
本文最初发布于 Mayank Sharma 的个人博客。
缓存是一种很强大的技术,广泛应用于计算机系统的各个方面,包括高速缓存硬件、操作系统、Web 浏览器,特别是后端开发。对于像 Meta 这样的公司来说,缓存非常重要,因为它可以帮助他们减少延迟,扩展繁重的工作负载,并节省资金。由于他们的场景中大量使用了缓存,所以他们遇到了另一个问题:缓存失效。
过去这些年,Meta 已经将他们的缓存一致性从 99.9999(6 个 9)提高到了 99.99999999(10 个 9)。也就是说,在他们的缓存集群中,每 100 亿次缓存写入操作中只有不到 1 次不一致。
本文主要包含以下内容:
什么是缓存失效和缓存一致性?
为什么 Meta 如何重视缓存一致性,甚至 6 个 9 都无法满足他们?
Meta 的监控系统如何帮助他们改进缓存失效和缓存一致性并修复 Bug?
缓存失效和缓存一致性
根据定义,缓存并不是真实的数据源。因此,当真实数据源中的数据发生变化时,应该有一个主动失效过期缓存项的过程。在这个过程中,如果处理不当,则缓存中可能会无限期地保留与真实数据源不一致的值。
那么我们该如何失效缓存?
我们可以使用 TTL 来保持缓存的新鲜度,这样任何其他系统都不会引发缓存失效。但是,在本文中,我们将讨论 Meta 的缓存一致性。我们假设,失效操作是由缓存之外的其他东西执行的。
首先,我们看下缓存不一致是如何产生的:
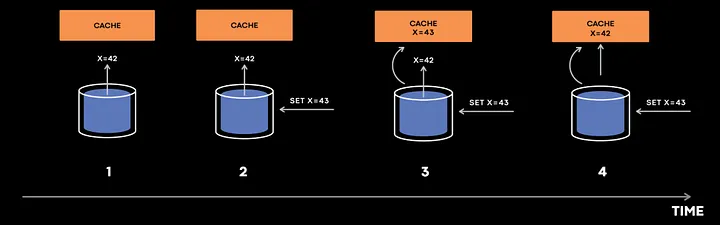
假设 1、2、3、4 是一个递增的时间序列:
首先,缓存填入来自数据库的值。
但是,在值 x =42 到达缓存之前,某个操作在数据库中将该值更新为 x=43。
为此,数据库发送了 x=43 的缓存失效事件,而且该事件在 x=42 之前到达,那么缓存值将设为 43。
现在,x =42 事件到达,缓存被设置成 42,于是不一致就产生了。
为了解决这个问题,我们可以使用一个 version 字段来执行冲突解决,使旧版本永远都不会覆盖当前版本。这种解决方案适用于几乎 99%的互联网公司,但对于 Meta 这么复杂的系统,这可能还不够。
为什么 Meta 如此重视缓存一致性?
从 Meta 的角度来看,缓存不一致几乎和数据库中丢失数据一样糟糕。从用户的角度来看,那可能会导致非常糟糕的用户体验。
当你在 Instagram 上向一个用户发送私信时,在后台,这些消息会存储在主存中,并且会生成用户到主存的映射。
假如有三个用户:Bob、Mary 和 Alice。Bob 和 Mary 都向 Alice 发送消息。Bob 在美国,Alice 在欧洲,而 Mary 在日本。因此,系统会查询离用户居住地最近的区域,并将消息发送到 Alice 数据存储。在这种情况下,当 TAO 副本查询 BOB 和 Mary 所在的区域(都包含不一致的数据)时,它就会将消息发送到没有 Alice 消息的区域。

上述情况会导致信息丢失和糟糕的用户体验。因此,这是 Meta 需要首先解决的问题之一。
监控
要解决缓存失效和缓存一致性问题,第一步是度量。要能够准确地度量缓存一致性,并在缓存中出现不一致条目时发出预警。而且,还要确保度量结果中不包含任何误报,因为如果值班工程师学会了忽略它,度量将失去信任并变得毫无价值。
抛开 Meta 的实际解决方案,最简单的解决方案是通过状态记录和跟踪每次缓存更改。在工作负载比较小的情况下,这种解决方案是可行的,但 Meta 的系统每天要进行超过 10 万亿次的缓存填充。记录和跟踪所有缓存的状态会把本已繁重的缓存负载变成异常繁重的工作负载,甚至都不用考虑还要对其进行调试。
Polaris
