
作者 | 梁朝东,刘庆,杜炜,樊军伟,赵玉萍
在快速发展的生成式 AI 浪潮中,大语言模型推理是一个主流的工作负载,众多云服务提供商都致力于提供实时高效的大语言模型推理服务。青云 QingCloud 已经基于第四代英特尔®至强® 可扩展处理器和 BigDL-LLM 大语言模型推理方案开发并上线了实时低延迟的大语言模型推理服务。本文介绍了青云 AI 在线推理服务,以及其中应用到的大语言模型技术和优化。
青云 AI 在线推理服务
青云科技近期推出了青云模型市场试用版,此试用版目前已基于青云已有的应用市场扩展了“大模型”分类,支持了众多国内外开源模型,如 ChatGLM3、Baichuan2、LLaMA2 等。其中,青云 AI 在线推理服务(公测版)构建在模型市场上,用户可使用开源模型,或者自行上传私有模型镜像,使用简单步骤即可实现快速大模型应用的部署。
青云 AI 在线推理服务运行于基于第四代英特尔®至强® 可扩展服务器的青云 E4 云主机,采用了基于英特尔 BigDL-LLM 的大语言模型推理的运行时(runtime),支持实时低延迟大语言模型推理。目前该服务已上线,用户访问青云网站即可体验大语言模型的高效在线推理服务。
“青云 AI 在线推理”的访问界面如下所示:
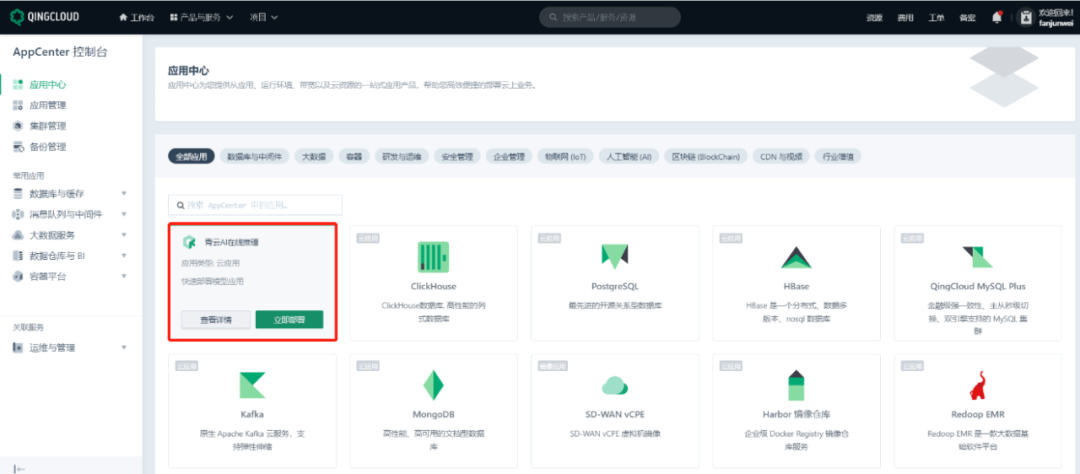
用户登陆青云公有云,进入 AppCenter 控制台,选择“青云 AI 在线推理”。按照页面提示的步骤开始创建服务,在基本配置选项中,选择 intel-runtime,即可创建带有 AMX 特性的青云 E4 云主机,并可指定由 BigDL-LLM 提供低延迟推理能力。
经过服务器配置(推荐使用 16 核 32GB 内存的青云实例),网络配置(VPC 网络),服务环境配置(配置镜像仓库等)等步骤,即可以提交进行服务部署。如果成功部署,则可以看到 AI 在线推理服务的节点状态为“活跃”,服务状态为“正常”。
通过青云负载均衡器提供的公网 IP,可以在浏览器访问部署成功的 “青云 AI 在线推理服务”,示例如下图所示。
BigDL-LLM 大语言模型推理和性能优化
青云 AI 在线推理服务运行在基于第四代英特尔®至强® 可扩展处理器的青云 E4 系列云主机。第四代英特尔® 至强® 可扩展处理器通过创新架构增加了每个时钟周期的指令,每个插槽多达 56 个核心,支持 8 通道 DDR5 内存,有效提升了内存带宽与速度。同时,英特尔® AMX 针对广泛的硬件和软件优化,通过提供矩阵类型的运算,为深度学习推理和训练提供显著的性能提升。
青云 AI 在线推理服务采用了 BigDL-LLM 作为大语言模型推理的运行时 (runtime)。BigDL-LLM 是英特尔开源的大语言模型库,能够在广泛的英特尔 XPU 上运行,如移动或桌面的 CPU/GPU、服务器 CPU/GPU,以及云端等设备,并提供了优化的性能表现。这一库支持对任何基于 PyTorch 的模型进行低比特优化,包括 FP4、INT4、NF4、FP8、INT8 、BF16、FP16 等多种数据类型,能显著降低内存占用并提供极低的访问延迟。
BigDL-LLM 提供的低比特模型优化技术是一种全面的解决方案,旨在降低大型模型的资源消耗。该技术包括模型量化和访存优化,同时对英特尔硬件进行了特定的优化措施,比如在 CPU 上应用 AVX2、AVX512、AMX 指令集,在 GPU 上则充分利用 XMX 计算单元。此外,BigDL-LLM 还借鉴并优化了多种业界先进的低比特技术,如 llama.cpp、bitsandbytes、qlora 等,并支持多种模型量化类型和策略,如对称 / 非对称量化、低比特类型(INT4、NF4、FP8)及策略(例如 GPTQ,AWQ, GGUF 等)。以 INT4 低比特优化为例,BigDL-LLM 将权重映射到 INT4 的整数空间时,会记录缩放系数,随后在推理过程中使用这个缩放系数恢复原先的权重,最大可能的保持了推理过程中的准确性。
