
GPT-4o 在 3 月底掀起的“吉卜力”风潮过去还没多久,字节又加入了图像生成竞赛。
4 月 15 日,字节 Seed 团队发布了中英双语图像生成基础模型 Seedream 3.0,主要在文本渲染能力增强、美学质量提升、原生高分辨率输出、高效推理成本方面进行了优化。
Seedream 3.0 支持原生 2K 分辨率图像生成,无需后处理,同时兼容更高分辨率,适应多种比例输出。在不使用位置编码(PE)情况下,生成一张 1K 分辨率图像仅需约 3 秒,速度远超当前主流商用模型。
字节还针对 CT(对比学习)和 SFT(监督微调)阶段的数据,专门训练了多个版本的字幕模型。这些描述模型覆盖了美学、风格、版式等多个专业领域,极大增强了 Seedream 3.0 对提示词的响应能力。

Seedream 3.0 继续采用 MMDiT 架构来处理图像和文本的 token。团队采用混合分辨率训练策略,在每一阶段训练中,将不同纵横比和分辨率的图像打包在一起进行训练。为提高泛化能力,团队将 2.0 中的 Scaling RoPE 扩展为“跨模态 RoPE”,进一步增强图文 token 之间的对齐能力。
与 2.0 中采用 CLIP 作为奖励模型不同,Seedream 3.0 使用视觉-语言模型(VLMs)作为奖励建模框架,将指令明确地构建为查询(Query),并通过“Yes”响应 token 的归一化概率来计算奖励值。奖励模型的规模也从 10 亿参数扩展到了 200 亿以上。
字节在论文中表示,在人工智能评测平台 Artificial Analysis 的公开测试中,Seedream 3.0 在多个维度表现领先,位居图文生成模型榜首,超越 GPT-4o、Midjourney v6.1、Imagen 3 等主流模型。
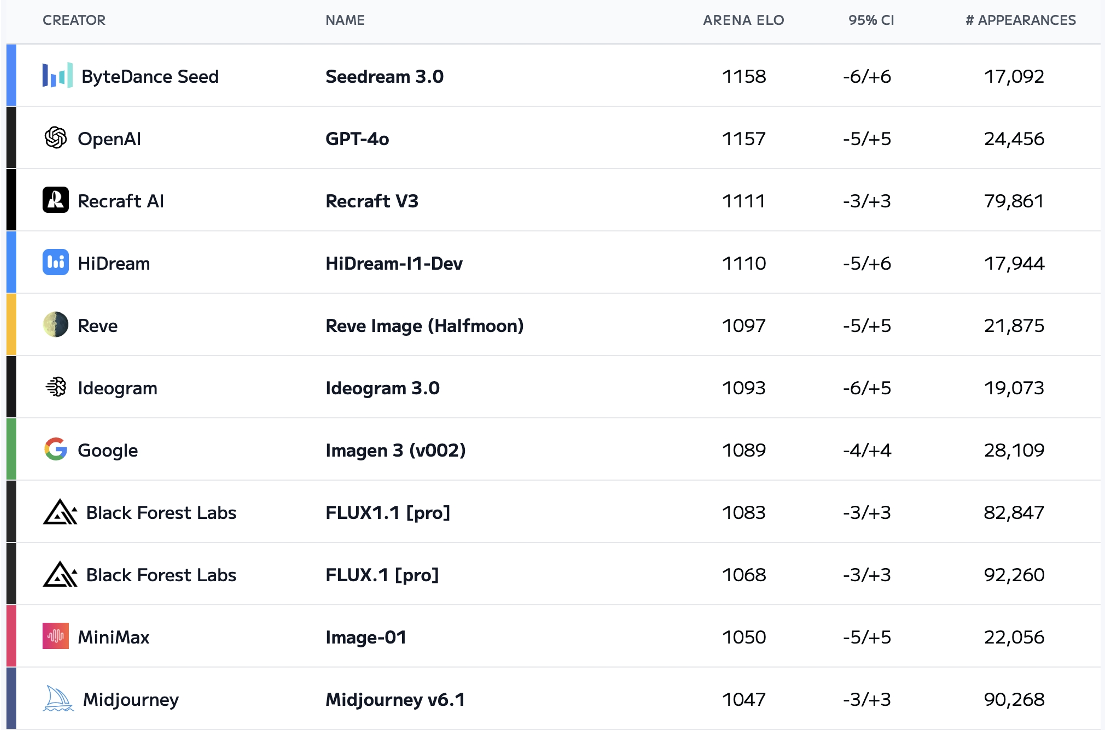


另外,字节还特地跟 GPT-4o 进行了对比。
OpenAI 的 GPT-4o 虽具强大多模态能力,但在图像生成方面仍存在短板。对比显示,Seedream 3.0 在中文文本渲染、图像编辑一致性和整体画质上表现更优。
GPT-4o 擅长英文小字与符号,但中文排版欠佳;图像编辑功能灵活,却难保原图一致性。SeedEdit 则在保留人物 ID 和提示词遵循上更稳健。画质方面,Seedream 图像更清晰自然,而 GPT-4o 常出现偏色和噪点。







