
过去半年,大模型赛道出现了一个明显的拐点:模型尺寸已经不再是唯一卖点,“推理能力”成了新的分水岭。从 OpenAI o1 发布,首次将推理能力作为模型的重要特点,到春节期间引爆社区讨论的 DeepSeek-R1,推理能力已成为“新赛点”,全球主流厂商几乎在同一时间把“Reasoning”“Thinking”“Logic”写进了版本号。
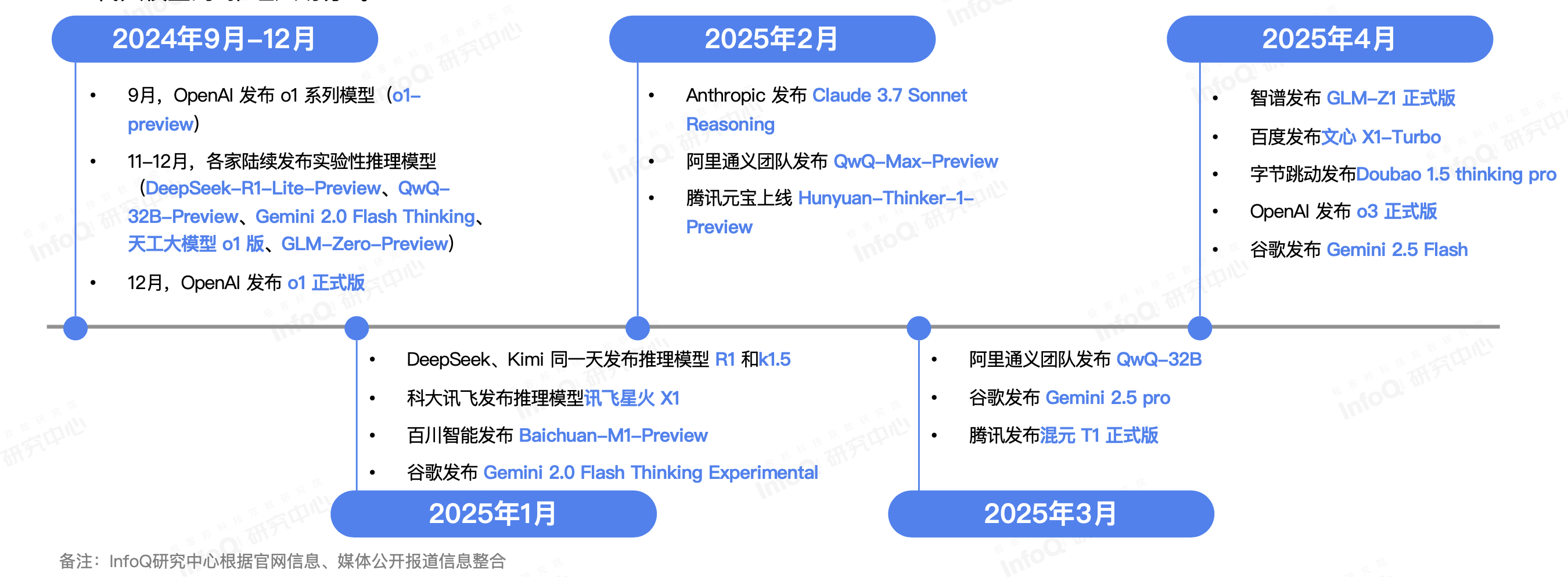
各家厂商推理模型发布时间轴
然而,市场上对模型的真实推理水平的把握依旧模糊。为此,InfoQ 研究中心发起了一次针对八款热门模型的系统性评测,希望为科研机构和产业团队提供一份既能读懂又能用得上的能力指南。更多内容也欢迎各位读者点击「链接」,下载完整报告进行阅读。
