
本文最初发布于 marmelab 博客。
规范驱动开发(SDD)重拾了编码前撰写大量文档的旧理念——这就像是瀑布式开发时代的回响。尽管它承诺为 AI 驱动的编程提供结构框架,却可能让敏捷性被层层 Markdown 文档所掩埋。本文将探讨一下,为什么更具迭代性的自然语言方法可能更契合现代开发的需求。
规范的兴起
编码助手令人望而生畏:开发者面对的不再是布满熟悉菜单和按钮的集成开发环境,而是简陋的聊天输入框。在指引如此有限的情况下,我们如何确保代码的正确性?
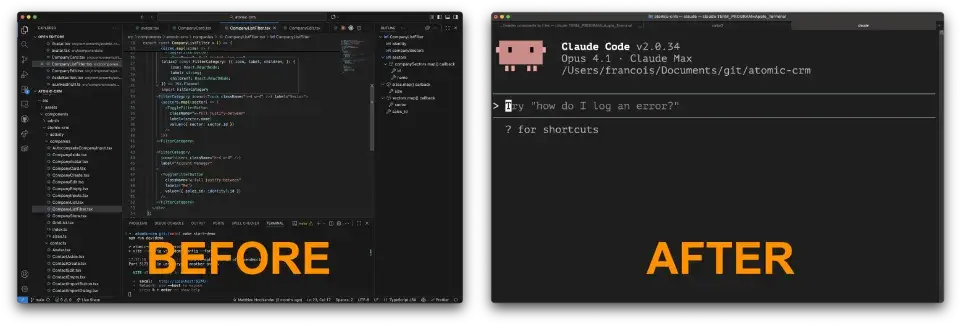
为帮助人们借助编码助手编写出优质的软件,开源社区设计了一种巧妙引导编码代理的方法。基于初始提示和若干指令,大型语言模型(LLM)可以生成产品规范说明、实施计划及详细任务清单。每份文档都依赖前一份文档的内容,用户可以通过编辑文档来完善规范说明。

最终,这些文档会被移交给编码代理(Claude Code、Cursor、Copilot 等)。在明确的指引下,这些代理应该可以编写出满足业务需求的可靠代码。
这种方法被称为规范驱动开发(SDD),有多种工具包可供入门使用,包括:
GitHub 的Spec-Kit
亚马逊云科技的Kiro
Tessl 的Tessl
BMad Code 的BMad Method (BMM)
若需了解这些工具的差别,Birgitta Böckeler 写过一篇精彩的文章“理解规范驱动开发:Kiro、spec-kit与Tessl”。
Markdown 的觉醒
规范文件是什么样子的?本质上就是一堆 Markdown 文件。以下是使用 GitHub 规范工具包的示例:某开发者希望在时间追踪应用中显示当前日期,最终生成了8个文件和1300行文本:
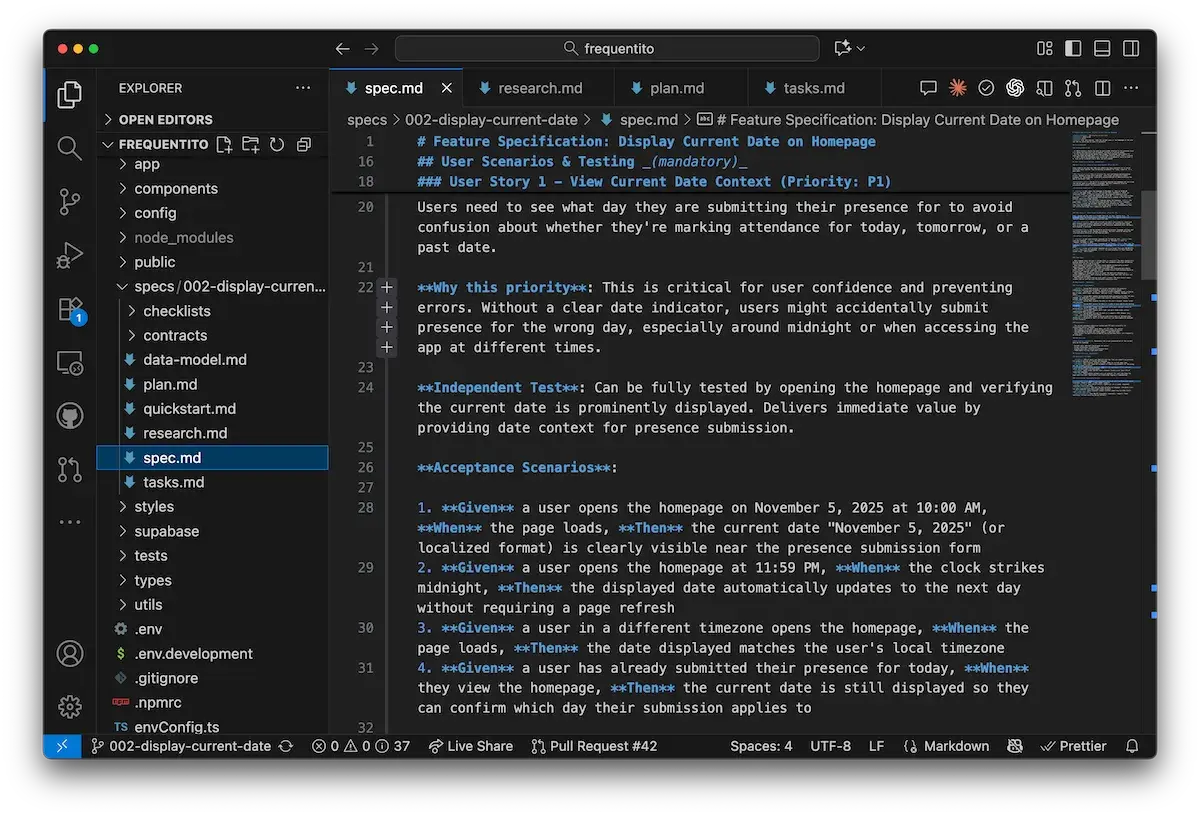
以下是另一个使用 Kiro 实现一个小功能的示例(为Atomic CRM中的联系人添加“推荐人”字段):
Requirements.md - Design.md - Tasks.md
