
领英(LinkedIn)今天宣布了一个可扩展的日志存储系统Northguard,它取代了Kafka,以及一个虚拟化的Pub/Sub层Xinfra。Northguard 提供了分片数据和元数据、日志条带化、强一致性和自平衡集群,规模比 Kafka 更大,而 Xinfra 则实现了在 Kafka 和 Northguard 之间的无缝迁移和统一访问。
根据 LinkedIn 的工程师表示,Kafka在 LinkedIn 的规模下(每天 32T 记录、17PB 数据、400K 主题、150 个集群)变得越来越难以管理。Northguard 的架构由共享数据和元数据、去中心化协调和最小全局状态组成,消除了 Kafka 的单控制器和基于分区的限制。
Northguard 的数据模型将日志组织成记录、段、范围和主题。记录(键、值、头)被写入段——不可变的复制单元。段形成范围,代表连续的键空间切片,支持动态分割和合并,以实现扩展和排序。另一方面,主题是覆盖整个键空间的范围集合,具有灵活的存储策略,可用于复制和保留。
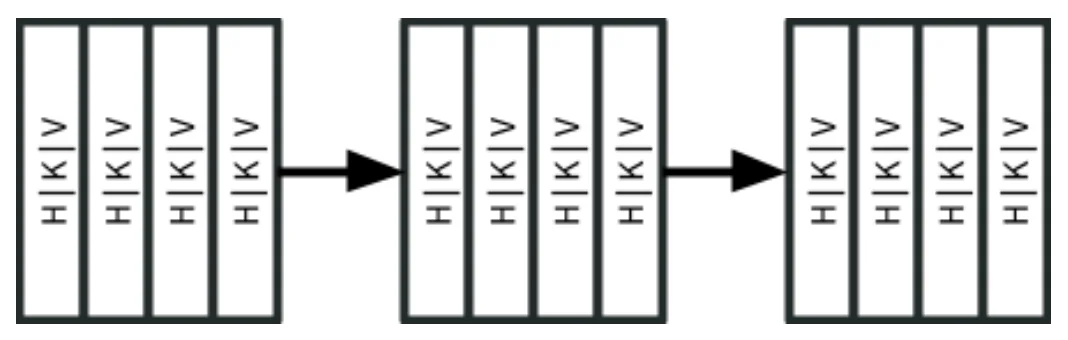
包含三个段的 Northguard 范围(来源)
这种细粒度结构实现了平衡负载、高可用性和无缝扩展。当生产者产生新的段时,代理自然会自我平衡,从而消除了在添加代理或代理失败时进行昂贵的重新平衡或数据移动的需求。
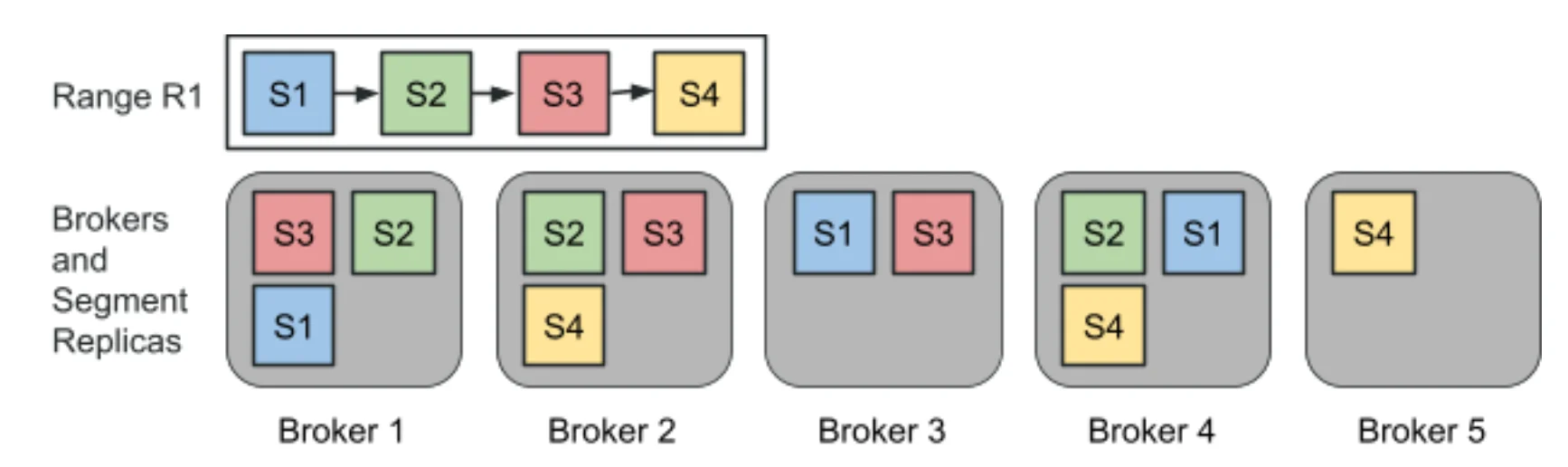
新段被添加到范围中,并被分配给可能的新代理(来源)
与传统的索引分区相比,范围提供了更灵活的扩展机制。范围分割只中断客户端对受影响范围(而不是整个主题)的写入,同时保持总排序保证。这种差异减少了中断,并避免了昂贵的“停止世界”同步。此外,跨主题对齐的范围通过减少对洗牌的需要来简化流处理连接。
Northguard 的元数据模型使用分片的、基于Raft的复制状态机(DS-RSM),分布在虚拟节点上。每个虚拟节点管理主题、范围和段的元数据——跟踪状态变化(例如,拆分、合并、密封)、副本集和保留策略。通过使用一致性哈希分片元数据和去中心化协调,Northguard 避免了 Kafka 的控制器瓶颈,并支持数百万副本的强一致性和高可用性。
LinkedIn 为性能和持久性优化了 Northguard 的协议。元数据操作(如创建、删除、查询)使用路由到虚拟节点领导者的单一请求/响应调用。生产、消费和复制流是带有管道和窗口的会话化流协议,以最大化吞吐量和最小化延迟。
