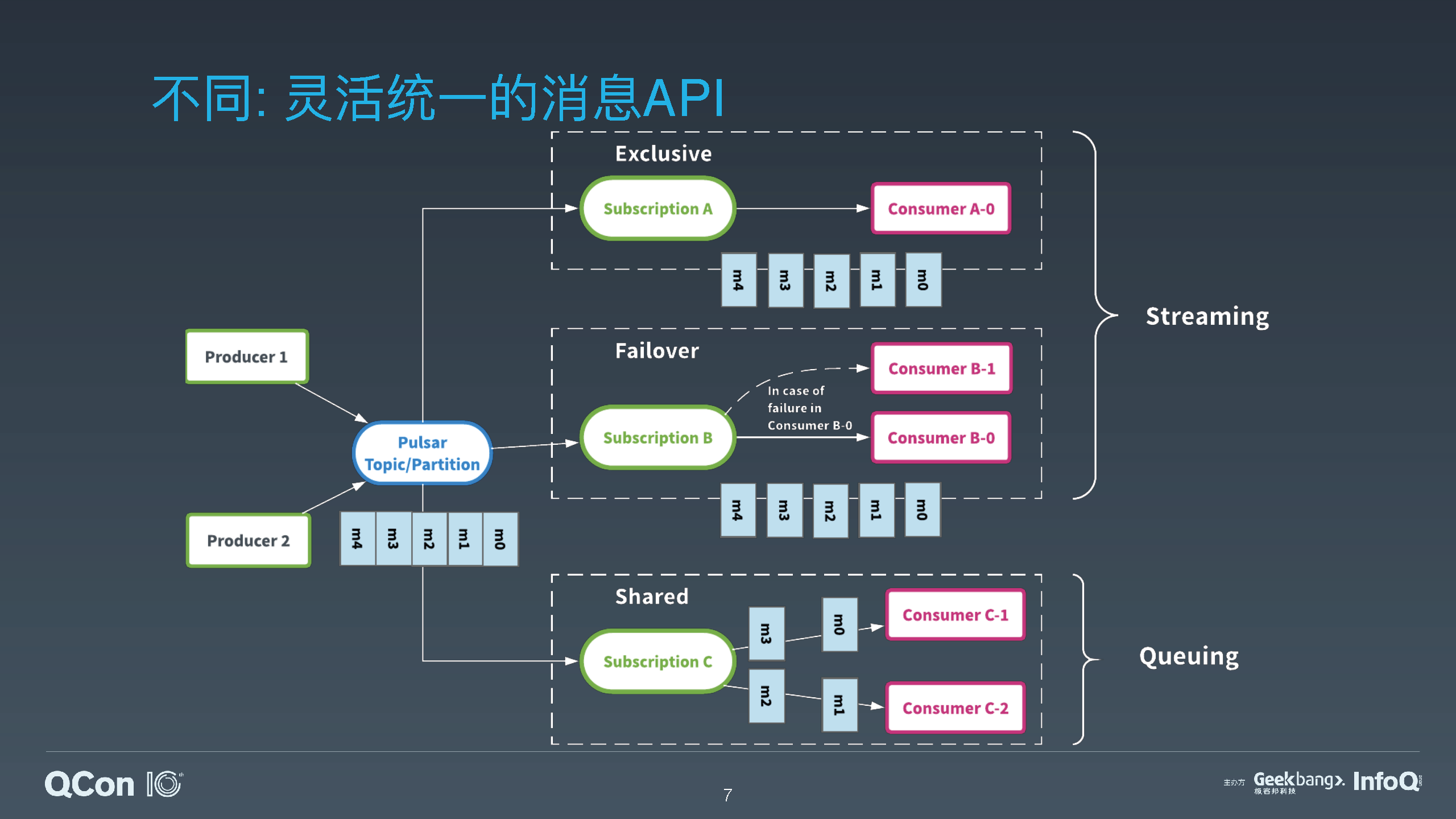
介绍 Pulsar 的分层和分片架构,以及为什么 Pulsar 的这种架构可以更好地适配批流一体计算框架;
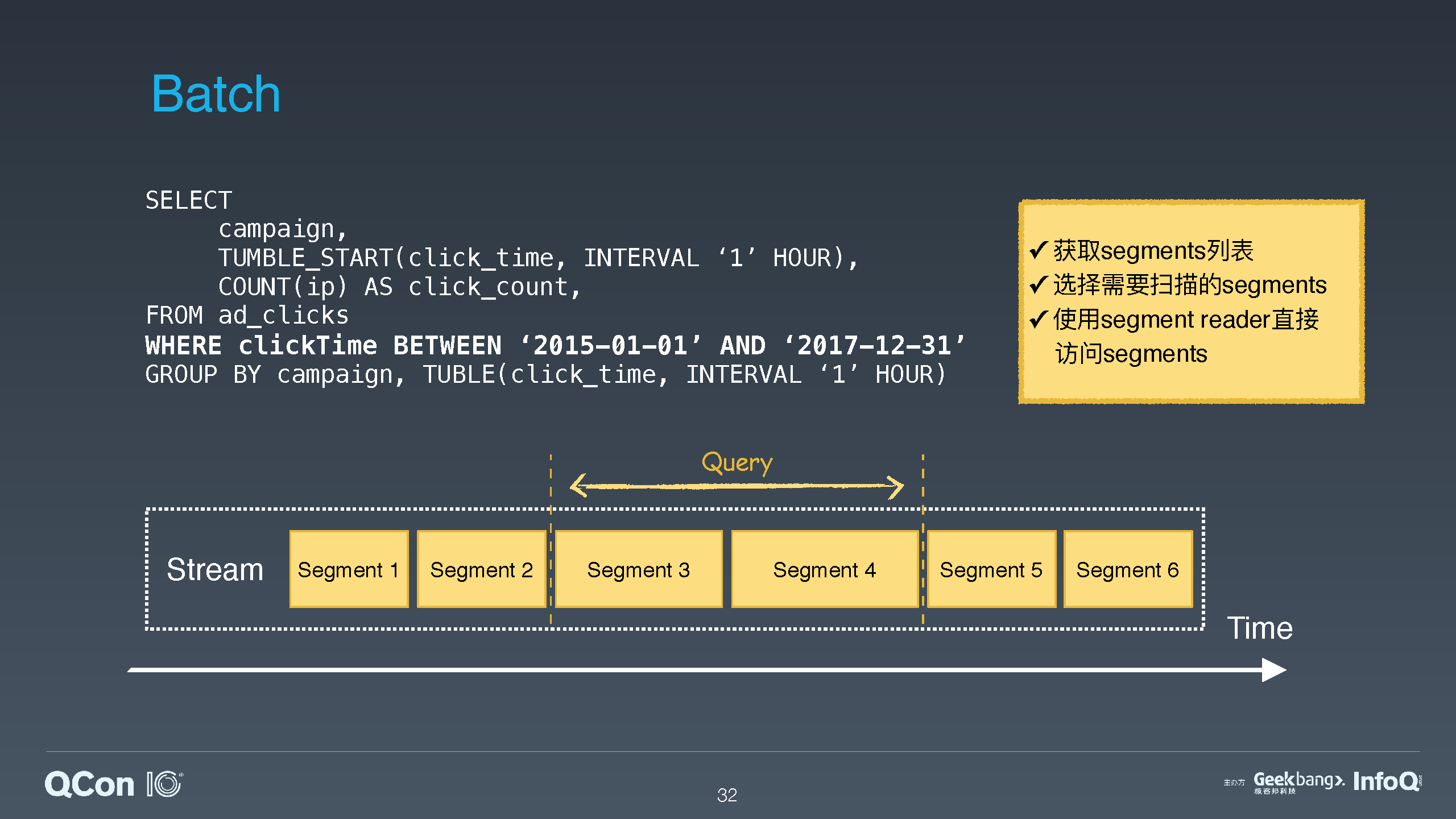
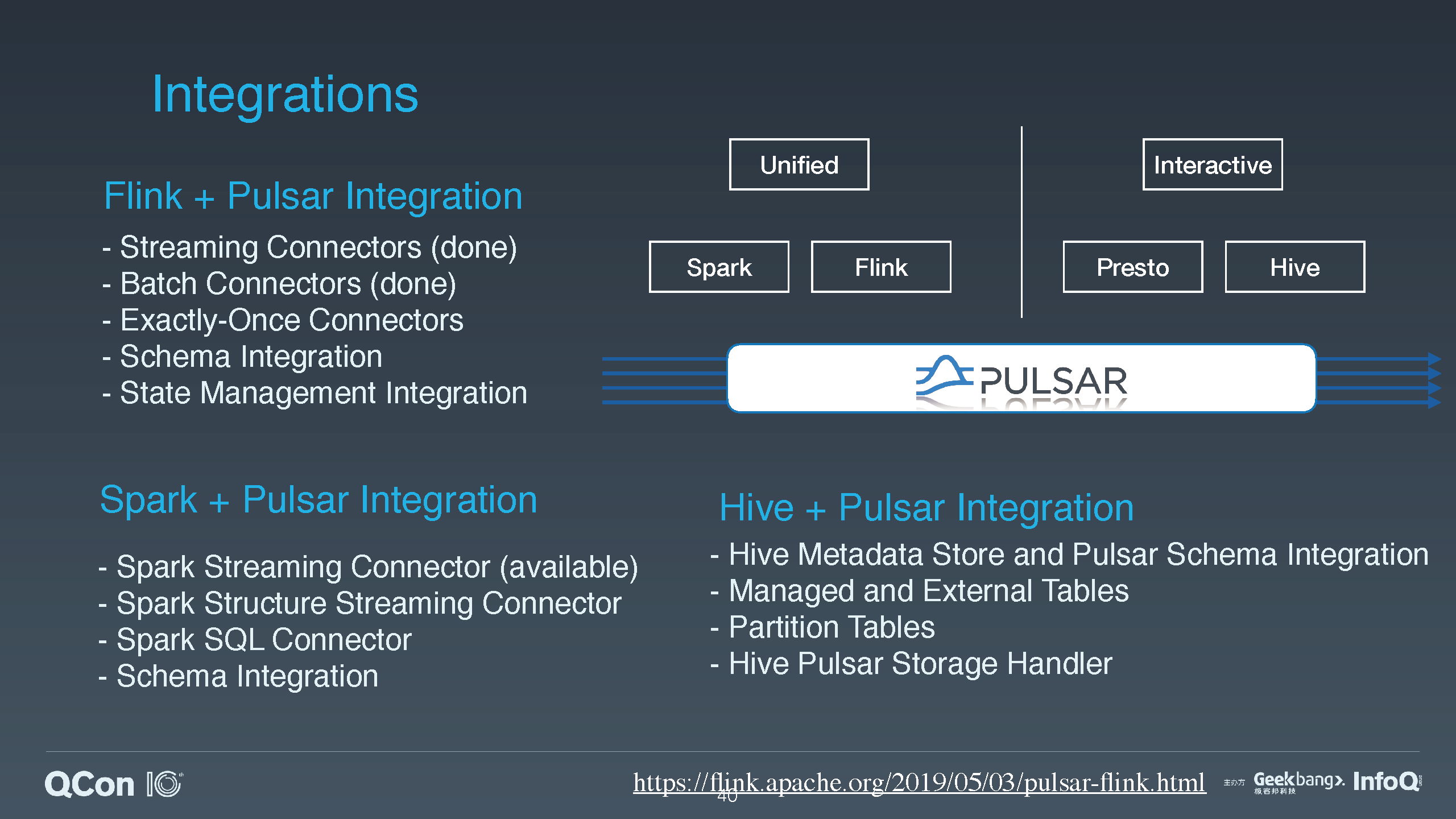
介绍 Pulsar 怎么跟流处理中的 Spark 和 Flink 以及批处理中的 Presto 和 Hive 结合,提供批流一体的高效的数据存储。
听众受益
理解批流一体的处理优势;
理解批处理和流处理对存储的不同需求;
深入理解 Apache Pulsar 的基础架构;
深入理解 Apache Pulsar 能匹配批流一体需求的原因。
讲师介绍:
翟佳
StreamNative 核心工程师
翟佳是 Apache Pulsar 和 Apache BookKeeper 两个开源项目的 PMC 成员和 Committer。是 StreamNative 的核心工程师,曾任职于 EMC,是北京 EMC 实时处理平台的技术负责人。


完整演讲 PPT 下载链接:
https://qcon.infoq.cn/2019/beijing/schedule

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论