乍看之下,这些文件似乎符合要求。但细节决定成败。一旦开始使用 SDD,其不足之处便会暴露出来:
上下文盲点:与编码代理类似,SDD 代理通过文本搜索和文件导航来发现上下文。它们常常遗漏当前需要升级的功能,因此仍需功能和技术专家进行审查。
Markdown 文件冗长:SDD 产生了太多的文本,尤其是在设计阶段。开发者需要耗费大量时间来阅读冗长的 Markdown 文件,在那些过度冗余、听起来很专业的文字里寻找一些基本的错误。这会令人精疲力竭。
死板:对大多数情况而言,三步设计流程过于繁琐。规范中有许多重复的内容、虚构的边界案例和过度的细化,读起来像是出自吹毛求疵的文员之手。
伪敏捷:SDD 工具包生成的所谓“用户故事”常滥用该术语(例如,“作为系统管理员,我希望引用关系存储在数据库中”就不是用户故事)。这虽然不会导致缺陷,却很容易分散注意力。
双重代码审查:技术规范中已经包含代码。开发人员必须在运行代码前进行审查,但由于仍然存在缺陷,他们还需审查最终实现方案。这会导致审查时间翻倍。
虚假的安全感:SDD 方法旨在使编码代理保持在正确的轨道上,但实践中,代理并不总是遵循规范。在上面的例子中,在未编写任何单元测试的情况下,该代理就已经将“验证实现”任务标记为已完成——它编写了手动测试说明。
边际效益递减:当从零开始新项目时,SDD 表现出色,但随着应用程序规模的扩大,其规范往往偏离核心需求并拖慢开发进度。对于已有的大型代码库而言,该方法基本没法使用。
大多数编码代理已具备计划模式和任务清单功能。在多数情况下,SDD 带来的收益非常小,有时甚至会增加功能开发的成本。
公平地说,SDD 确实能帮助代理专注于要完成的任务,偶尔还能发现开发者可能忽略的边界情况。在我看来,这种取舍(将 80%的时间耗费在阅读而非思考上)并不值得。
项目经理的复仇
目前 SDD 的帮助不大,也许是因为工具包尚不成熟,文档提示也有待进一步完善。如果真是这样,我们只需再等几个月,待其改进完成即可。
但我个人认为,SDD 的前进方向是错的。它试图解决一个错误的挑战:
如何将开发人员从软件开发中剔除?
