
如今的大模型,早已告别参数竞赛的初级阶段,将竞争焦点转向实际智能水平、落地效率、成本控制与商业价值的综合比拼。
在这样的关键节点,真正的行业分野,或许不仅在于实力过硬,还在于如何让智能普惠,如何为用户创造实实在在的价值。
最近,MiniMax 发布并开源全新的 M2 模型,正是这一方向的典型实践:不仅在权威测评中跻身全球第一梯队,更以极致性能与性价比的双重突破,再次印证了其在大模型下半场竞争中的领先身位。
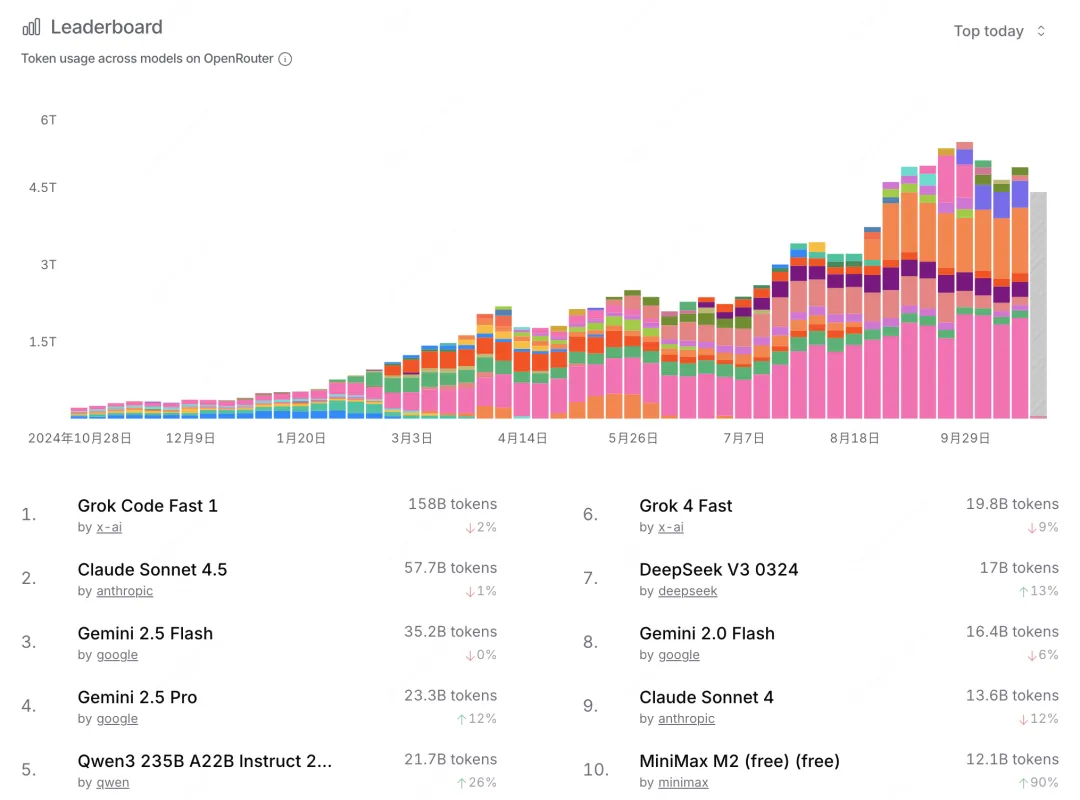
真实开发者的使用数据最具说服力,因为 M2 模型开源后官方 API 和 Agent 限时免费,在全球极具影响力的 AI 模型聚合与调用平台 OpenRouters 上数据显示: 仅仅开源后的第一天,MiniMax-M2 的模型调用量就冲到了全球前十。
Artificial Analysis 榜单全球前五,MiniMax-M2 凭什么
相比此前的 M1,MiniMax-M2 定位轻量级模型,但综合性能绝对不容小觑。
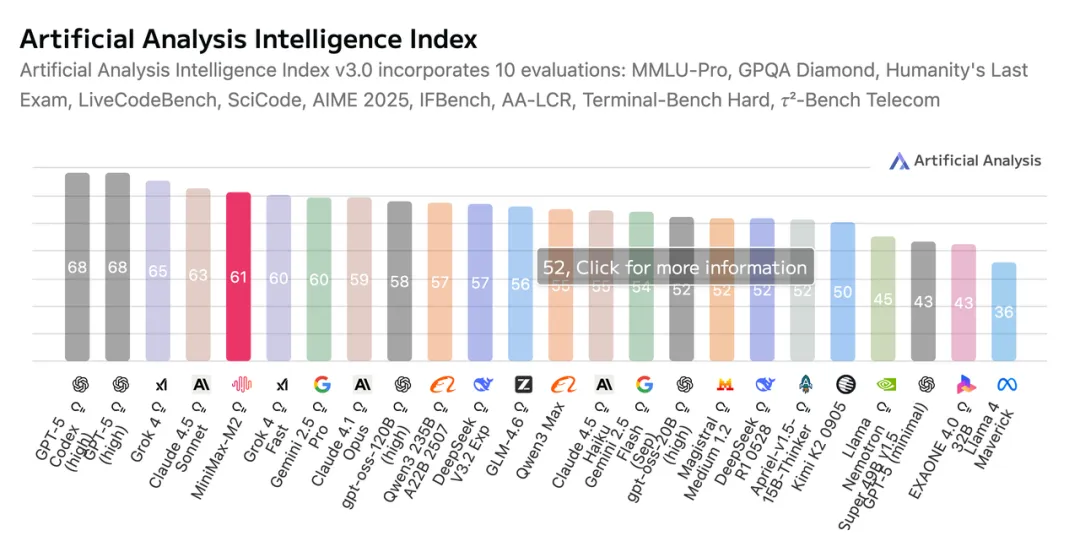
在全球权威测评榜单 Artificial Analysis(简称 AA)中,MiniMax-M2 不仅总分成功跻身全球前五,在国内同类模型中更是位列第一,充分体现出其在综合智能水平上的竞争力。
在与 GPT-5、Claude Sonnet 4.5 这些最新海外顶尖模型的基础性能测试对比中,MiniMax-M2 在多项核心任务中的表现毫不逊色,某些能力甚至更胜一筹。