评测围绕逻辑推理、数学推理、语言推理、多步推理以及幻觉控制五大维度展开。300 道题库中包含超过 90%的原创试题,覆盖 3 个难度梯度、涵盖多学科和多题型,并确保评分可量化、难度分层合理。

推理模型综合测评体系说明
评测对象包括 DeepSeek-R1、k1.5、Claude-3.7-Sonnet-Reasoning、GLM-Z1、Doubao-1.5-thinking-pro、o3、文心 X1 Turbo 以及 Qwen3-235B-A22B。参与测试的推理模型、版本号及测试渠道如下。
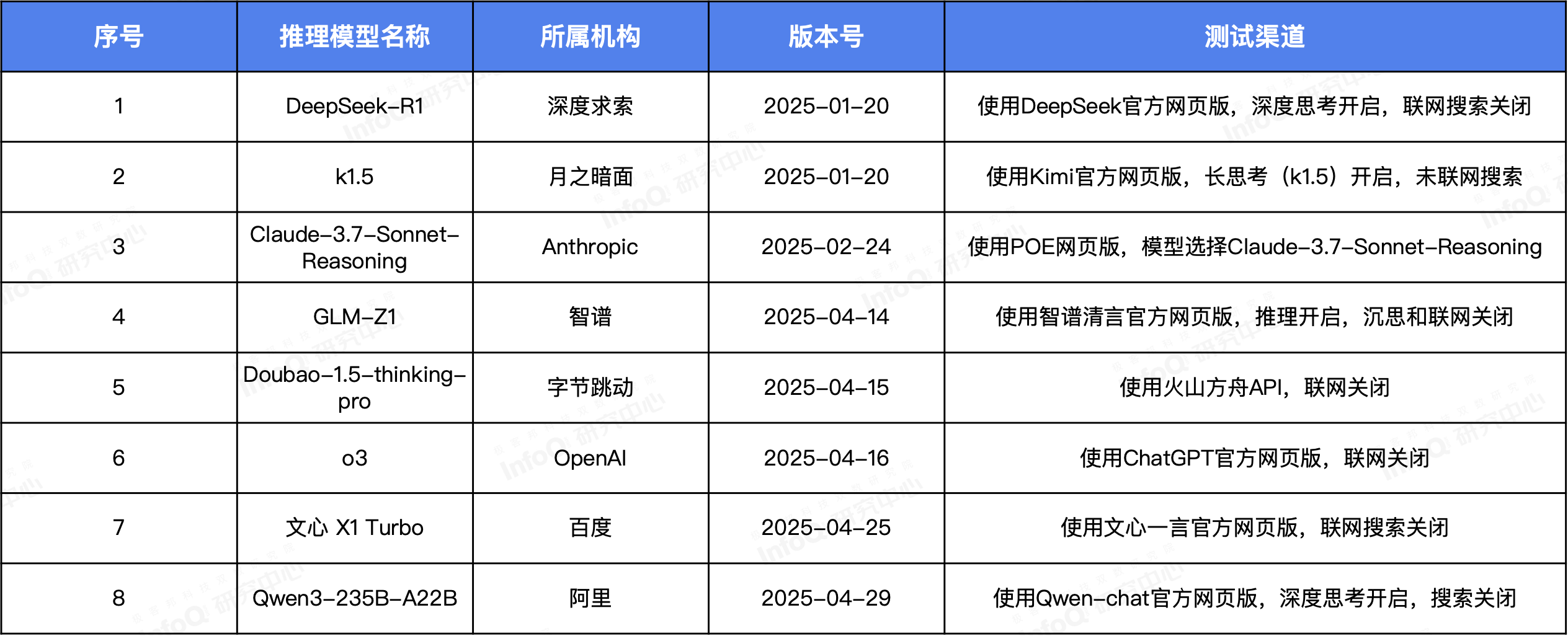
参与测评模型和版本说明
整体而言,八款模型在幻觉控制、数学推理和逻辑推理三个维度表现最为突出。相对地,多步推理依然是推理模型共同的短板。