这些技术显著减少了存储空间需求,降低了内存或显存的占用和访问压力,使得大语言模型的性能得到大幅度提升。同时,这些技术使得在显存较小的设备上运行大型模型成为可能,为资源受限的环境提供了强大的支持。
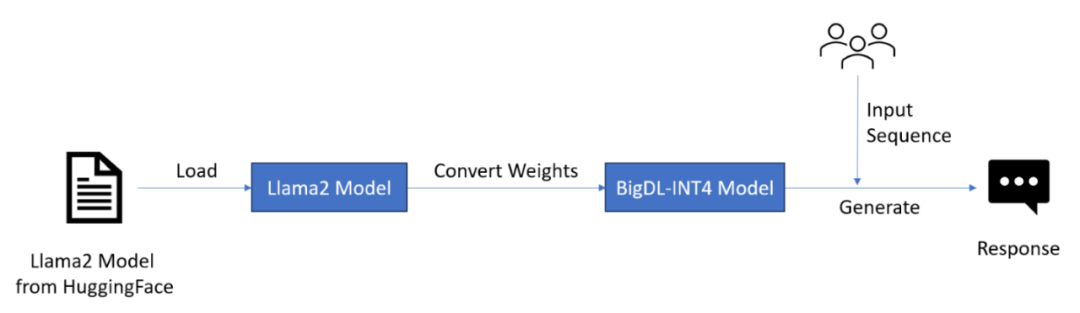
下图展示了 BigDL-LLM 进行 INT4 推理的主要步骤。用户通过 BigDL-LLM 提供的 Hugging Face Transformer API 将模型加载到内存中,在加载的同时,BigDL-LLM 通过低比特量化技术将模型的权重进行映射(比如将 FP16 的系数映射到 INT4 的整数空间),随后对用户提供的输入序列进行标准的推理工作。BigDL-LLM 支持用户使用熟悉的 Hugging Face Transformer API 进行推理工作。
同时,BigDL-LLM 也采纳了 vLLM 的设计,在解码阶段(decoding)实现了 continuous batching 的优化方案。这一优化能够极大的提高推理服务的吞吐量,并保持很低的延迟。BigDL-LLM 也提供了在英特尔 XPU 平台上的大语言模型微调方案。BigDL-LLM 实现了 QLoRA 微调技术,应用了低比特量化,分布式数据并行,高性能通信等优化,极大的降低了微调过程中对大量内存使用的需求。BigDL-LLM 的大语言模型微调方案在集群或者云环境中可以进行轻松的扩展。
用户可以使用 BigDL-LLM 创建和运行大语言模型应用,使用标准的 PyTorch API(例如 Hugging Face Transformers, LangChain 等)在英特尔的 XPU 硬件平台上进行大语言模型的推理和微调。BigDL-LLM 已经适配和验证了众多的业界主流大语言模型,包括 LLaMA/LLaMA2, ChatGLM2/ChatGLM3, Mixtral, Mistral, Falcon, MPT, Dolly/Dolly-v2, Bloom, StarCoder, Whisper, InternLM, Baichuan, QWen, MOSS 等等大语言模型。
青云在 E4 云主机和 BigDL-LLM 上测试和验证了十几个主流大语言模型,并进行了性能分析和评估。结果显示,基于英特尔软硬件的大语言模型推理服务可以满足实时,低延迟的性能要求。经过 BigDL-LLM 的量化和低比特性能优化后,Baichuan2 7B 等模型可以获得高达 7 倍的性能加速比。
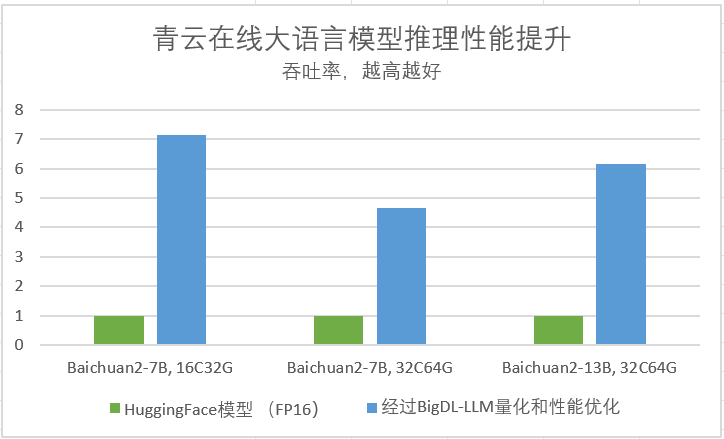
测试数据由青云提供。英特尔并不控制或审计第三方数据。请您审查该内容,咨询其他来源,并确认提及数据是否准确。
总结和展望
本文介绍了青云基于第四代英特尔®至强® 可扩展处理器发布的青云 AI 在线推理服务(公测版),以及其背后使用的大语言模型技术和优化。基于第四代英特尔®至强® 可扩展处理器和 BigDL-LLM 大语言模型方案,青云 AI 在线推理服务提供了业界领先的低延迟响应速度。青云还将继续深入探索大语言模型的更多使用场景,与英特尔持续密切合作,在更多英特尔硬件平台(例如第五代至强可扩展处理器等)上推出大语言模型推理的解决方案,同时不断扩展大语言模型的应用能力,提供例如模型微调等功能(基于 BigDL-LLM QLoRA),为用户提供更好的体验和更大的价值。
2024 年中,青云模型市场正式版将随青云 AI 智算平台新版本一起发布,为智算平台用户和开发者提供丰富的开源模型、数据集、模型管理、模型部署、模型推理等服务。
致谢
特别感谢英特尔刘芍君、史栋杰,青云王士郁、何颜廷对本文内容的贡献。