生产者写入活跃的段领导者,只有在所有副本上fsync后才接收确认,确保强持久性。消费者使用带有客户端控制流的类似流模型,支持高效的高吞吐量读取。活动段复制和密封段复制利用相同的高效流架构,从而实现 Northguard 的高性能和自我修复能力。
在 LinkedIn 的规模上,从 Kafka 迁移到 Northguard 需要为数千个关键应用程序实现无缝、零停机转换。为了支持这一点,LinkedIn 构建了 Xinfra,一个虚拟化的 Pub/Sub 层,抽象了物理集群。Xinfra 通过双写机制使主题能够跨越 Kafka 和 Northguard,允许在不更改客户端的情况下进行实时迁移。
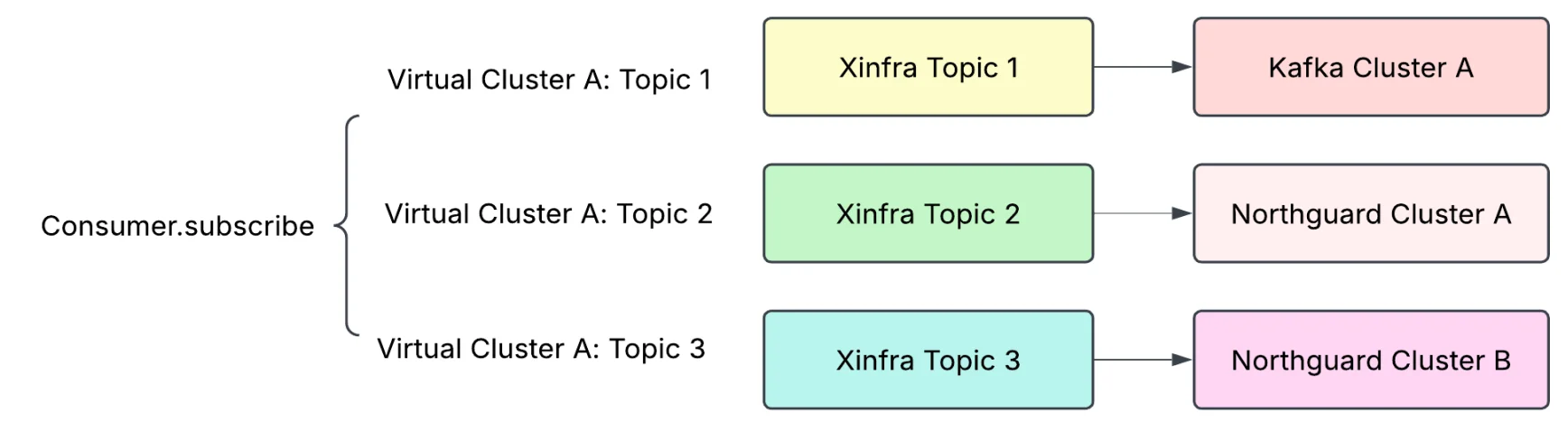
一个示例用例,其中消费者订阅了同一虚拟集群下的三个主题,每个主题位于不同的集群中(来源)
Northguard 中的分段存储是可插拔的,默认的“fps-store”实现针对持久性和延迟进行了优化。它使用提前写日志(write-ahead log, WAL),每个段创建一个文件,应用 Direct I/O 来绕过 OS 缓冲,并在RocksDB中维护一个稀疏索引。在几毫秒内刷新和跨副本同步成批记录,即使在故障情况下也能确保持久性。这种设计避免了缓存不一致,支持从旧段中高效读取,并允许随着集群的增长而预测性能。
为了确保大规模的可靠性,Northguard 在确定性模拟下进行了严格的测试。整个集群和客户端在单线程的受控环境中运行,在这种环境中,故障(如代理关闭、网络分区、磁盘错误和滚动升级)会被注入和重放。这种方法允许 LinkedIn 每天模拟多年的活动,及早捕捉边缘情况,并在复杂的故障场景下持续验证正确性。
LinkedIn 的工程师表示,他们“已经成功地将数千个主题从 Kafka 迁移到 Northguard,每天处理数万亿条记录”,并且 LinkedIn 超过 90%的应用程序已经在运行 Xinfra 客户端了。
InfoQ 联系了 LinkedIn,希望将 Northguard 和 Xinfra 开源。LinkedIn 表示,他们“专注于在我们内部系统中完成 Northguard 和 Xinfra 的实施,并且随着我们继续构建、学习和迭代这些工具,我们将探索开源它们的可能性。”
原文链接:
https://www.infoq.com/news/2025/06/linkedin-northguard-xinfra/