它利用编码代理来取代开发人员,并通过周密的规划来确保代理可以实现这一目标。
从这个意义上说,SDD 让我想起瀑布模型——该模型要求在编码前完成大量的文档工作,开发人员只需要将规范转化为代码即可。
但开发人员早已不再是单纯的执行者,而且,“预先大量设计”方法因为堆砌假设而屡屡受挫。本质上,软件开发是一个非确定性过程,规划无法消除不确定性(参见经典论文“没有银弹”)。
此外,SDD 究竟为谁而生?你必须具备业务分析师的素养才能在需求阶段发现错误,你必须具备开发人员的能力才能在设计阶段捕获问题。因此,它并未解决它宣称要解决的问题(消除开发人员),反而只能被精通两种技能的极少数人所使用。SDD 重蹈了无代码工具的覆辙——这些工具承诺提供“无开发人员”的体验,实际上却仍需开发人员的参与才能运作。
新希望
敏捷方法用可预测性换取适应性,解决了非确定性开发的问题。我认为,它为我们指明了一条道路:编码代理能够帮助我们构建可靠的软件,而又不会深陷 Markdown 的泥潭。
只要给编码代理的问题足够简单,它就不会失控。与其将复杂的需求转化为复杂的设计文档,我们更应该将复杂的需求拆解为多个简单的需求。
我已经采用一种源自精益创业理念的简单方法,运用编码代理成功构建出了相当复杂的软件,而且全程无需查看代码:
识别产品中风险最高的假设。
设计最简单的实验进行验证。
开发那个实验。若失败,返回步骤 2;否则从步骤 1 重新开始。
这里有一个示例:这款具备自适应网格功能的3D雕刻工具,是我与Claude Code耗时约 10 小时共同开发完成的。
我没有编写任何规范。只需逐个添加小功能,在代理误解我的意图或我的想法行不通时修正软件。你可以在编码会话日志中查看我的指令:它们通常简短模糊,有时甚至会陷入死胡同,但这没关系。当实现简单想法的成本很低时,通过小步迭代进行构建才是最快收敛到优质产品的途径。
敏捷方法让我们摆脱了瀑布模型的官僚作风。它证明,产品经理与开发人员的紧密协作可以消除设计文档。编码代理为敏捷注入了强劲的动力——我们能实时编写产品待办事项并见证其构建过程,而无需设计任何原型。
相较于规范驱动开发,这种方法存在一个缺陷:它没有专属名称。“氛围编码”听起来有些随意,不如称之为自然语言开发。
不过,确实有个问题困扰着我:编码代理使用文本而非视觉元素。有时我想指定一个特定的区域,但浏览器自动化工具还不够完善(说你呢,Playwright MCP Server)。因此,如果要开发新的工具来增强编码代理的功能,我认为重点应放在实现更丰富的视觉交互上。
小结
敏捷方法早已淘汰了规范。我们真的需要让它死而复生吗?
规范驱动开发似乎诞生于那些熟记项目管理教科书的计算机科学毕业生之手,他们梦想着将开发人员从软件开发流程中剔除。我认为这是在错失一个机会——使用编码代理来增强新一代开发人员的能力,让他们使用自然语言迭代地构建软件。
让我用一个比喻来结束本文:编码代理就像内燃机的发明。规范驱动开发将它们局限在机车领域,而我们本该将它用于汽车、飞机以及介于两者之间的所有事物。还有,就像内燃机一样,如果我们关心环境,就应该谨慎使用编码代理。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://marmelab.com/blog/2025/11/12/spec-driven-development-waterfall-strikes-back.html