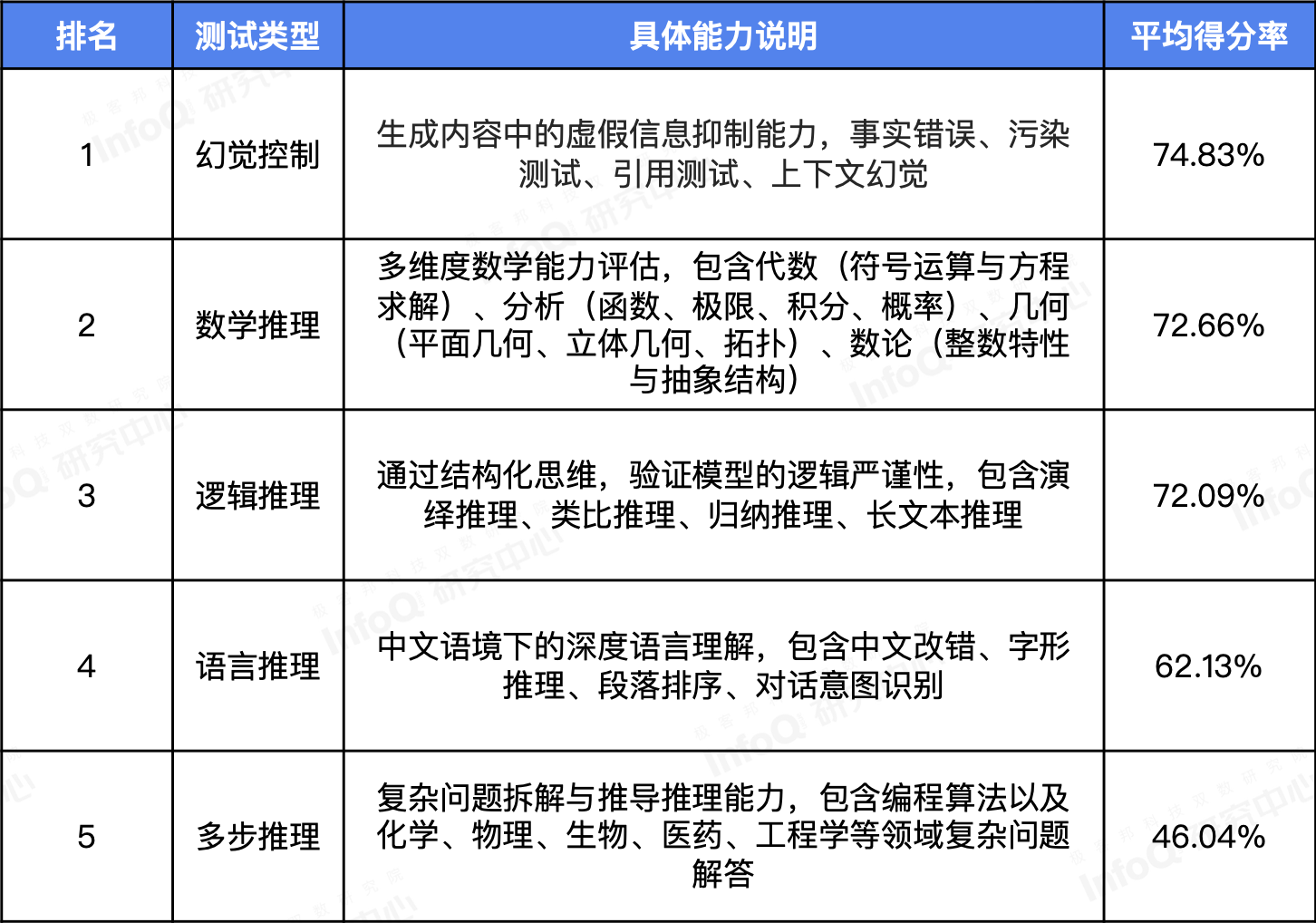
各评测维度推理模型平均得分率
在测试过程中,我们记录了推理模型的思考时长,我们在模型回答准确性和思考时长之间也发现了一些有趣的现象。例如,在数学推理维度,推理模型在面临以数字和符号为主的代数领域问题时,能够保障一定的回答准确性的同时,平均思考时长也较短,但来到涉及平面或空间几何结构的几何维度和更接近数学原理的数论时,平均准确率骤降至约六成,且推理耗时则翻了一倍。
复杂科学推理,涵盖了化学、物理、生物医药和工程学等跨学科的综合难题。推理模型虽然尝试进行了更长时间的思考(平均思考时长超过 200 秒),但整体回答准确性仅在 20%左右,是所有维度中平均思考四件最长,但准确性最低的子维度。