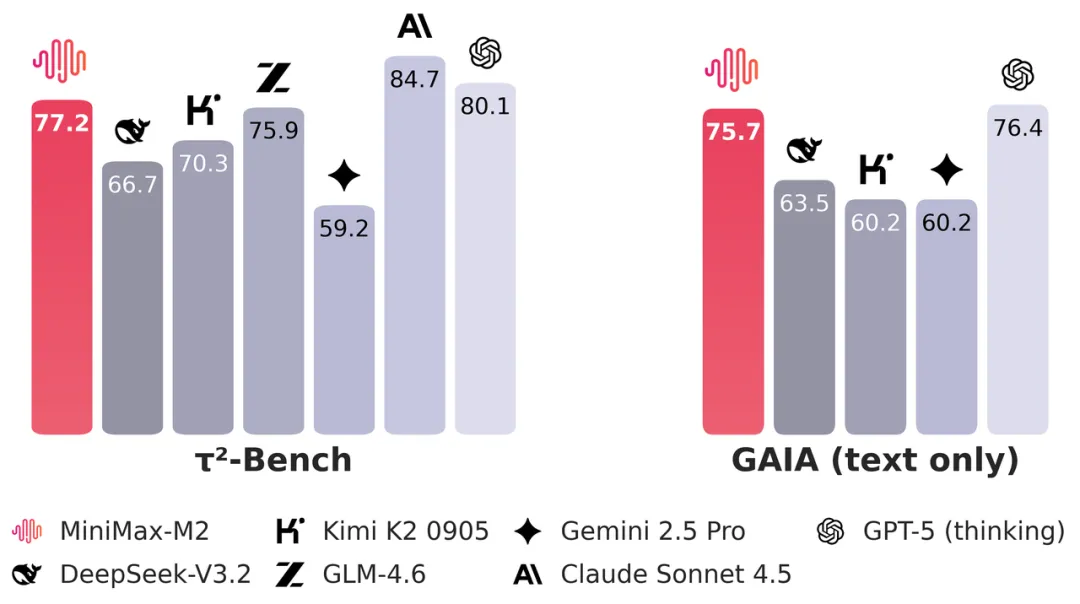
具体来看,在τ²-Bench-Telecom(代理工具使用)的测试中,M2 的成绩与 GPT-5 并列第二, 仅以微弱差距落后于 GPT-5 Codex;其 IFBench(指令遵循能力)的表现接近 GPT-5 系列水平,显著高于其他顶尖模型;LiveCodeBench(编程能力)同样表现强劲,甚至超过了以编程能力见长的 Claude Sonnet 4.5。
可以发现,在综合性能稳居于行业前列的基础上,MiniMax-M2 最大的亮点,就是 Coding 与 Agentic 能力,称其“专为编码和智能体而生”名副其实。
近期全球头部厂商的动作也印证了编码和智能体的重要性。9 月底,Anthropic 直接将新推出的 Claude Sonnet 4.5 定位为“世界上最强的编程模型”,明确强化其编码能力;10 月初,OpenAI 在开发者大会上发布的 GPT-5 Pro,将精准编码与智能体构建作为核心升级方向,配套的 Codex 工具还实现了与主流开发环境的深度集成。
在编码任务上,MiniMax-M2 具备强大的端到端开发能力,能应对多代码文件处理需求,完成 “编码 - 运行 - 调试” 的完整流程,还能通过测试验证来自动修复代码。
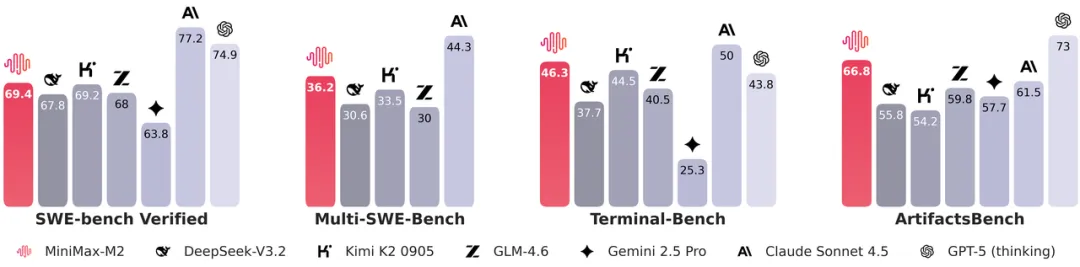
在 SWE-bench、Terminal-Bench 等模拟开发者真实工作流的测试中,与包括 Claude Sonnet 4.5、GPT-5(thinking)等在内的多款顶尖模型相比,MiniMax-M2 表现突出,超过 Gemini 2.5 Pro、DeepSeekV3.2、GLM-4.6 等。
在智能体能力上,MiniMax-M2 能够出色规划并执行复杂的工具链,协同调用 Shell、浏览器、Python 代码执行器和各种 MCP 工具,高效完成多步骤任务。
在 BrowseComp 评测中,M2 的表现位居一众头部模型前列,进一步凸显竞争力。它不仅可以挖掘到常规模型难以定位的信息源并保持来源可追溯,还具备自我纠错与任务恢复的能力。
此外,MiniMax-M2 的深度搜索能力也足够亮眼。不仅在 BrowseComp 上取得出色成绩,更在 Xbench-DeepSearch 基准上全球前二、仅次于 GPT-5,在字节新推出的金融搜索基准 FinSearchComp-global 上全球前二、仅次于 Grok4。
作为轻量级模型,M2 上下文能力也保持强势,输入长度达到 200k,输出长度可达 128k,在长文本处理、复杂推理等任务处理方面更具实用性。
既要顶尖性能,也要极致性价比
尽管大模型行业整体正在迈入更加务实的阶段,但仍普遍面临着性能和价格难以平衡的挑战。
以同样擅长编程和智能体能力的 GPT-5 和 Claude 4.5 Sonnet 为例,二者虽能在复杂代码开发、多工具协同任务中展现出顶尖性能,但高昂的使用成本,让多数开发者甚至中小企业都望而却步。国内的同类模型价格虽然相对便宜,但是性能和推理速度却不尽人意。