Polaris 是在一个非常高的层次上作为客户端与一个有状态的服务进行交互,它并不了解服务的内部机制。Polaris 遵循的基本原则是“缓存最终应该与数据库保持一致”。在接收到失效事件时,Polaris 会查询所有副本以验证是否有任何其他违规操作发生。例如:如果 Polaris 收到一个失效事件(x=4 @ version 4),那么它将作为客户端检查所有缓存副本以验证是否有违规的情况。如果有一个副本返回(x=3 @ version 3),那么 Polaris 会将其标记为不一致,并将其放入队列,以便稍后对照相同的目标缓存主机进行检查。Polaris 会报告特定时间范围内的不一致,如 1 分钟、5 分钟或 10 分钟。
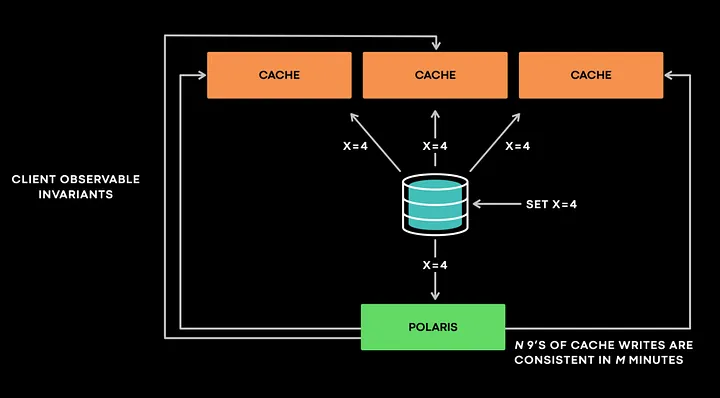
这种多个时间范围的设计不仅让 Polaris 可以使用多个队列来有效地实现回退和重试,而且对于防止误报也是必不可少的。
为了加深理解,我们再看个例子。
假如 Polaris 接收到(x = 4 @ version 4)的失效消息。但是当 Polaris 检查缓存时,却找不到 x 的数据条目,它应该将此标记为不一致。这种情况下有两种可能。
版本 3 的 x 不可见,而版本 4 是对该键的最新写入,这确实是一个缓存不一致。可能是版本 5 的写入操作删除了键 x,而 Polaris 也许只看到了比失效事件中的数据更新的视图。
我们怎么才能确切地知道这两种情况中哪一种是正确的?
对于这两种情况,Polaris 需要通过查询数据库进行查验。绕过缓存的查询可能是计算密集型的,并且还可能使数据库暴露于风险中,因为保护数据库和扩展读取量大的工作负载是缓存最常见的两个用例。所以,我们不能向系统发送太多的查询。
为了解决这个问题,Polaris 会延迟执行此类检查,并在不一致的样本超过设置的阈值(比如 1 分钟或 5 分钟)时才发起数据库调用。Polaris 给出的指标是“在 M 分钟内 N 个 9 的缓存写入是一致的”。所以现在,Polaris 提供了一个指标:在 5 分钟内 99.99999999 的缓存是一致的。
现在,让我们通过一个代码示例来看下 Polaris 如何帮助 Meta 解决了一个 Bug。这个例子是关于缓存不一致是如何产生的。
让我们通过以下的示例代码来看下这个过程。
假设缓存维护了一个键到元数据的映射和一个键到版本的映射。
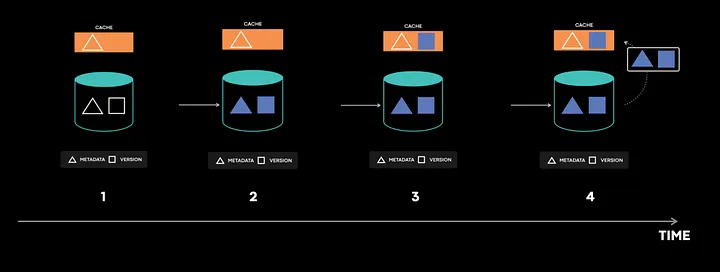
cache_data = {}cache_version = {}meta_data_table = {"1": 42}version_table = {"1": 4}当接收到读取请求时,会首先检查缓存中的值,如果值不在缓存中,就从数据库返回这个值。
def read_value(key): value = read_value_from_cache(key) if value is not None: return value else: return meta_data_table[key]def read_value_from_cache(key): if key in cache_data: return cache_data[key] else: fill_cache_thread = threading.Thread(target=fill_cache(key)) fill_cache_thread.start() return None缓存返回结果 None,并利用数据库返回的值填充缓存。我这里利用线程异步实现了这个过程。
def fill_cache(key): fill_cache_metadata(key) fill_cache_version(key)def fill_cache_metadata(key): meta_data = meta_data_table[key] print("Filling cache meta data for", meta_data) cache_data[key] = meta_data def fill_cache_version(key): time.sleep(2) version = version_table[key] print("Filling