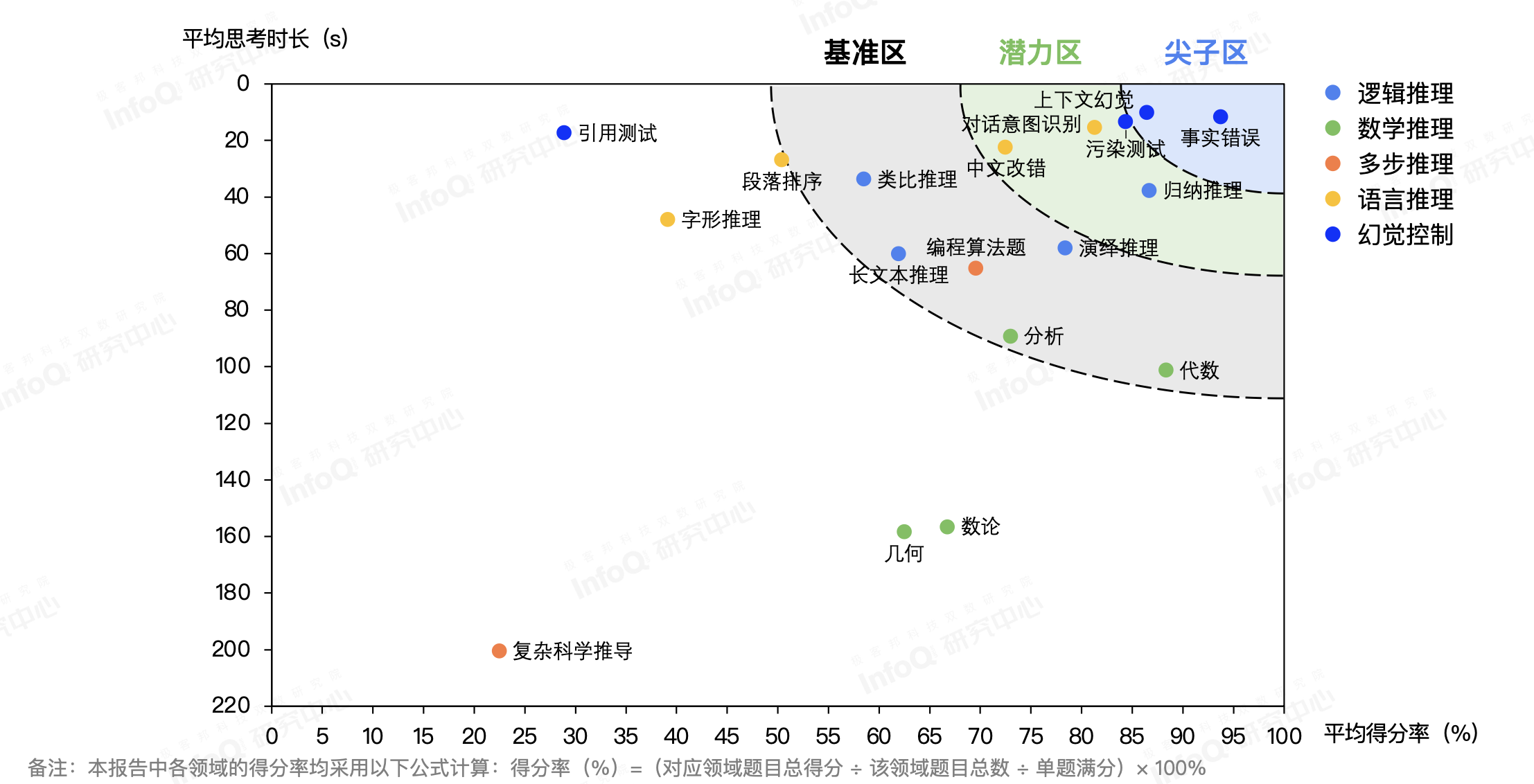
推理模型各子维度平均得分率和平均思考时间矩阵
在语言推理方面,我们也很惊喜地发现,已经有部分模型萌生了对汉字的左右、上下、包围等字形结构的认知能力。在我们前期的一道测试题中,“口+勿能组成什么字?”,有部分模型不仅回答出了拥有常见结构的“吻”,还捕捉到了相对冷门的“囫”。
至于幻觉控制,虽然整体可控,但呈现出更隐蔽的特征:推理模型存在更大的概率提供包含虚构的数据、产品名称、论文名称、发布时间等看似充满逻辑性细节的回答,使非专业读者难以一眼识别错误。
当我们把焦点投向不同维度,各家推理模型的表现时,o3 在数学推理和多步推理两项位居榜首,文心 X1 Turbo 则在幻觉控制和语言推理两项位居第一,而 Qwen3-235B-A22B 在逻辑推理维度表现最佳。更多内容也欢迎各位读者点击「链接」,下载完整报告进行阅读。
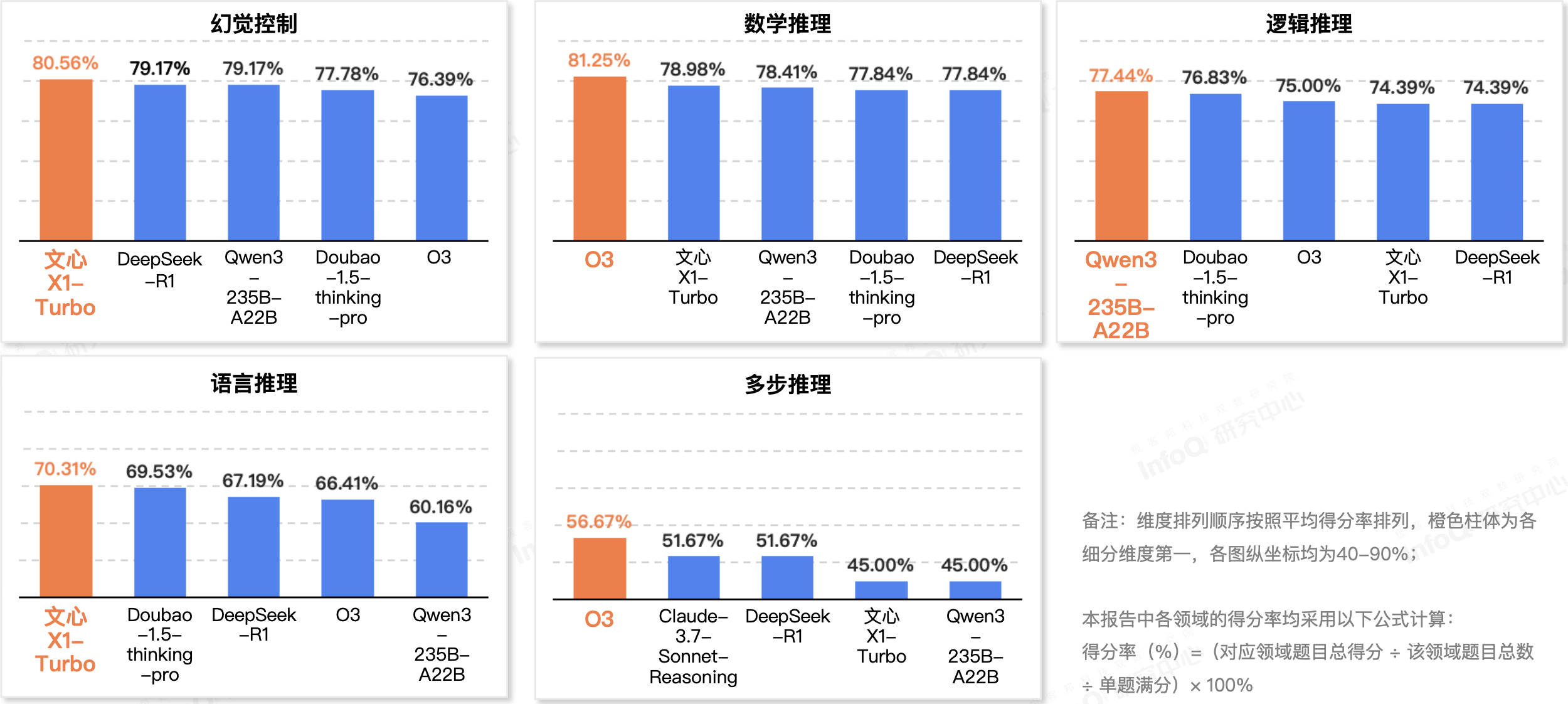
评测各维度 Top5 模型得分情况
除了数据上的表现外,近期推理模型的集中发布,也让推理模型的发展趋势变得更清晰。例如,视觉推理模型将图片融入了思维链;Claude 4 能够连续编程 7 小时,并修改多文件项目……这些变化共同指向一个趋势:推理模型正从“一个大脑”演变为“带工具的多能智能体”,其评测维度和应用边界都在同步扩展。
InfoQ 研究中心将持续跟踪多模态推理、Agent 框架、工具链整合以及安全对齐等方向的最新进展,并在后续报告中提供更细粒度的数据与案例分析。欢迎读者关注后续更新,与我们一同见证推理能力迈向下一阶段的真正拐点。