正是在这样的行业矛盾下,MiniMax-M2 的定位尤为关键,作为一款轻量、快速且极具成本效益的模型,主打全球最高性价比与极致速度,恰好切中了市场对智能普惠的广泛需求。
为了实现这一目标,在保持核心性能竞争力的同时,MiniMax 通过底层架构优化、算法创新等技术手段,将 M2 的综合成本大幅压低。
反映在具体定价上,M2 也具有压倒性优势:每百万 token 输入价格为 $0.3(约 2.1 元),输出价格为 $1.2(约 8.4 元)。这个价格仅为国际头部模型 Claude Sonnet 4.5 的 8%、GPT-5 的 15%,也显著低于国内模型 K2、GLM4.6 等,可以说是当前全球范围内性价比最高的模型。
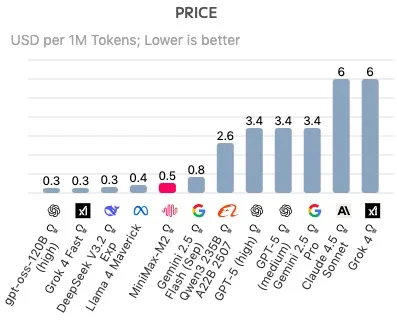
更重要的是,MiniMax-M2 的性价比优势并非以牺牲使用体验为代价,其极速响应能力进一步放大了产品的实用价值。约 100 TPS 的推理速度,比 Claude Sonnet 4.5 快了接近一倍,且还在持续提速。
在发布 MiniMax-M2 的同时,MiniMax 也同步完成了 Agent 产品的升级,不仅将 M2 接入 MiniMax Agent,把顶级的编程、工具调用、多模态理解与任务执行能力整合到一起,还通过优化降低了响应延迟、提升了吞吐量,对于在实际业务中的应用至关重要。
MiniMax Agent 提供两种模式:一类是 pro 专业模式,主打专业 Agent 能力;另一类是 lightning 高效模式,属于高效极速版 Agent,可实现极速输出。
除了核心能力升级,MiniMax 首次推出了 MiniMax Agent 的安卓与 iOS APP 版本,让用户可以通过移动端随时调用 Agent 功能,进一步降低了使用门槛。
在实际应用中,可以直观感受到 M2 在编程和工具调用能力上的优势得到了进一步放大。
比如直接在 MiniMax Agent 平台上,开发一个 AI 音乐 playlist 网站,AI 音乐和背景视频都由模型生成。
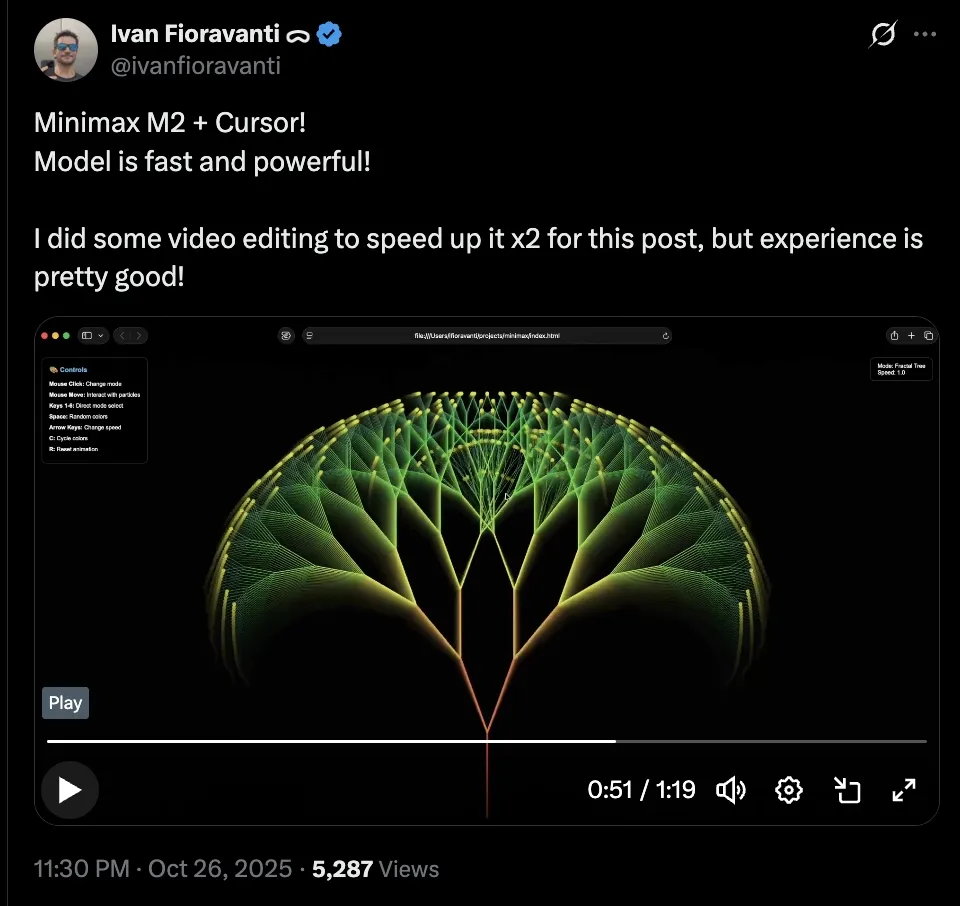
在海外,也有开发者展示了自己调用 API 在 Cursor 上体验 MiniMax-M2 的成果,可以说效果非常不错。
值得关注的是,MiniMax 此次还同步推出了“Agent 和模型全球限时免费”活动。同时 MiniMax 继续保持开放的态度,开源 M2 模型权重已开源,可以本地部署使用,通过社区力量加速模型进化。
这种“技术普惠”策略,让全球不同规模、不同行业的用户都能零成本体验顶尖 AI 能力,实现了全球范围内首次“让最领先的代码能力与 Agentic 能力被大规模畅快使用”。
全模态领先背后,硬实力和普惠初心缺一不可
随着大模型逐步成为行业基础设施,模型的性能顶尖和极致性价比是竞争关键。而对于大模型企业来说,更重要的是通过全模态多元能力的构建,提供端到端的完整智能体验。
目前,MiniMax 已构建起全栈领先的多模态矩阵,各模态模型在国际权威测评中均表现突出。其中,音频模型 Speech-02 登顶全球第一,视频模型 Hailuo 02 斩获全球第二,文本模型 M2 则跻身全球前五。可以看出,这三大模态相互协同、形成共振,构筑起 MiniMax 独特的技术壁垒。
而这种全栈领先的局面并非偶然。从模型性能到产品体验,从成本控制到生态落地,MiniMax 展现的多维度优势,本质上是其整体技术实力的集中体现。根源在于 MiniMax 在底层架构与算法层面的持续创新与突破,正是底层技术的不断打磨,才支撑起各模态模型的高性能表现。
在底层架构层面,MiniMax 善于颠覆经典,从传统 Transformer 架构出发,在国内率先采用大规模混合架构(MoE),让模型能够在处理复杂任务是拥有更大参数量,保证性能的同时兼顾计算效率。
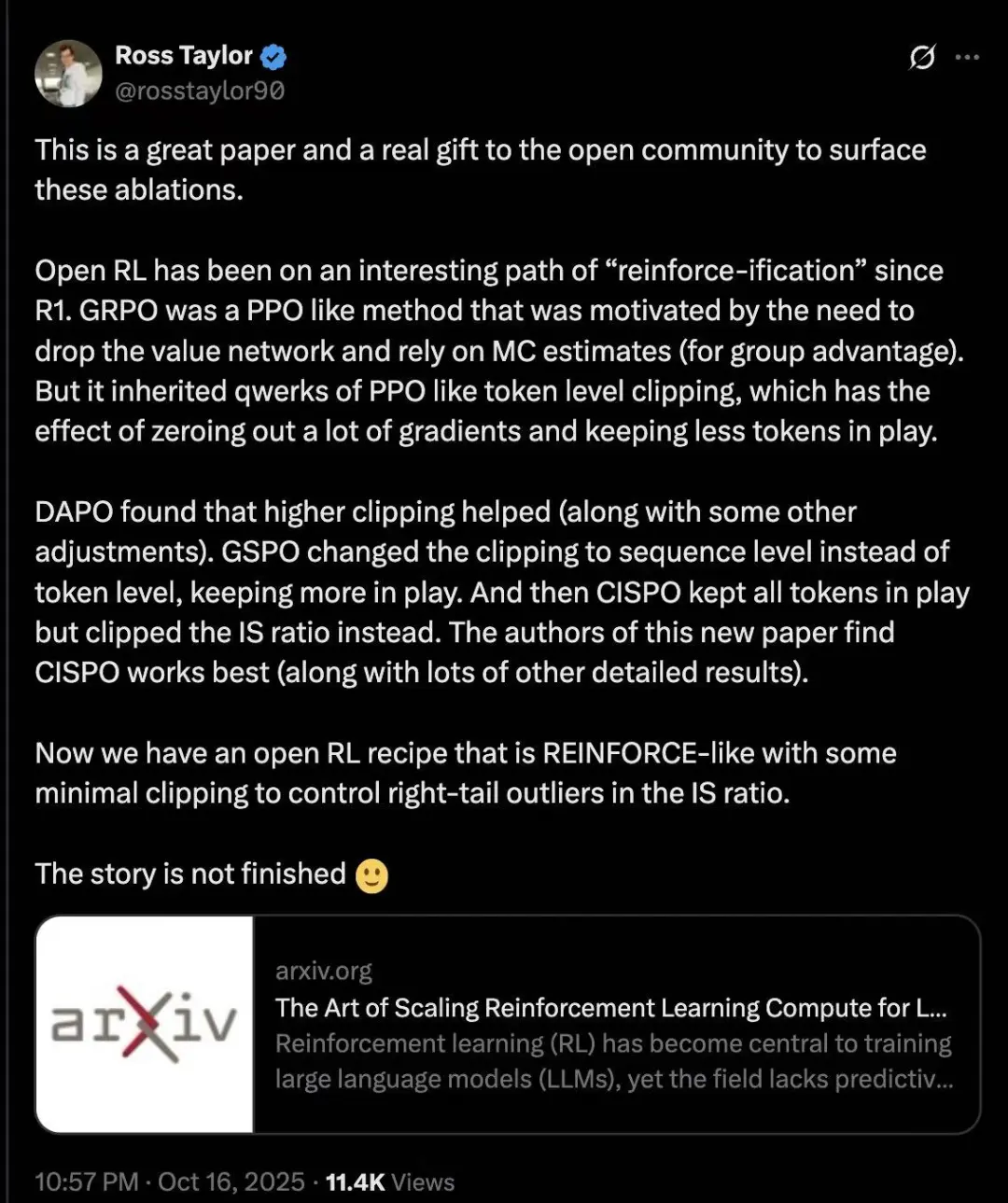
在架构创新的基础上,MiniMax 在算法层面的突破同样关键,其创新提出的强化学习算法 CISPO,让训练效率与稳定性都得到了显著提升,明显提高训练和推理一致性。这项算法也被硅谷 AI 巨头 Meta 在最新发布的强化学习(RL)论文中验证,并被推荐为首选的 Loss Function。
实际上,从 DeepSeek V3 的 GRPO 到 MiniMax 的 CISPO,中国 AI 团队正以持续的技术创新,在大模型关键领域实现突破并引领发展。这一系列成果不仅夯实了中国科技领域的竞争力,更为中国 AI 技术未来参与国际标准制定奠定了坚实基础。
而支撑这一切技术探索的,是 MiniMax 从未动摇的智能普惠初心。这也意味着 MiniMax 更懂行业需求,能将技术优势转化为用户可感知的实用价值,其对“Intelligence with Everyone”理念的坚守,必将收获更多回响。