cache version data for", version) cache_version[key] = version def write_value(key, value): version = 1 if key in version_table: version = version_table[key] version = version + 1 write_in_databse_transactionally(key, value, version) time.sleep(3) invalidate_cache(key, value, version) def write_in_databse_transactionally(key, data, version): meta_data_table[key] = data version_table[key] = version与此同时,当版本数据被填充到缓存中时,数据库又有新的写入请求更新了元数据值和版本值。这看起来像是一个 Bug,但它不是,因为缓存失效应该把缓存带回到与数据库一致的状态。(注意:为了重现这个问题,我在缓存和数据库写入函数中加了 time.sleep)。
def invalidate_cache(key, metadata, version): try: cache_data = cache_data[key][value] ## To produce error except: drop_cache(key, version) def drop_cache(key, version): cache_version_value = cache_version[key] if version > cache_version_value: cache_data.pop(key) cache_version.pop(key)read_thread = threading.Thread(target=read_value, args=("1"))write_thread = threading.Thread(target=write_value, args=("1",43))print_thread = threading.Thread(target=print_values)然后,在缓存失效期间,由于某种原因,失效失败,在这种情况下,异常处理程序将删除缓存。
删除缓存函数的逻辑是最新版本大于 cache_version_value 则删除键,但我们不是这样做的。因此,这会导致过时的元数据无限期地驻留在缓存中。
还请注意,这个例子只是简单地说明下 Bug 可能如何发生,实际的 Bug 会复杂得多,会涉及数据库复制和跨区域通信。只有当上述所有步骤都发生,并且按照这个特定的顺序发生时,才会触发 Bug。不一致的情况很少出现。Bug 隐藏在交错操作和瞬态错误后的错误处理代码中
一致性跟踪
假如你在值班,你收到了 Polaris 报告的缓存不一致信息,你首先要做的是检查日志,看看问题可能出在哪里。正如我们前面所讨论过的,记录缓存数据的每个更改几乎是不可能的,但是如果我们只记录可能导致更改的更改呢?
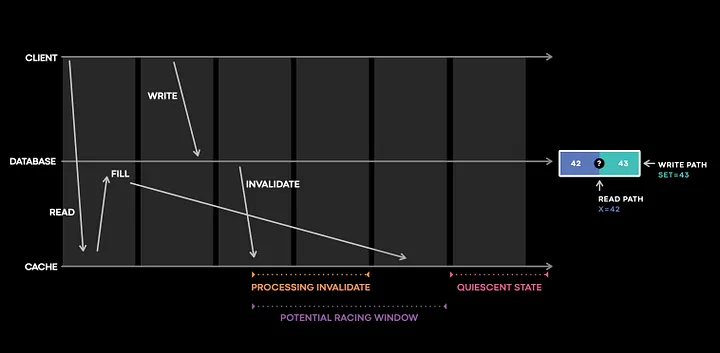
在上面的代码中,如果缓存没有接收到失效事件或失效失败,就会出现问题。作为值班人员,我们需要检查以下内容:
缓存服务器接收到失效事件了吗?
服务器正确处理失效了吗?
该数据项后来不一致了吗?
Meta 已经构建了一个有状态的跟踪库,在这个紫色的小窗口中记录和跟踪缓存变化,其中包含所有触发 Bug 导致缓存不一致的奇怪而复杂的交互。
小结
对于任何分布式系统,可靠的监控和日志系统都是必不可少的,那可以确保我们捕获错误并快速找到根本原因,从而缓解问题。在 Meta 的例子中,Polaris 发现了异常并立即发出了警报。借助一致性追踪信息,值班工程师只用了不到 30 分钟就定位了问题。
原文链接:




